 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Lie: How Reasoning Leads to Honesty
Mar 16, 2026While existing evaluations of large language models (LLMs) measure deception rates, the underlying conditions that give rise to deceptive behavior are poorly understood. We investigate this question using a novel dataset of realistic moral trade-offs where honesty incurs variable costs. Contrary to humans, who tend to become less honest given time to deliberate (Capraro, 2017; Capraro et al., 2019), we find that reasoning consistently increases honesty across scales and for several LLM families. This effect is not only a function of the reasoning content, as reasoning traces are often poor predictors of final behaviors. Rather, we show that the underlying geometry of the representational space itself contributes to the effect. Namely, we observe that deceptive regions within this space are metastable: deceptive answers are more easily destabilized by input paraphrasing, output resampling, and activation noise than honest ones. We interpret the effect of reasoning in this vein: generating deliberative tokens as part of moral reasoning entails the traversal of a biased representational space, ultimately nudging the model toward its more stable, honest defaults.
Think Before You Lie: How Reasoning Improves Honesty
Mar 10, 2026While existing evaluations of large language models (LLMs) measure deception rates, the underlying conditions that give rise to deceptive behavior are poorly understood. We investigate this question using a novel dataset of realistic moral trade-offs where honesty incurs variable costs. Contrary to humans, who tend to become less honest given time to deliberate (Capraro, 2017; Capraro et al., 2019), we find that reasoning consistently increases honesty across scales and for several LLM families. This effect is not only a function of the reasoning content, as reasoning traces are often poor predictors of final behaviors. Rather, we show that the underlying geometry of the representational space itself contributes to the effect. Namely, we observe that deceptive regions within this space are metastable: deceptive answers are more easily destabilized by input paraphrasing, output resampling, and activation noise than honest ones. We interpret the effect of reasoning in this vein: generating deliberative tokens as part of moral reasoning entails the traversal of a biased representational space, ultimately nudging the model toward its more stable, honest defaults.
Language Models Struggle to Use Representations Learned In-Context
Feb 04, 2026Though large language models (LLMs) have enabled great success across a wide variety of tasks, they still appear to fall short of one of the loftier goals of artificial intelligence research: creating an artificial system that can adapt its behavior to radically new contexts upon deployment. One important step towards this goal is to create systems that can induce rich representations of data that are seen in-context, and then flexibly deploy these representations to accomplish goals. Recently, Park et al. (2024) demonstrated that current LLMs are indeed capable of inducing such representation from context (i.e., in-context representation learning). The present study investigates whether LLMs can use these representations to complete simple downstream tasks. We first assess whether open-weights LLMs can use in-context representations for next-token prediction, and then probe models using a novel task, adaptive world modeling. In both tasks, we find evidence that open-weights LLMs struggle to deploy representations of novel semantics that are defined in-context, even if they encode these semantics in their latent representations. Furthermore, we assess closed-source, state-of-the-art reasoning models on the adaptive world modeling task, demonstrating that even the most performant LLMs cannot reliably leverage novel patterns presented in-context. Overall, this work seeks to inspire novel methods for encouraging models to not only encode information presented in-context, but to do so in a manner that supports flexible deployment of this information.
Who's asking? User personas and the mechanics of latent misalignment
Jun 17, 2024



Despite investments in improving model safety, studies show that misaligned capabilities remain latent in safety-tuned models. In this work, we shed light on the mechanics of this phenomenon. First, we show that even when model generations are safe, harmful content can persist in hidden representations and can be extracted by decoding from earlier layers. Then, we show that whether the model divulges such content depends significantly on its perception of who it is talking to, which we refer to as user persona. In fact, we find manipulating user persona to be even more effective for eliciting harmful content than direct attempts to control model refusal. We study both natural language prompting and activation steering as control methods and show that activation steering is significantly more effective at bypassing safety filters. We investigate why certain personas break model safeguards and find that they enable the model to form more charitable interpretations of otherwise dangerous queries. Finally, we show we can predict a persona's effect on refusal given only the geometry of its steering vector.
ConstitutionalExperts: Training a Mixture of Principle-based Prompts
Mar 07, 2024



Large language models (LLMs) are highly capable at a variety of tasks given the right prompt, but writing one is still a difficult and tedious process. In this work, we introduce ConstitutionalExperts, a method for learning a prompt consisting of constitutional principles (i.e. rules), given a training dataset. Unlike prior methods that optimize the prompt as a single entity, our method incrementally improves the prompt by surgically editing individual principles. We also show that we can improve overall performance by learning unique prompts for different semantic regions of the training data and using a mixture-of-experts (MoE) architecture to route inputs at inference time. We compare our method to other state of the art prompt-optimization techniques across six benchmark datasets. We also investigate whether MoE improves these other techniques. Our results suggest that ConstitutionalExperts outperforms other prompt optimization techniques by 10.9% (F1) and that mixture-of-experts improves all techniques, suggesting its broad applicability.
Towards Agile Text Classifiers for Everyone
Feb 13, 2023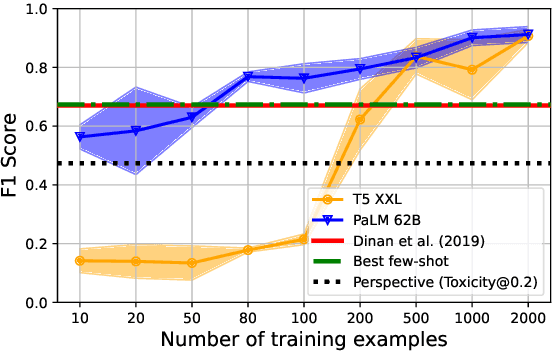
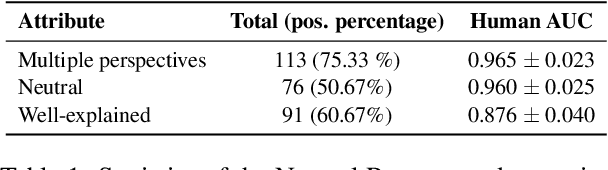
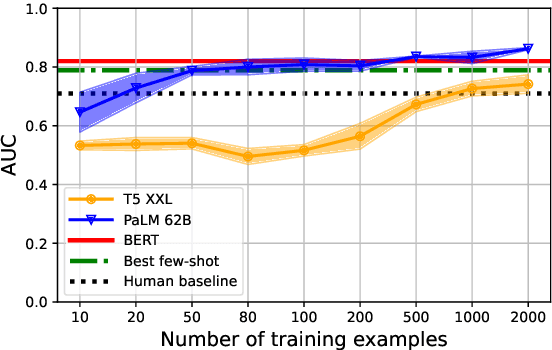
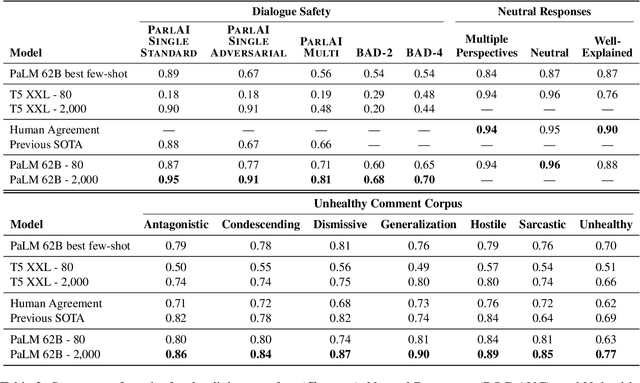
Text-based safety classifiers are widely used for content moderation and increasingly to tune generative language model behavior - a topic of growing concern for the safety of digital assistants and chatbots. However, different policies require different classifiers, and safety policies themselves improve from iteration and adaptation. This paper introduces and evaluates methods for agile text classification, whereby classifiers are trained using small, targeted datasets that can be quickly developed for a particular policy. Experimenting with 7 datasets from three safety-related domains, comprising 15 annotation schemes, led to our key finding: prompt-tuning large language models, like PaLM 62B, with a labeled dataset of as few as 80 examples can achieve state-of-the-art performance. We argue that this enables a paradigm shift for text classification, especially for models supporting safer online discourse. Instead of collecting millions of examples to attempt to create universal safety classifiers over months or years, classifiers could be tuned using small datasets, created by individuals or small organizations, tailored for specific use cases, and iterated on and adapted in the time-span of a day.
Gradient-Based Automated Iterative Recovery for Parameter-Efficient Tuning
Feb 13, 2023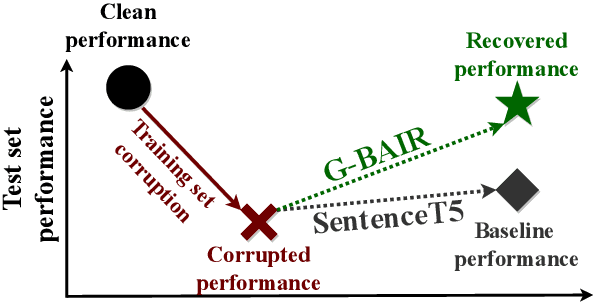

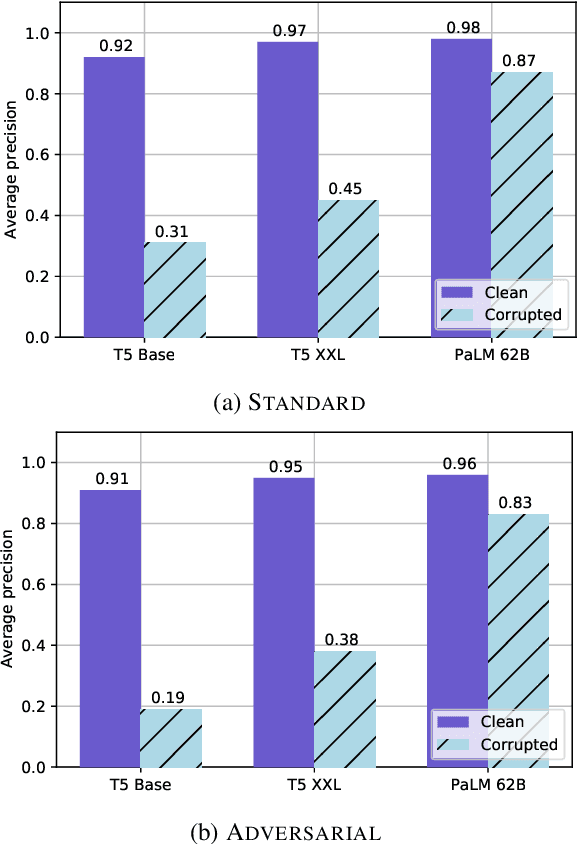
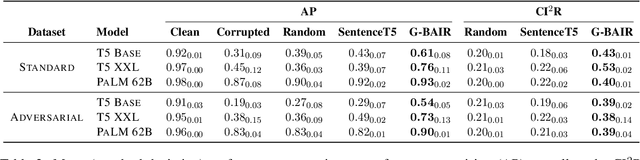
Pretrained large language models (LLMs) are able to solve a wide variety of tasks through transfer learning. Various explainability methods have been developed to investigate their decision making process. TracIn (Pruthi et al., 2020) is one such gradient-based method which explains model inferences based on the influence of training examples. In this paper, we explore the use of TracIn to improve model performance in the parameter-efficient tuning (PET) setting. We develop conversational safety classifiers via the prompt-tuning PET method and show how the unique characteristics of the PET regime enable TracIn to identify the cause for certain misclassifications by LLMs. We develop a new methodology for using gradient-based explainability techniques to improve model performance, G-BAIR: gradient-based automated iterative recovery. We show that G-BAIR can recover LLM performance on benchmarks after manually corrupting training labels. This suggests that influence methods like TracIn can be used to automatically perform data cleaning, and introduces the potential for interactive debugging and relabeling for PET-based transfer learning methods.
Creative Writing with an AI-Powered Writing Assistant: Perspectives from Professional Writers
Nov 09, 2022Recent developments in natural language generation (NLG) using neural language models have brought us closer than ever to the goal of building AI-powered creative writing tools. However, most prior work on human-AI collaboration in the creative writing domain has evaluated new systems with amateur writers, typically in contrived user studies of limited scope. In this work, we commissioned 13 professional, published writers from a diverse set of creative writing backgrounds to craft stories using Wordcraft, a text editor with built-in AI-powered writing assistance tools. Using interviews and participant journals, we discuss the potential of NLG to have significant impact in the creative writing domain--especially with respect to brainstorming, generation of story details, world-building, and research assistance. Experienced writers, more so than amateurs, typically have well-developed systems and methodologies for writing, as well as distinctive voices and target audiences. Our work highlights the challenges in building for these writers; NLG technologies struggle to preserve style and authorial voice, and they lack deep understanding of story contents. In order for AI-powered writing assistants to realize their full potential, it is essential that they take into account the diverse goals and expertise of human writers.
The Case for a Single Model that can Both Generate Continuations and Fill in the Blank
Jun 09, 2022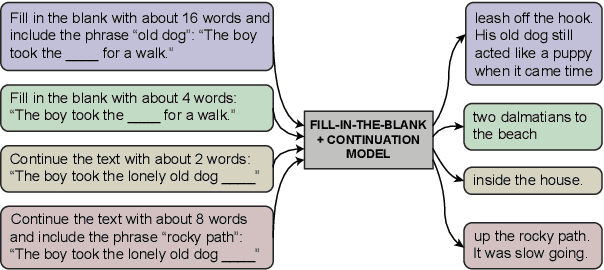

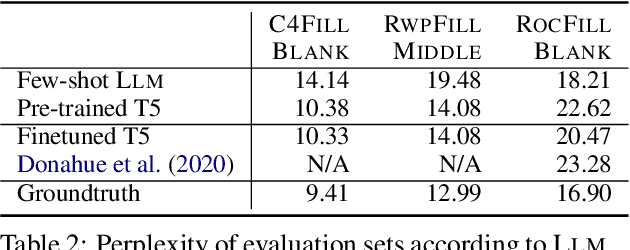
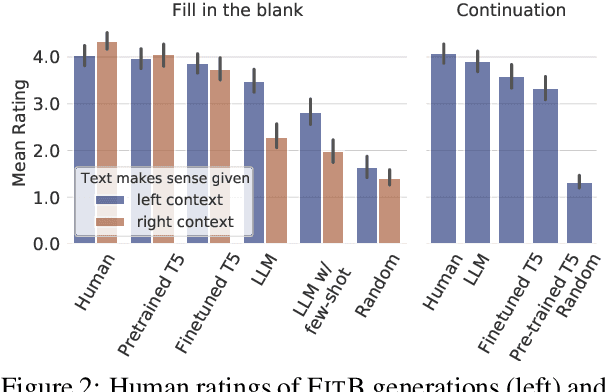
The task of inserting text into a specified position in a passage, known as fill in the blank (FitB), is useful for a variety of applications where writers interact with a natural language generation (NLG) system to craft text. While previous work has tackled this problem with models trained specifically to do the fill-in-the-blank task, a more useful model is one that can effectively perform _both_ FitB and continuation. In this work, we evaluate the feasibility of using a single model to do both tasks. We show that models pre-trained with a FitB-style objective are capable of both tasks, while models pre-trained for continuation are not. Finally, we show how FitB models can be easily finetuned to allow for fine-grained control over the length and word choice of the generation.
SynthBio: A Case Study in Human-AI Collaborative Curation of Text Datasets
Nov 11, 2021
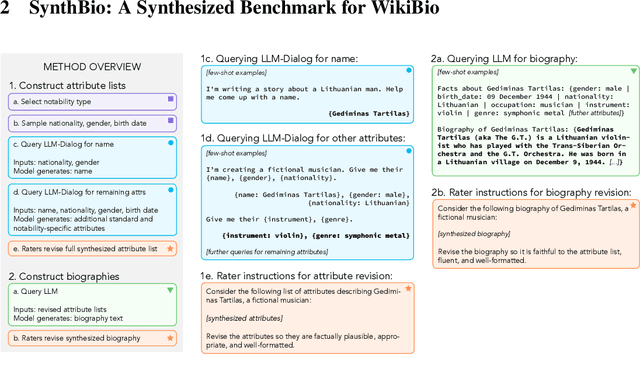

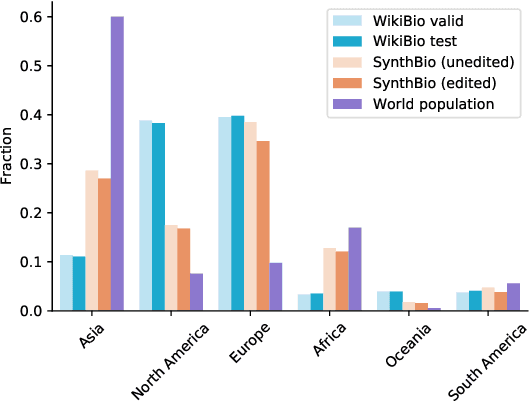
NLP researchers need more, higher-quality text datasets. Human-labeled datasets are expensive to collect, while datasets collected via automatic retrieval from the web such as WikiBio are noisy and can include undesired biases. Moreover, data sourced from the web is often included in datasets used to pretrain models, leading to inadvertent cross-contamination of training and test sets. In this work we introduce a novel method for efficient dataset curation: we use a large language model to provide seed generations to human raters, thereby changing dataset authoring from a writing task to an editing task. We use our method to curate SynthBio - a new evaluation set for WikiBio - composed of structured attribute lists describing fictional individuals, mapped to natural language biographies. We show that our dataset of fictional biographies is less noisy than WikiBio, and also more balanced with respect to gender and nationality.