 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTUA-SLP at SemEval-2018 Task 3: Tracking Ironic Tweets using Ensembles of Word and Character Level Attentive RNNs
Apr 18, 2018

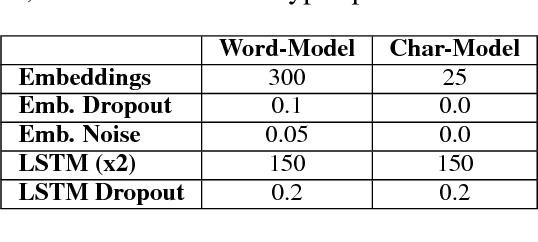
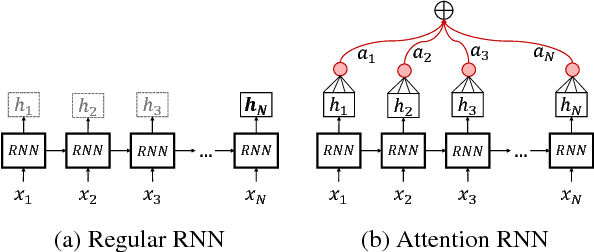
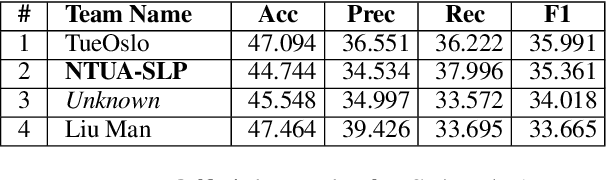
In this paper we present two deep-learning systems that competed at SemEval-2018 Task 3 "Irony detection in English tweets". We design and ensemble two independent models, based on recurrent neural networks (Bi-LSTM), which operate at the word and character level, in order to capture both the semantic and syntactic information in tweets. Our models are augmented with a self-attention mechanism, in order to identify the most informative words. The embedding layer of our word-level model is initialized with word2vec word embeddings, pretrained on a collection of 550 million English tweets. We did not utilize any handcrafted features, lexicons or external datasets as prior information and our models are trained end-to-end using back propagation on constrained data. Furthermore, we provide visualizations of tweets with annotations for the salient tokens of the attention layer that can help to interpret the inner workings of the proposed models. We ranked 2nd out of 42 teams in Subtask A and 2nd out of 31 teams in Subtask B. However, post-task-completion enhancements of our models achieve state-of-the-art results ranking 1st for both subtasks.
NTUA-SLP at SemEval-2018 Task 1: Predicting Affective Content in Tweets with Deep Attentive RNNs and Transfer Learning
Apr 18, 2018


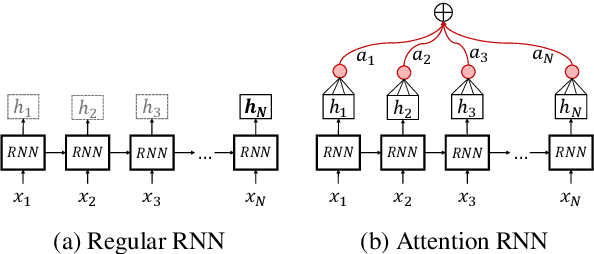
In this paper we present deep-learning models that submitted to the SemEval-2018 Task~1 competition: "Affect in Tweets". We participated in all subtasks for English tweets. We propose a Bi-LSTM architecture equipped with a multi-layer self attention mechanism. The attention mechanism improves the model performance and allows us to identify salient words in tweets, as well as gain insight into the models making them more interpretable. Our model utilizes a set of word2vec word embeddings trained on a large collection of 550 million Twitter messages, augmented by a set of word affective features. Due to the limited amount of task-specific training data, we opted for a transfer learning approach by pretraining the Bi-LSTMs on the dataset of Semeval 2017, Task 4A. The proposed approach ranked 1st in Subtask E "Multi-Label Emotion Classification", 2nd in Subtask A "Emotion Intensity Regression" and achieved competitive results in other subtasks.
NTUA-SLP at SemEval-2018 Task 2: Predicting Emojis using RNNs with Context-aware Attention
Apr 18, 2018

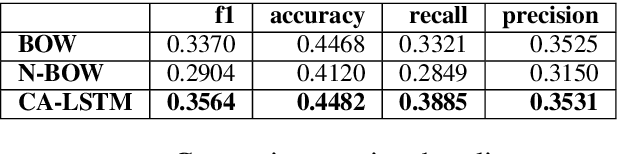
In this paper we present a deep-learning model that competed at SemEval-2018 Task 2 "Multilingual Emoji Prediction". We participated in subtask A, in which we are called to predict the most likely associated emoji in English tweets. The proposed architecture relies on a Long Short-Term Memory network, augmented with an attention mechanism, that conditions the weight of each word, on a "context vector" which is taken as the aggregation of a tweet's meaning. Moreover, we initialize the embedding layer of our model, with word2vec word embeddings, pretrained on a dataset of 550 million English tweets. Finally, our model does not rely on hand-crafted features or lexicons and is trained end-to-end with back-propagation. We ranked 2nd out of 48 teams.