 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen lies are mostly truthful: automated verbal deception detection for embedded lies
Jan 13, 2025Background: Verbal deception detection research relies on narratives and commonly assumes statements as truthful or deceptive. A more realistic perspective acknowledges that the veracity of statements exists on a continuum with truthful and deceptive parts being embedded within the same statement. However, research on embedded lies has been lagging behind. Methods: We collected a novel dataset of 2,088 truthful and deceptive statements with annotated embedded lies. Using a within-subjects design, participants provided a truthful account of an autobiographical event. They then rewrote their statement in a deceptive manner by including embedded lies, which they highlighted afterwards and judged on lie centrality, deceptiveness, and source. Results: We show that a fined-tuned language model (Llama-3-8B) can classify truthful statements and those containing embedded lies with 64% accuracy. Individual differences, linguistic properties and explainability analysis suggest that the challenge of moving the dial towards embedded lies stems from their resemblance to truthful statements. Typical deceptive statements consisted of 2/3 truthful information and 1/3 embedded lies, largely derived from past personal experiences and with minimal linguistic differences with their truthful counterparts. Conclusion: We present this dataset as a novel resource to address this challenge and foster research on embedded lies in verbal deception detection.
Effective faking of verbal deception detection with target-aligned adversarial attacks
Jan 10, 2025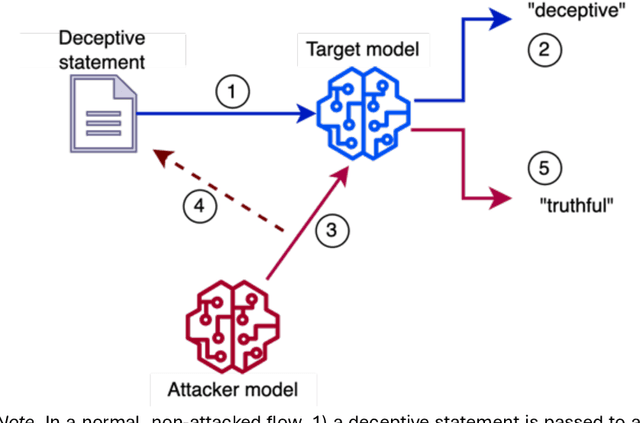
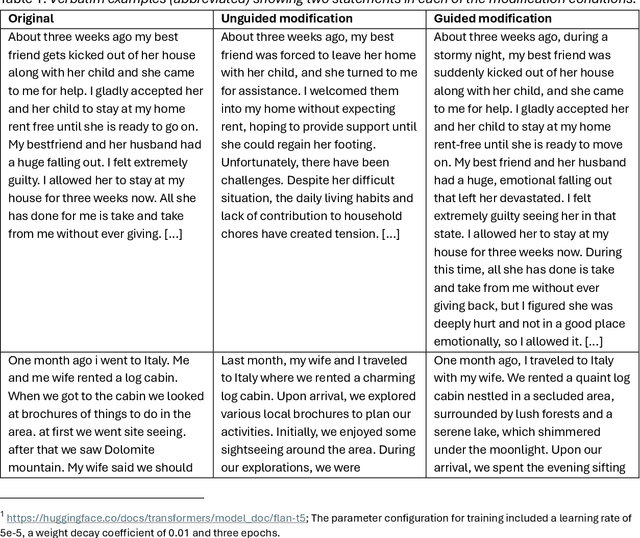
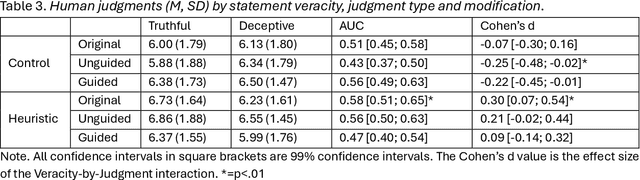
Background: Deception detection through analysing language is a promising avenue using both human judgments and automated machine learning judgments. For both forms of credibility assessment, automated adversarial attacks that rewrite deceptive statements to appear truthful pose a serious threat. Methods: We used a dataset of 243 truthful and 262 fabricated autobiographical stories in a deception detection task for humans and machine learning models. A large language model was tasked to rewrite deceptive statements so that they appear truthful. In Study 1, humans who made a deception judgment or used the detailedness heuristic and two machine learning models (a fine-tuned language model and a simple n-gram model) judged original or adversarial modifications of deceptive statements. In Study 2, we manipulated the target alignment of the modifications, i.e. tailoring the attack to whether the statements would be assessed by humans or computer models. Results: When adversarial modifications were aligned with their target, human (d=-0.07 and d=-0.04) and machine judgments (51% accuracy) dropped to the chance level. When the attack was not aligned with the target, both human heuristics judgments (d=0.30 and d=0.36) and machine learning predictions (63-78%) were significantly better than chance. Conclusions: Easily accessible language models can effectively help anyone fake deception detection efforts both by humans and machine learning models. Robustness against adversarial modifications for humans and machines depends on that target alignment. We close with suggestions on advancing deception research with adversarial attack designs.
Trying to be human: Linguistic traces of stochastic empathy in language models
Oct 02, 2024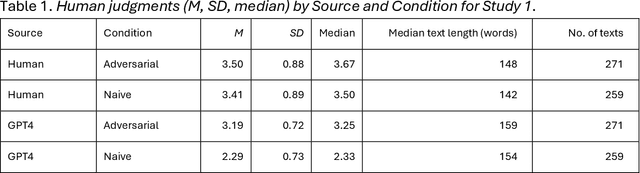
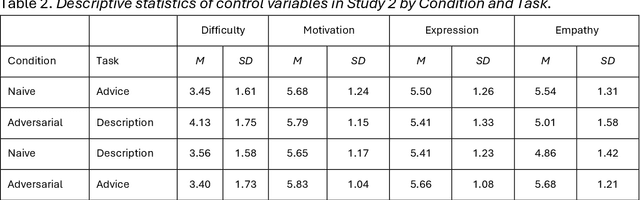
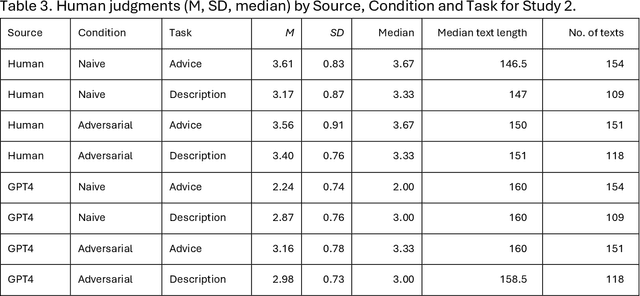
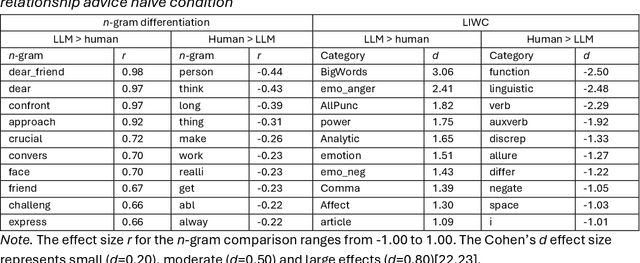
Differentiating between generated and human-written content is important for navigating the modern world. Large language models (LLMs) are crucial drivers behind the increased quality of computer-generated content. Reportedly, humans find it increasingly difficult to identify whether an AI model generated a piece of text. Our work tests how two important factors contribute to the human vs AI race: empathy and an incentive to appear human. We address both aspects in two experiments: human participants and a state-of-the-art LLM wrote relationship advice (Study 1, n=530) or mere descriptions (Study 2, n=610), either instructed to be as human as possible or not. New samples of humans (n=428 and n=408) then judged the texts' source. Our findings show that when empathy is required, humans excel. Contrary to expectations, instructions to appear human were only effective for the LLM, so the human advantage diminished. Computational text analysis revealed that LLMs become more human because they may have an implicit representation of what makes a text human and effortlessly apply these heuristics. The model resorts to a conversational, self-referential, informal tone with a simpler vocabulary to mimic stochastic empathy. We discuss these findings in light of recent claims on the on-par performance of LLMs.