 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextwash -- automated open-source text anonymisation
Paper and Code

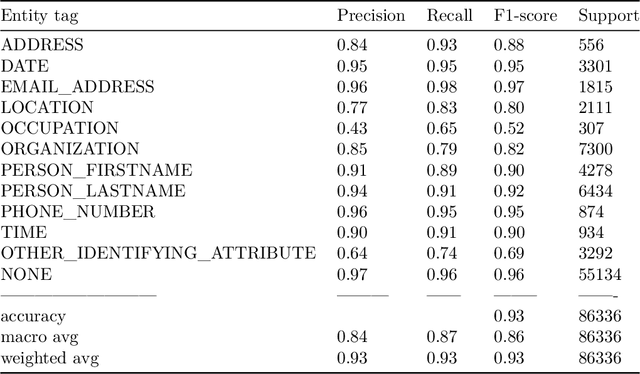
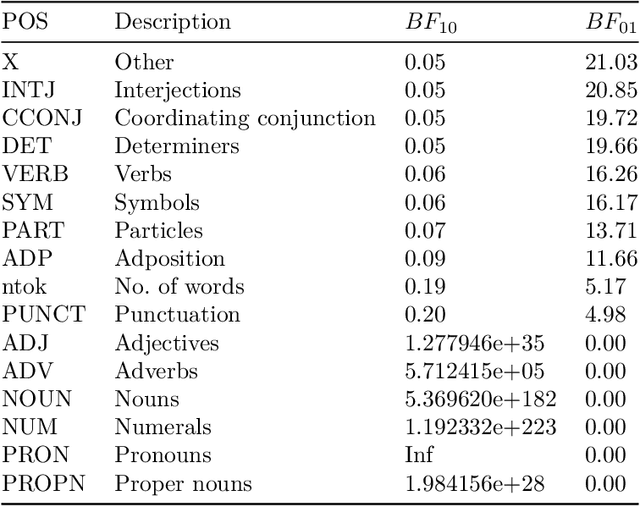
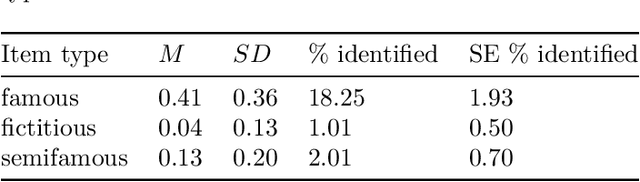
The increased use of text data in social science research has benefited from easy-to-access data (e.g., Twitter). That trend comes at the cost of research requiring sensitive but hard-to-share data (e.g., interview data, police reports, electronic health records). We introduce a solution to that stalemate with the open-source text anonymisation software_Textwash_. This paper presents the empirical evaluation of the tool using the TILD criteria: a technical evaluation (how accurate is the tool?), an information loss evaluation (how much information is lost in the anonymisation process?) and a de-anonymisation test (can humans identify individuals from anonymised text data?). The findings suggest that Textwash performs similar to state-of-the-art entity recognition models and introduces a negligible information loss of 0.84%. For the de-anonymisation test, we tasked humans to identify individuals by name from a dataset of crowdsourced person descriptions of very famous, semi-famous and non-existing individuals. The de-anonymisation rate ranged from 1.01-2.01% for the realistic use cases of the tool. We replicated the findings in a second study and concluded that Textwash succeeds in removing potentially sensitive information that renders detailed person descriptions practically anonymous.