 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive representations: building blocks of intelligence
Feb 09, 2024Adaptive behavior often requires predicting future events. The theory of reinforcement learning prescribes what kinds of predictive representations are useful and how to compute them. This paper integrates these theoretical ideas with work on cognition and neuroscience. We pay special attention to the successor representation (SR) and its generalizations, which have been widely applied both as engineering tools and models of brain function. This convergence suggests that particular kinds of predictive representations may function as versatile building blocks of intelligence.
Temporally Extended Successor Representations
Sep 25, 2022
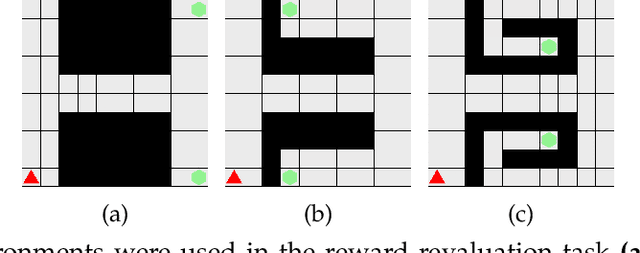
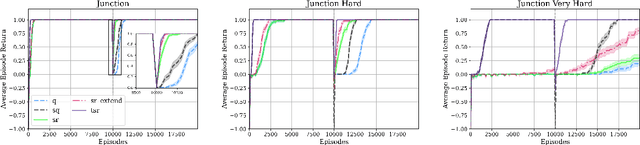
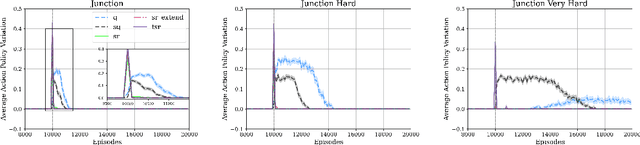
We present a temporally extended variation of the successor representation, which we term t-SR. t-SR captures the expected state transition dynamics of temporally extended actions by constructing successor representations over primitive action repeats. This form of temporal abstraction does not learn a top-down hierarchy of pertinent task structures, but rather a bottom-up composition of coupled actions and action repetitions. This lessens the amount of decisions required in control without learning a hierarchical policy. As such, t-SR directly considers the time horizon of temporally extended action sequences without the need for predefined or domain-specific options. We show that in environments with dynamic reward structure, t-SR is able to leverage both the flexibility of the successor representation and the abstraction afforded by temporally extended actions. Thus, in a series of sparsely rewarded gridworld environments, t-SR optimally adapts learnt policies far faster than comparable value-based, model-free reinforcement learning methods. We also show that the manner in which t-SR learns to solve these tasks requires the learnt policy to be sampled consistently less often than non-temporally extended policies.