 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Ended Learning Leads to Generally Capable Agents
Jul 31, 2021
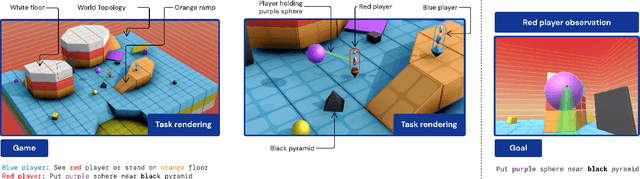

In this work we create agents that can perform well beyond a single, individual task, that exhibit much wider generalisation of behaviour to a massive, rich space of challenges. We define a universe of tasks within an environment domain and demonstrate the ability to train agents that are generally capable across this vast space and beyond. The environment is natively multi-agent, spanning the continuum of competitive, cooperative, and independent games, which are situated within procedurally generated physical 3D worlds. The resulting space is exceptionally diverse in terms of the challenges posed to agents, and as such, even measuring the learning progress of an agent is an open research problem. We propose an iterative notion of improvement between successive generations of agents, rather than seeking to maximise a singular objective, allowing us to quantify progress despite tasks being incomparable in terms of achievable rewards. We show that through constructing an open-ended learning process, which dynamically changes the training task distributions and training objectives such that the agent never stops learning, we achieve consistent learning of new behaviours. The resulting agent is able to score reward in every one of our humanly solvable evaluation levels, with behaviour generalising to many held-out points in the universe of tasks. Examples of this zero-shot generalisation include good performance on Hide and Seek, Capture the Flag, and Tag. Through analysis and hand-authored probe tasks we characterise the behaviour of our agent, and find interesting emergent heuristic behaviours such as trial-and-error experimentation, simple tool use, option switching, and cooperation. Finally, we demonstrate that the general capabilities of this agent could unlock larger scale transfer of behaviour through cheap finetuning.
Alchemy: A structured task distribution for meta-reinforcement learning
Feb 04, 2021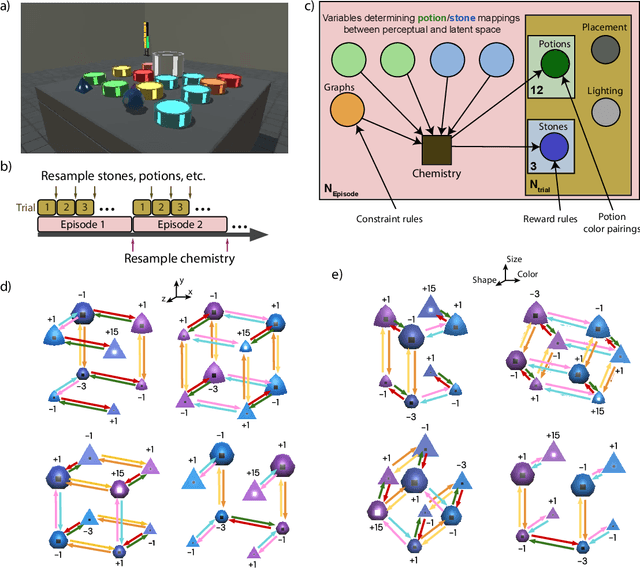

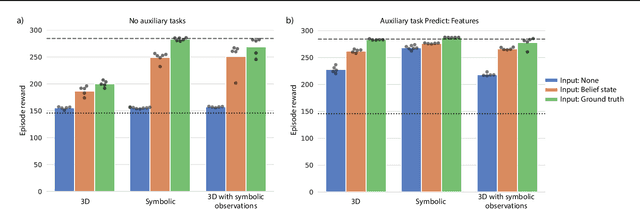

There has been rapidly growing interest in meta-learning as a method for increasing the flexibility and sample efficiency of reinforcement learning. One problem in this area of research, however, has been a scarcity of adequate benchmark tasks. In general, the structure underlying past benchmarks has either been too simple to be inherently interesting, or too ill-defined to support principled analysis. In the present work, we introduce a new benchmark for meta-RL research, which combines structural richness with structural transparency. Alchemy is a 3D video game, implemented in Unity, which involves a latent causal structure that is resampled procedurally from episode to episode, affording structure learning, online inference, hypothesis testing and action sequencing based on abstract domain knowledge. We evaluate a pair of powerful RL agents on Alchemy and present an in-depth analysis of one of these agents. Results clearly indicate a frank and specific failure of meta-learning, providing validation for Alchemy as a challenging benchmark for meta-RL. Concurrent with this report, we are releasing Alchemy as public resource, together with a suite of analysis tools and sample agent trajectories.
Learning to Play No-Press Diplomacy with Best Response Policy Iteration
Jun 17, 2020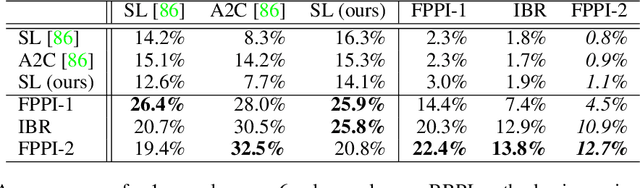
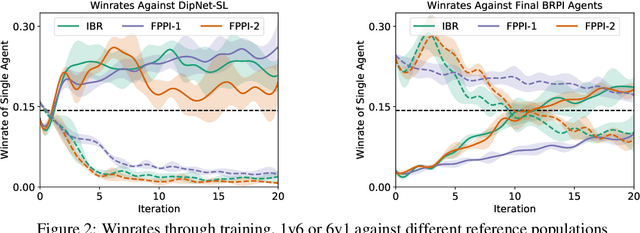
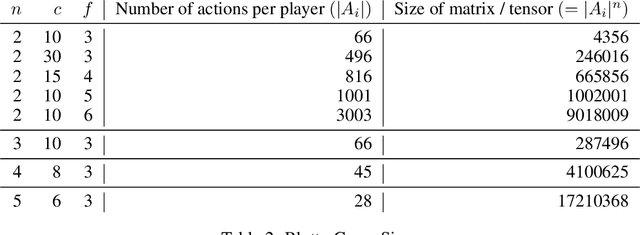
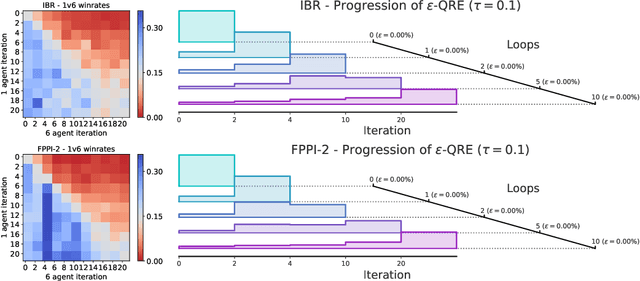
Recent advances in deep reinforcement learning (RL) have led to considerable progress in many 2-player zero-sum games, such as Go, Poker and Starcraft. The purely adversarial nature of such games allows for conceptually simple and principled application of RL methods. However real-world settings are many-agent, and agent interactions are complex mixtures of common-interest and competitive aspects. We consider Diplomacy, a 7-player board game designed to accentuate dilemmas resulting from many-agent interactions. It also features a large combinatorial action space and simultaneous moves, which are challenging for RL algorithms. We propose a simple yet effective approximate best response operator, designed to handle large combinatorial action spaces and simultaneous moves. We also introduce a family of policy iteration methods that approximate fictitious play. With these methods, we successfully apply RL to Diplomacy: we show that our agents convincingly outperform the previous state-of-the-art, and game theoretic equilibrium analysis shows that the new process yields consistent improvements.