 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrying to be human: Linguistic traces of stochastic empathy in language models
Oct 02, 2024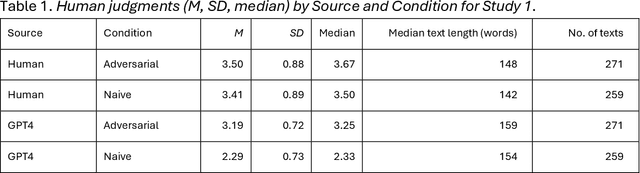
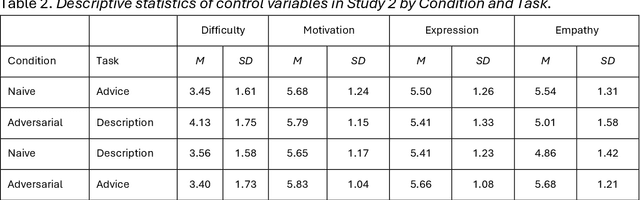
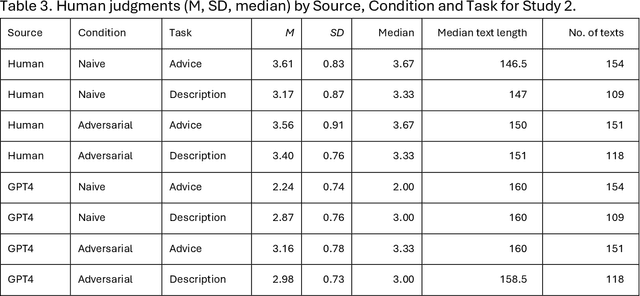
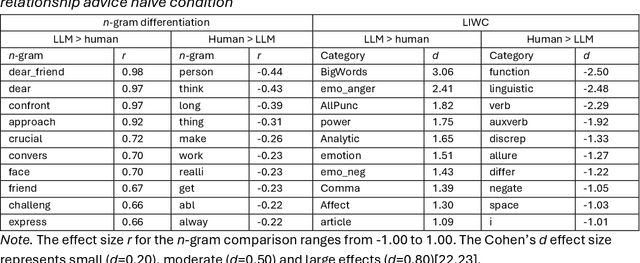
Differentiating between generated and human-written content is important for navigating the modern world. Large language models (LLMs) are crucial drivers behind the increased quality of computer-generated content. Reportedly, humans find it increasingly difficult to identify whether an AI model generated a piece of text. Our work tests how two important factors contribute to the human vs AI race: empathy and an incentive to appear human. We address both aspects in two experiments: human participants and a state-of-the-art LLM wrote relationship advice (Study 1, n=530) or mere descriptions (Study 2, n=610), either instructed to be as human as possible or not. New samples of humans (n=428 and n=408) then judged the texts' source. Our findings show that when empathy is required, humans excel. Contrary to expectations, instructions to appear human were only effective for the LLM, so the human advantage diminished. Computational text analysis revealed that LLMs become more human because they may have an implicit representation of what makes a text human and effortlessly apply these heuristics. The model resorts to a conversational, self-referential, informal tone with a simpler vocabulary to mimic stochastic empathy. We discuss these findings in light of recent claims on the on-par performance of LLMs.