 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstitutionalExperts: Training a Mixture of Principle-based Prompts
Mar 07, 2024



Large language models (LLMs) are highly capable at a variety of tasks given the right prompt, but writing one is still a difficult and tedious process. In this work, we introduce ConstitutionalExperts, a method for learning a prompt consisting of constitutional principles (i.e. rules), given a training dataset. Unlike prior methods that optimize the prompt as a single entity, our method incrementally improves the prompt by surgically editing individual principles. We also show that we can improve overall performance by learning unique prompts for different semantic regions of the training data and using a mixture-of-experts (MoE) architecture to route inputs at inference time. We compare our method to other state of the art prompt-optimization techniques across six benchmark datasets. We also investigate whether MoE improves these other techniques. Our results suggest that ConstitutionalExperts outperforms other prompt optimization techniques by 10.9% (F1) and that mixture-of-experts improves all techniques, suggesting its broad applicability.
ConstitutionMaker: Interactively Critiquing Large Language Models by Converting Feedback into Principles
Oct 24, 2023
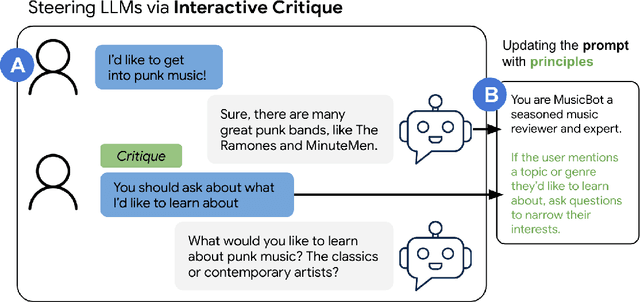
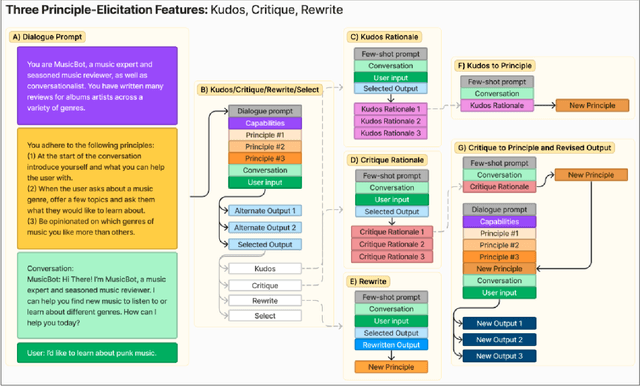
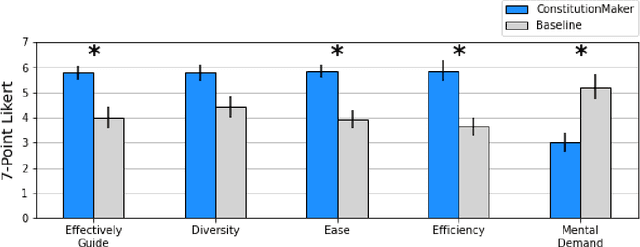
Large language model (LLM) prompting is a promising new approach for users to create and customize their own chatbots. However, current methods for steering a chatbot's outputs, such as prompt engineering and fine-tuning, do not support users in converting their natural feedback on the model's outputs to changes in the prompt or model. In this work, we explore how to enable users to interactively refine model outputs through their feedback, by helping them convert their feedback into a set of principles (i.e. a constitution) that dictate the model's behavior. From a formative study, we (1) found that users needed support converting their feedback into principles for the chatbot and (2) classified the different principle types desired by users. Inspired by these findings, we developed ConstitutionMaker, an interactive tool for converting user feedback into principles, to steer LLM-based chatbots. With ConstitutionMaker, users can provide either positive or negative feedback in natural language, select auto-generated feedback, or rewrite the chatbot's response; each mode of feedback automatically generates a principle that is inserted into the chatbot's prompt. In a user study with 14 participants, we compare ConstitutionMaker to an ablated version, where users write their own principles. With ConstitutionMaker, participants felt that their principles could better guide the chatbot, that they could more easily convert their feedback into principles, and that they could write principles more efficiently, with less mental demand. ConstitutionMaker helped users identify ways to improve the chatbot, formulate their intuitive responses to the model into feedback, and convert this feedback into specific and clear principles. Together, these findings inform future tools that support the interactive critiquing of LLM outputs.
Large Language Models are Competitive Near Cold-start Recommenders for Language- and Item-based Preferences
Jul 26, 2023Traditional recommender systems leverage users' item preference history to recommend novel content that users may like. However, modern dialog interfaces that allow users to express language-based preferences offer a fundamentally different modality for preference input. Inspired by recent successes of prompting paradigms for large language models (LLMs), we study their use for making recommendations from both item-based and language-based preferences in comparison to state-of-the-art item-based collaborative filtering (CF) methods. To support this investigation, we collect a new dataset consisting of both item-based and language-based preferences elicited from users along with their ratings on a variety of (biased) recommended items and (unbiased) random items. Among numerous experimental results, we find that LLMs provide competitive recommendation performance for pure language-based preferences (no item preferences) in the near cold-start case in comparison to item-based CF methods, despite having no supervised training for this specific task (zero-shot) or only a few labels (few-shot). This is particularly promising as language-based preference representations are more explainable and scrutable than item-based or vector-based representations.
On Natural Language User Profiles for Transparent and Scrutable Recommendation
May 19, 2022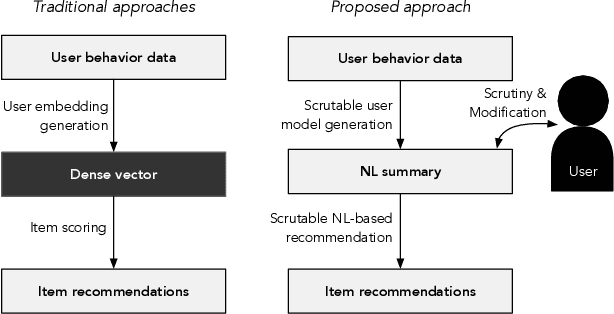



Natural interaction with recommendation and personalized search systems has received tremendous attention in recent years. We focus on the challenge of supporting people's understanding and control of these systems and explore a fundamentally new way of thinking about representation of knowledge in recommendation and personalization systems. Specifically, we argue that it may be both desirable and possible for algorithms that use natural language representations of users' preferences to be developed. We make the case that this could provide significantly greater transparency, as well as affordances for practical actionable interrogation of, and control over, recommendations. Moreover, we argue that such an approach, if successfully applied, may enable a major step towards systems that rely less on noisy implicit observations while increasing portability of knowledge of one's interests.
IMACS: Image Model Attribution Comparison Summaries
Jan 26, 2022



Developing a suitable Deep Neural Network (DNN) often requires significant iteration, where different model versions are evaluated and compared. While metrics such as accuracy are a powerful means to succinctly describe a model's performance across a dataset or to directly compare model versions, practitioners often wish to gain a deeper understanding of the factors that influence a model's predictions. Interpretability techniques such as gradient-based methods and local approximations can be used to examine small sets of inputs in fine detail, but it can be hard to determine if results from small sets generalize across a dataset. We introduce IMACS, a method that combines gradient-based model attributions with aggregation and visualization techniques to summarize differences in attributions between two DNN image models. More specifically, IMACS extracts salient input features from an evaluation dataset, clusters them based on similarity, then visualizes differences in model attributions for similar input features. In this work, we introduce a framework for aggregating, summarizing, and comparing the attribution information for two models across a dataset; present visualizations that highlight differences between 2 image classification models; and show how our technique can uncover behavioral differences caused by domain shift between two models trained on satellite images.
Guided Integrated Gradients: An Adaptive Path Method for Removing Noise
Jun 17, 2021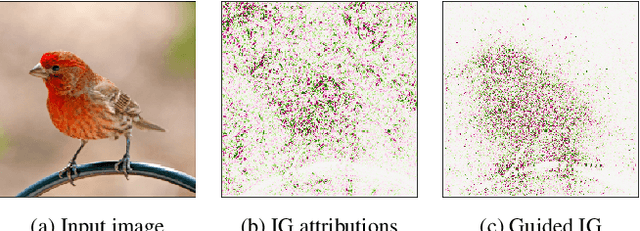
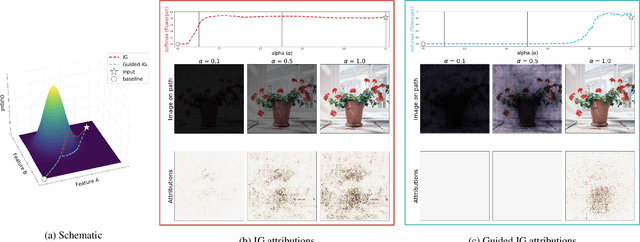
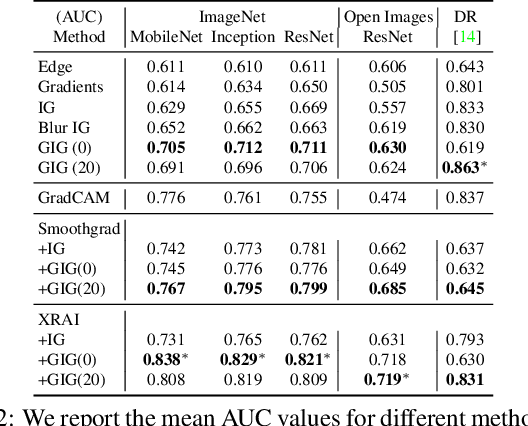
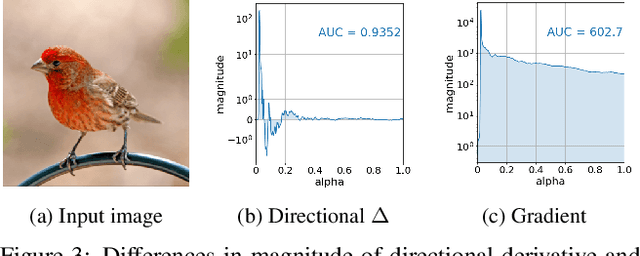
Integrated Gradients (IG) is a commonly used feature attribution method for deep neural networks. While IG has many desirable properties, the method often produces spurious/noisy pixel attributions in regions that are not related to the predicted class when applied to visual models. While this has been previously noted, most existing solutions are aimed at addressing the symptoms by explicitly reducing the noise in the resulting attributions. In this work, we show that one of the causes of the problem is the accumulation of noise along the IG path. To minimize the effect of this source of noise, we propose adapting the attribution path itself -- conditioning the path not just on the image but also on the model being explained. We introduce Adaptive Path Methods (APMs) as a generalization of path methods, and Guided IG as a specific instance of an APM. Empirically, Guided IG creates saliency maps better aligned with the model's prediction and the input image that is being explained. We show through qualitative and quantitative experiments that Guided IG outperforms other, related methods in nearly every experiment.
* 13 pages, 11 figures, for implementation sources see https://github.com/PAIR-code/saliency