 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteriorNet: Mega-scale Multi-sensor Photo-realistic Indoor Scenes Dataset
Sep 03, 2018
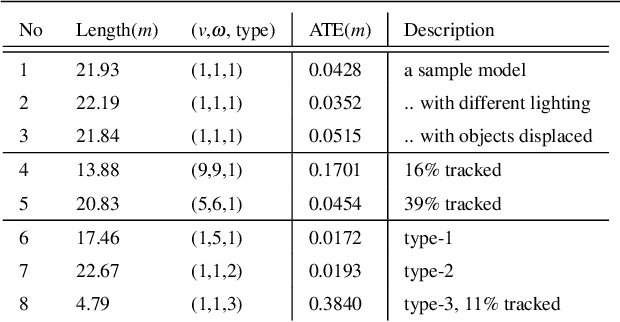

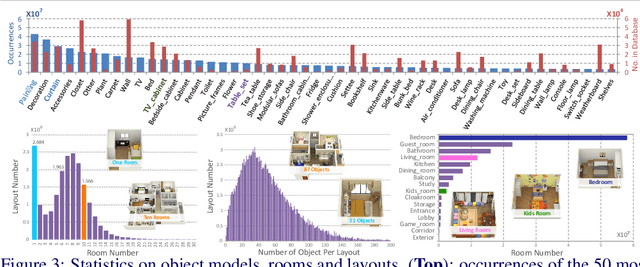
Datasets have gained an enormous amount of popularity in the computer vision community, from training and evaluation of Deep Learning-based methods to benchmarking Simultaneous Localization and Mapping (SLAM). Without a doubt, synthetic imagery bears a vast potential due to scalability in terms of amounts of data obtainable without tedious manual ground truth annotations or measurements. Here, we present a dataset with the aim of providing a higher degree of photo-realism, larger scale, more variability as well as serving a wider range of purposes compared to existing datasets. Our dataset leverages the availability of millions of professional interior designs and millions of production-level furniture and object assets -- all coming with fine geometric details and high-resolution texture. We render high-resolution and high frame-rate video sequences following realistic trajectories while supporting various camera types as well as providing inertial measurements. Together with the release of the dataset, we will make executable program of our interactive simulator software as well as our renderer available at https://interiornetdataset.github.io. To showcase the usability and uniqueness of our dataset, we show benchmarking results of both sparse and dense SLAM algorithms.
Fusion++: Volumetric Object-Level SLAM
Aug 28, 2018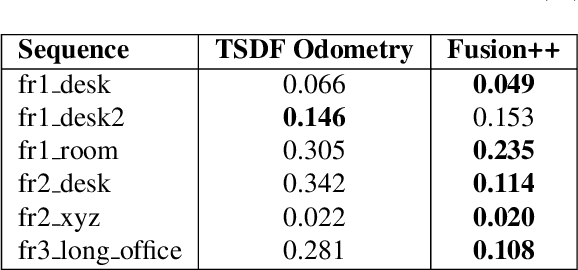

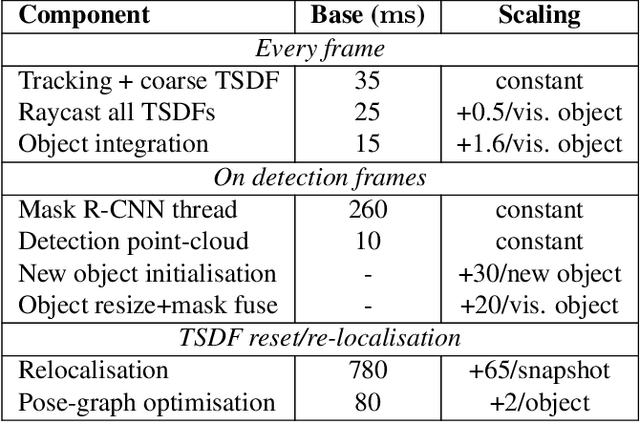
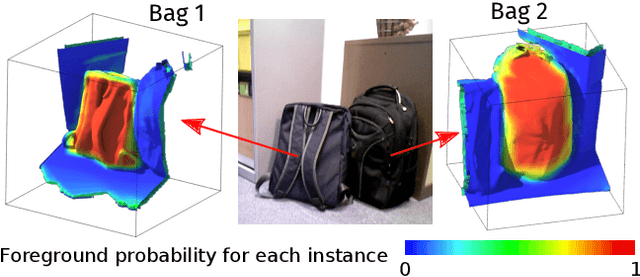
We propose an online object-level SLAM system which builds a persistent and accurate 3D graph map of arbitrary reconstructed objects. As an RGB-D camera browses a cluttered indoor scene, Mask-RCNN instance segmentations are used to initialise compact per-object Truncated Signed Distance Function (TSDF) reconstructions with object size-dependent resolutions and a novel 3D foreground mask. Reconstructed objects are stored in an optimisable 6DoF pose graph which is our only persistent map representation. Objects are incrementally refined via depth fusion, and are used for tracking, relocalisation and loop closure detection. Loop closures cause adjustments in the relative pose estimates of object instances, but no intra-object warping. Each object also carries semantic information which is refined over time and an existence probability to account for spurious instance predictions. We demonstrate our approach on a hand-held RGB-D sequence from a cluttered office scene with a large number and variety of object instances, highlighting how the system closes loops and makes good use of existing objects on repeated loops. We quantitatively evaluate the trajectory error of our system against a baseline approach on the RGB-D SLAM benchmark, and qualitatively compare reconstruction quality of discovered objects on the YCB video dataset. Performance evaluation shows our approach is highly memory efficient and runs online at 4-8Hz (excluding relocalisation) despite not being optimised at the software level.
SceneNet RGB-D: 5M Photorealistic Images of Synthetic Indoor Trajectories with Ground Truth
Jan 30, 2017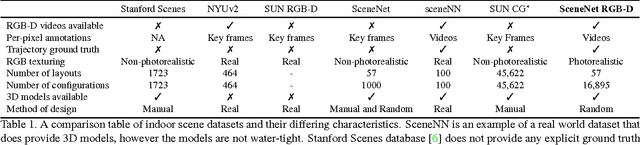


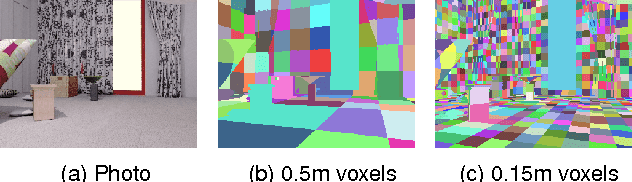
We introduce SceneNet RGB-D, expanding the previous work of SceneNet to enable large scale photorealistic rendering of indoor scene trajectories. It provides pixel-perfect ground truth for scene understanding problems such as semantic segmentation, instance segmentation, and object detection, and also for geometric computer vision problems such as optical flow, depth estimation, camera pose estimation, and 3D reconstruction. Random sampling permits virtually unlimited scene configurations, and here we provide a set of 5M rendered RGB-D images from over 15K trajectories in synthetic layouts with random but physically simulated object poses. Each layout also has random lighting, camera trajectories, and textures. The scale of this dataset is well suited for pre-training data-driven computer vision techniques from scratch with RGB-D inputs, which previously has been limited by relatively small labelled datasets in NYUv2 and SUN RGB-D. It also provides a basis for investigating 3D scene labelling tasks by providing perfect camera poses and depth data as proxy for a SLAM system. We host the dataset at http://robotvault.bitbucket.io/scenenet-rgbd.html
SemanticFusion: Dense 3D Semantic Mapping with Convolutional Neural Networks
Sep 28, 2016
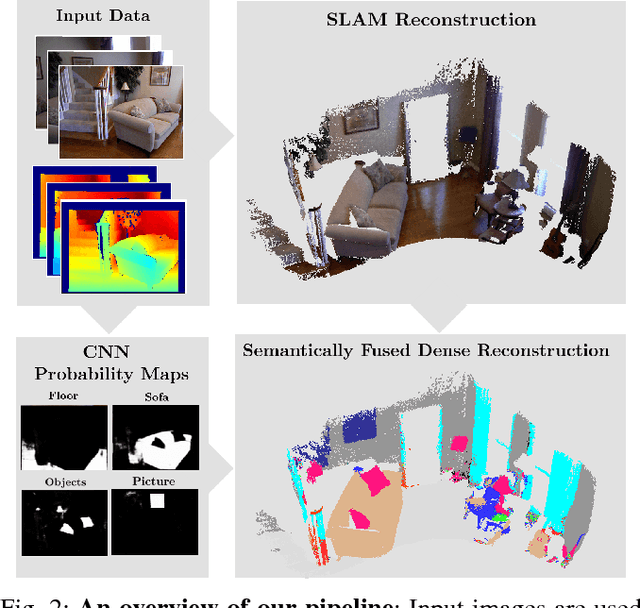

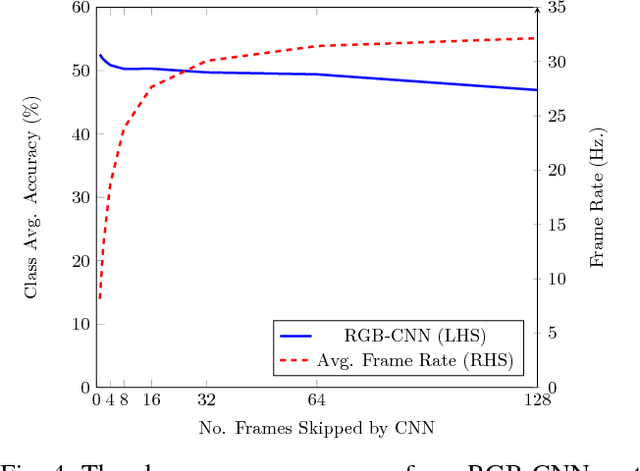
Ever more robust, accurate and detailed mapping using visual sensing has proven to be an enabling factor for mobile robots across a wide variety of applications. For the next level of robot intelligence and intuitive user interaction, maps need extend beyond geometry and appearence - they need to contain semantics. We address this challenge by combining Convolutional Neural Networks (CNNs) and a state of the art dense Simultaneous Localisation and Mapping (SLAM) system, ElasticFusion, which provides long-term dense correspondence between frames of indoor RGB-D video even during loopy scanning trajectories. These correspondences allow the CNN's semantic predictions from multiple view points to be probabilistically fused into a map. This not only produces a useful semantic 3D map, but we also show on the NYUv2 dataset that fusing multiple predictions leads to an improvement even in the 2D semantic labelling over baseline single frame predictions. We also show that for a smaller reconstruction dataset with larger variation in prediction viewpoint, the improvement over single frame segmentation increases. Our system is efficient enough to allow real-time interactive use at frame-rates of approximately 25Hz.
gvnn: Neural Network Library for Geometric Computer Vision
Aug 12, 2016



We introduce gvnn, a neural network library in Torch aimed towards bridging the gap between classic geometric computer vision and deep learning. Inspired by the recent success of Spatial Transformer Networks, we propose several new layers which are often used as parametric transformations on the data in geometric computer vision. These layers can be inserted within a neural network much in the spirit of the original spatial transformers and allow backpropagation to enable end-to-end learning of a network involving any domain knowledge in geometric computer vision. This opens up applications in learning invariance to 3D geometric transformation for place recognition, end-to-end visual odometry, depth estimation and unsupervised learning through warping with a parametric transformation for image reconstruction error.