 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Deep Reinforcement Learning Algorithms for Mean Field Games
Mar 22, 2022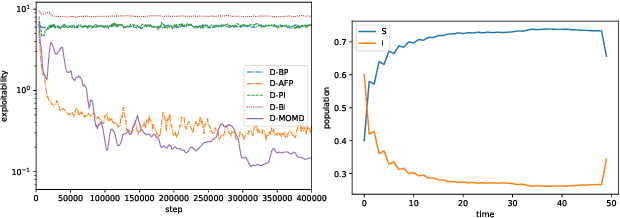
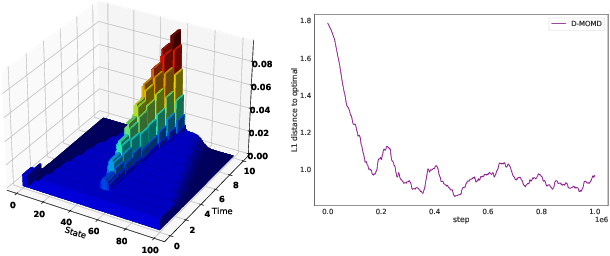
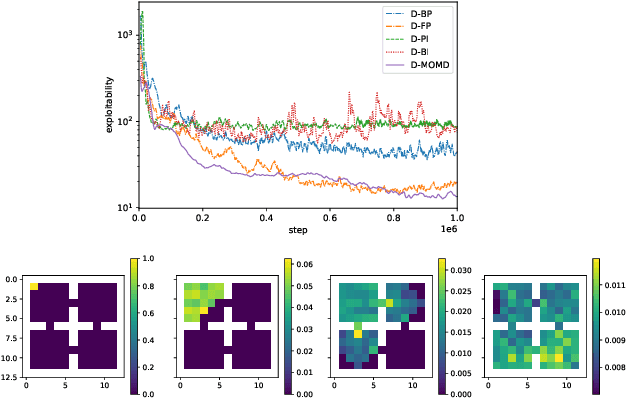
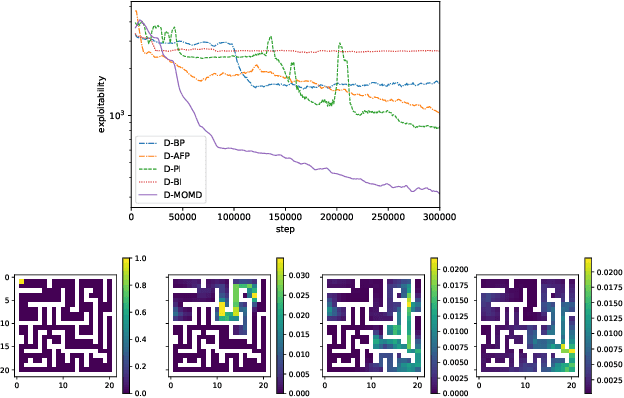
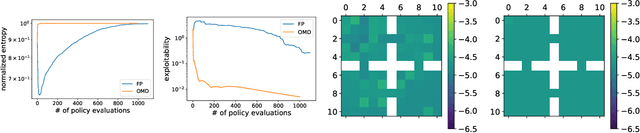
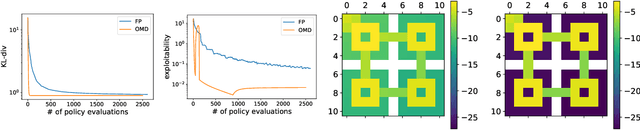
Mean Field Games (MFGs) have been introduced to efficiently approximate games with very large populations of strategic agents. Recently, the question of learning equilibria in MFGs has gained momentum, particularly using model-free reinforcement learning (RL) methods. One limiting factor to further scale up using RL is that existing algorithms to solve MFGs require the mixing of approximated quantities such as strategies or $q$-values. This is non-trivial in the case of non-linear function approximation that enjoy good generalization properties, e.g. neural networks. We propose two methods to address this shortcoming. The first one learns a mixed strategy from distillation of historical data into a neural network and is applied to the Fictitious Play algorithm. The second one is an online mixing method based on regularization that does not require memorizing historical data or previous estimates. It is used to extend Online Mirror Descent. We demonstrate numerically that these methods efficiently enable the use of Deep RL algorithms to solve various MFGs. In addition, we show that these methods outperform SotA baselines from the literature.
Generalization in Mean Field Games by Learning Master Policies
Sep 20, 2021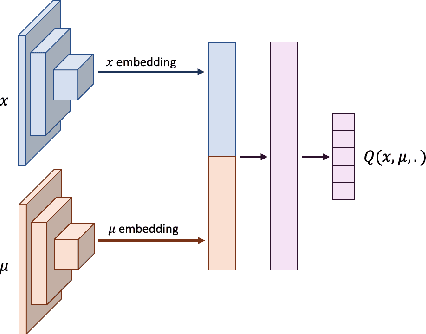
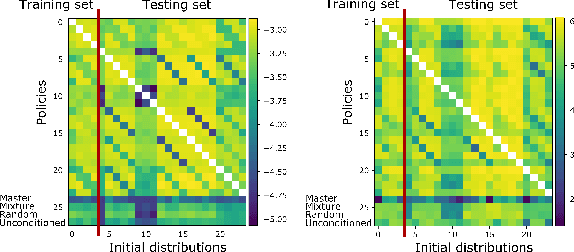

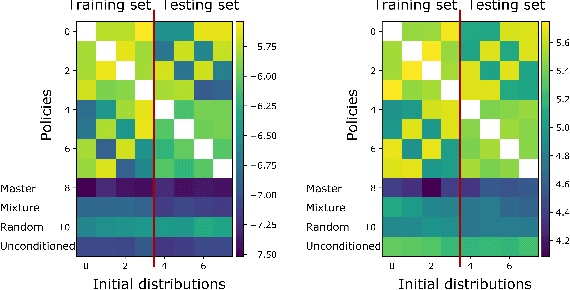
Mean Field Games (MFGs) can potentially scale multi-agent systems to extremely large populations of agents. Yet, most of the literature assumes a single initial distribution for the agents, which limits the practical applications of MFGs. Machine Learning has the potential to solve a wider diversity of MFG problems thanks to generalizations capacities. We study how to leverage these generalization properties to learn policies enabling a typical agent to behave optimally against any population distribution. In reference to the Master equation in MFGs, we coin the term ``Master policies'' to describe them and we prove that a single Master policy provides a Nash equilibrium, whatever the initial distribution. We propose a method to learn such Master policies. Our approach relies on three ingredients: adding the current population distribution as part of the observation, approximating Master policies with neural networks, and training via Reinforcement Learning and Fictitious Play. We illustrate on numerical examples not only the efficiency of the learned Master policy but also its generalization capabilities beyond the distributions used for training.
Concave Utility Reinforcement Learning: the Mean-field Game viewpoint
Jun 09, 2021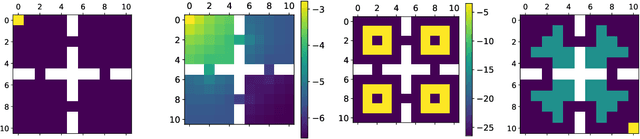

Concave Utility Reinforcement Learning (CURL) extends RL from linear to concave utilities in the occupancy measure induced by the agent's policy. This encompasses not only RL but also imitation learning and exploration, among others. Yet, this more general paradigm invalidates the classical Bellman equations, and calls for new algorithms. Mean-field Games (MFGs) are a continuous approximation of many-agent RL. They consider the limit case of a continuous distribution of identical agents, anonymous with symmetric interests, and reduce the problem to the study of a single representative agent in interaction with the full population. Our core contribution consists in showing that CURL is a subclass of MFGs. We think this important to bridge together both communities. It also allows to shed light on aspects of both fields: we show the equivalence between concavity in CURL and monotonicity in the associated MFG, between optimality conditions in CURL and Nash equilibrium in MFG, or that Fictitious Play (FP) for this class of MFGs is simply Frank-Wolfe, bringing the first convergence rate for discrete-time FP for MFGs. We also experimentally demonstrate that, using algorithms recently introduced for solving MFGs, we can address the CURL problem more efficiently.
Mean Field Games Flock! The Reinforcement Learning Way
May 17, 2021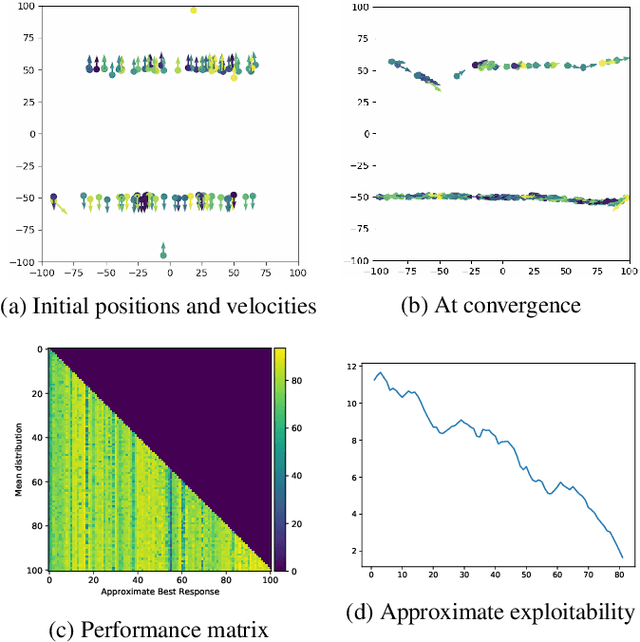
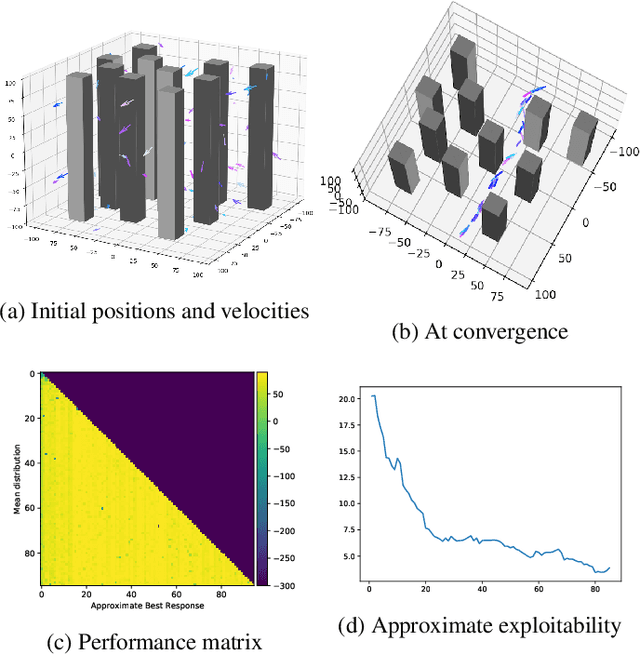
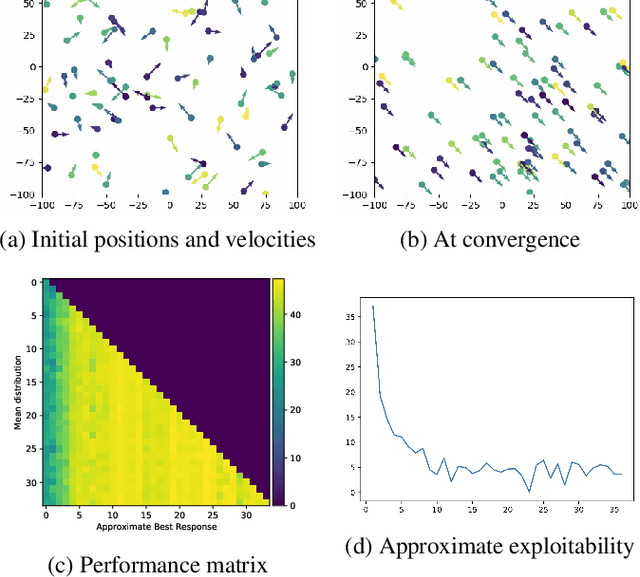
We present a method enabling a large number of agents to learn how to flock, which is a natural behavior observed in large populations of animals. This problem has drawn a lot of interest but requires many structural assumptions and is tractable only in small dimensions. We phrase this problem as a Mean Field Game (MFG), where each individual chooses its acceleration depending on the population behavior. Combining Deep Reinforcement Learning (RL) and Normalizing Flows (NF), we obtain a tractable solution requiring only very weak assumptions. Our algorithm finds a Nash Equilibrium and the agents adapt their velocity to match the neighboring flock's average one. We use Fictitious Play and alternate: (1) computing an approximate best response with Deep RL, and (2) estimating the next population distribution with NF. We show numerically that our algorithm learn multi-group or high-dimensional flocking with obstacles.
Learning to Play No-Press Diplomacy with Best Response Policy Iteration
Jun 17, 2020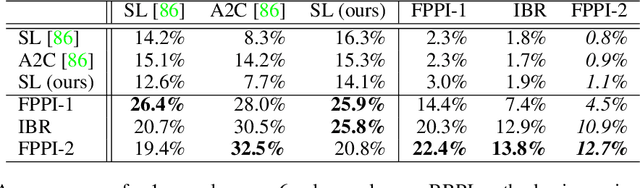
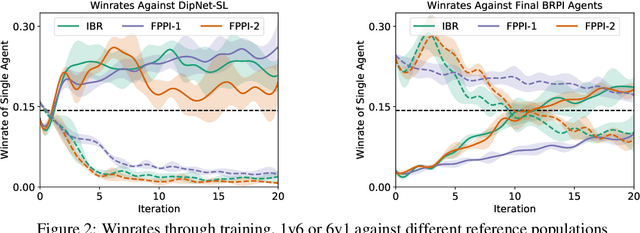
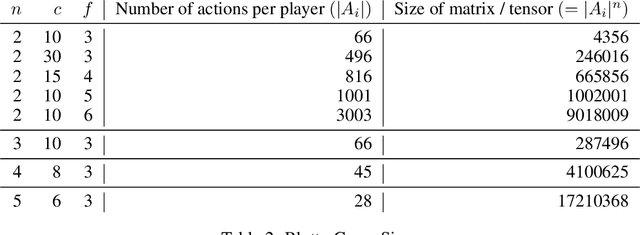
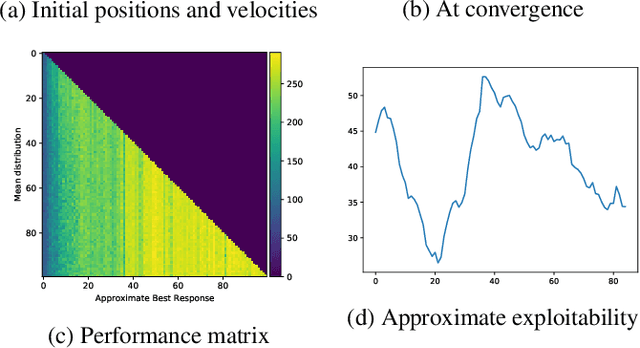
Recent advances in deep reinforcement learning (RL) have led to considerable progress in many 2-player zero-sum games, such as Go, Poker and Starcraft. The purely adversarial nature of such games allows for conceptually simple and principled application of RL methods. However real-world settings are many-agent, and agent interactions are complex mixtures of common-interest and competitive aspects. We consider Diplomacy, a 7-player board game designed to accentuate dilemmas resulting from many-agent interactions. It also features a large combinatorial action space and simultaneous moves, which are challenging for RL algorithms. We propose a simple yet effective approximate best response operator, designed to handle large combinatorial action spaces and simultaneous moves. We also introduce a family of policy iteration methods that approximate fictitious play. With these methods, we successfully apply RL to Diplomacy: we show that our agents convincingly outperform the previous state-of-the-art, and game theoretic equilibrium analysis shows that the new process yields consistent improvements.
OpenSpiel: A Framework for Reinforcement Learning in Games
Oct 10, 2019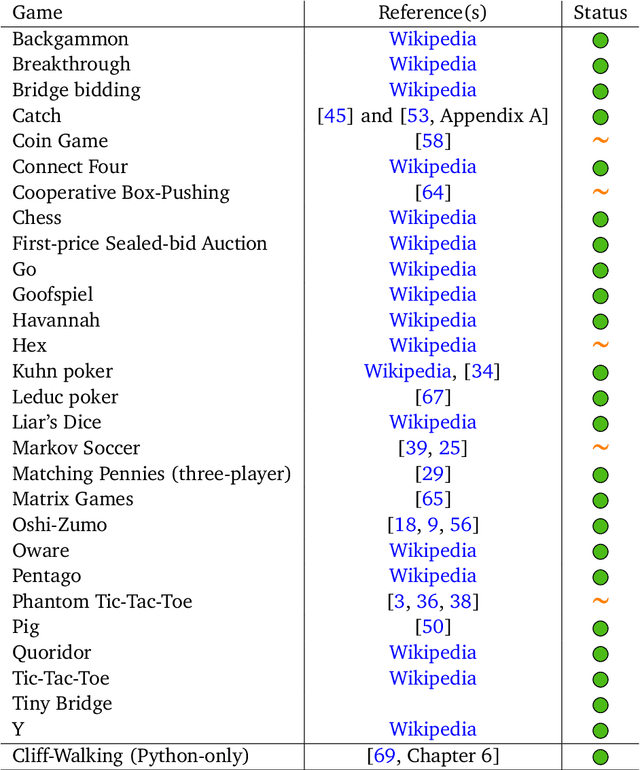
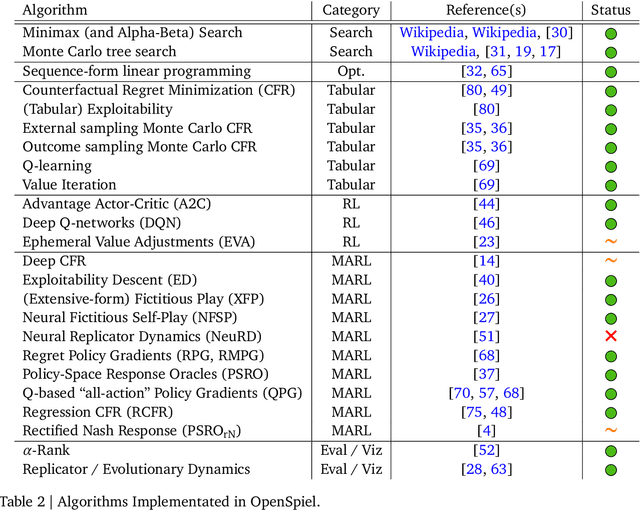
OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games. OpenSpiel supports n-player (single- and multi- agent) zero-sum, cooperative and general-sum, one-shot and sequential, strictly turn-taking and simultaneous-move, perfect and imperfect information games, as well as traditional multiagent environments such as (partially- and fully- observable) grid worlds and social dilemmas. OpenSpiel also includes tools to analyze learning dynamics and other common evaluation metrics. This document serves both as an overview of the code base and an introduction to the terminology, core concepts, and algorithms across the fields of reinforcement learning, computational game theory, and search.
Approximate Fictitious Play for Mean Field Games
Jul 04, 2019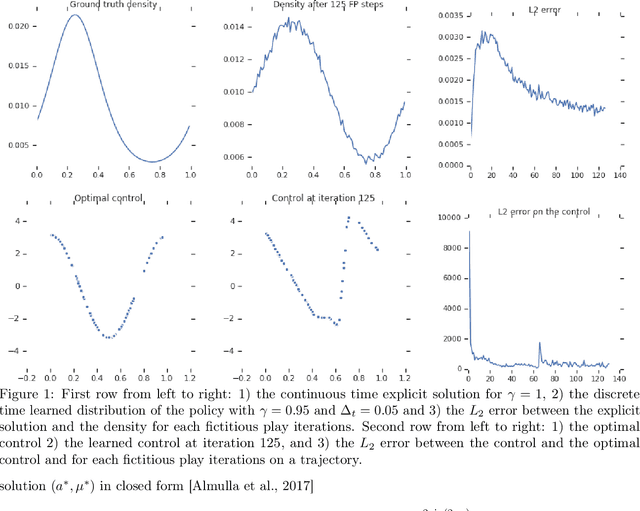
The theory of Mean Field Games (MFG) allows characterizing the Nash equilibria of an infinite number of identical players, and provides a convenient and relevant mathematical framework for the study of games with a large number of agents in interaction. Until very recently, the literature only considered Nash equilibria between fully informed players. In this paper, we focus on the realistic setting where agents with no prior information on the game learn their best response policy through repeated experience. We study the convergence to a (possibly approximate) Nash equilibrium of a fictitious play iterative learning scheme where the best response is approximately computed, typically by a reinforcement learning (RL) algorithm. Notably, we show for the first time convergence of model free learning algorithms towards non-stationary MFG equilibria, relying only on classical assumptions on the MFG dynamics. We illustrate our theoretical results with a numerical experiment in continuous action-space setting, where the best response of the iterative fictitious play scheme is computed with a deep RL algorithm.
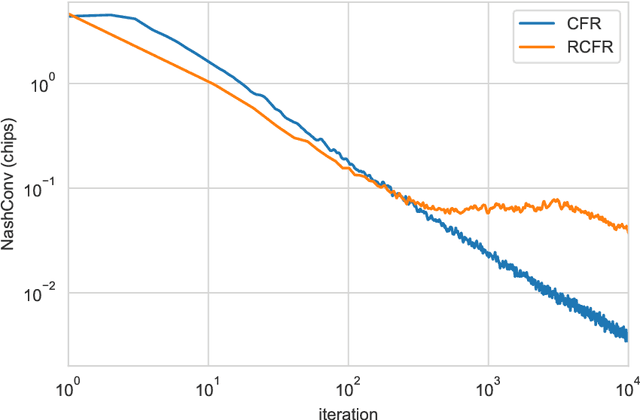
Computing Approximate Equilibria in Sequential Adversarial Games by Exploitability Descent
Mar 21, 2019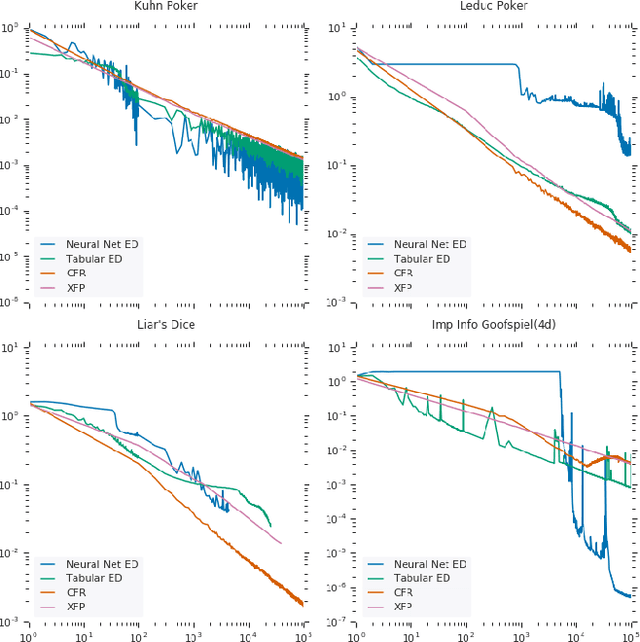
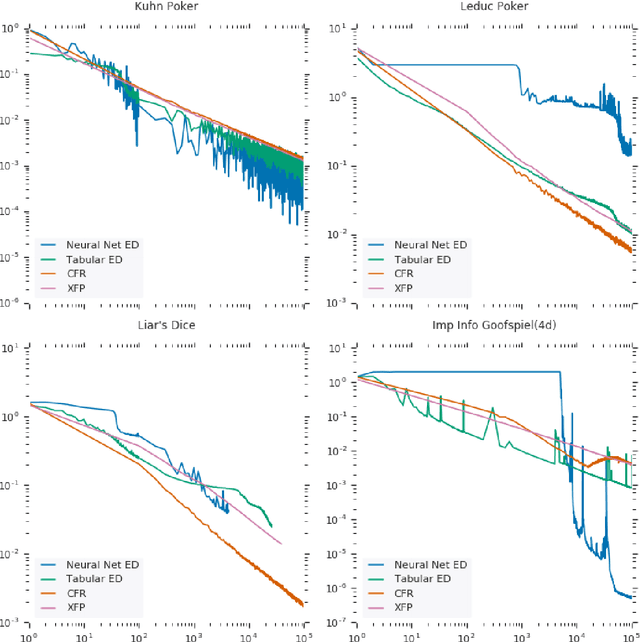
In this paper, we present exploitability descent, a new algorithm to compute approximate equilibria in two-player zero-sum extensive-form games with imperfect information, by direct policy optimization against worst-case opponents. We prove that when following this optimization, the exploitability of a player's strategy converges asymptotically to zero, and hence when both players employ this optimization, the joint policies converge to a Nash equilibrium. Unlike fictitious play (XFP) and counterfactual regret minimization (CFR), our convergence result pertains to the policies being optimized rather than the average policies. Our experiments demonstrate convergence rates comparable to XFP and CFR in four benchmark games in the tabular case. Using function approximation, we find that our algorithm outperforms the tabular version in two of the games, which, to the best of our knowledge, is the first such result in imperfect information games among this class of algorithms.