 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximate Fictitious Play for Mean Field Games
Paper and Code
Jul 04, 2019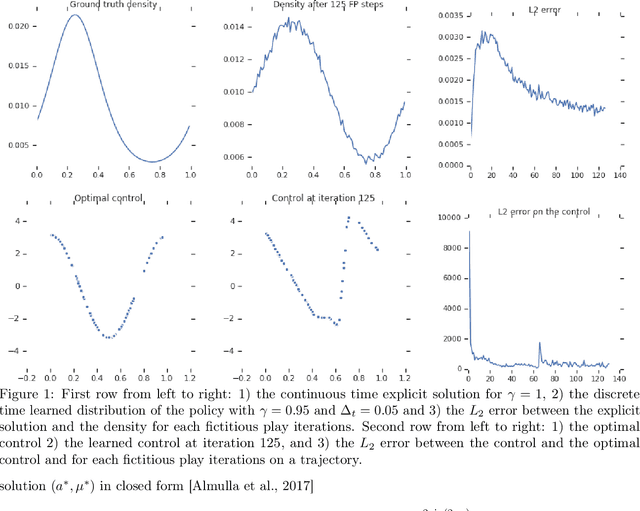
The theory of Mean Field Games (MFG) allows characterizing the Nash equilibria of an infinite number of identical players, and provides a convenient and relevant mathematical framework for the study of games with a large number of agents in interaction. Until very recently, the literature only considered Nash equilibria between fully informed players. In this paper, we focus on the realistic setting where agents with no prior information on the game learn their best response policy through repeated experience. We study the convergence to a (possibly approximate) Nash equilibrium of a fictitious play iterative learning scheme where the best response is approximately computed, typically by a reinforcement learning (RL) algorithm. Notably, we show for the first time convergence of model free learning algorithms towards non-stationary MFG equilibria, relying only on classical assumptions on the MFG dynamics. We illustrate our theoretical results with a numerical experiment in continuous action-space setting, where the best response of the iterative fictitious play scheme is computed with a deep RL algorithm.