 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho's asking? User personas and the mechanics of latent misalignment
Jun 17, 2024



Despite investments in improving model safety, studies show that misaligned capabilities remain latent in safety-tuned models. In this work, we shed light on the mechanics of this phenomenon. First, we show that even when model generations are safe, harmful content can persist in hidden representations and can be extracted by decoding from earlier layers. Then, we show that whether the model divulges such content depends significantly on its perception of who it is talking to, which we refer to as user persona. In fact, we find manipulating user persona to be even more effective for eliciting harmful content than direct attempts to control model refusal. We study both natural language prompting and activation steering as control methods and show that activation steering is significantly more effective at bypassing safety filters. We investigate why certain personas break model safeguards and find that they enable the model to form more charitable interpretations of otherwise dangerous queries. Finally, we show we can predict a persona's effect on refusal given only the geometry of its steering vector.
MOSPAT: AutoML based Model Selection and Parameter Tuning for Time Series Anomaly Detection
May 24, 2022
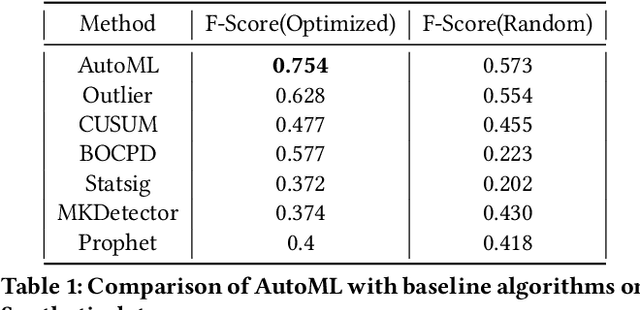
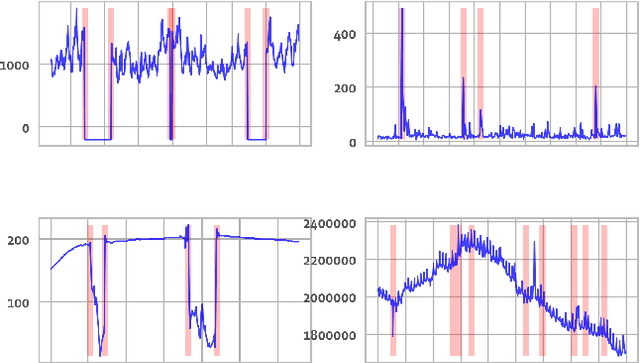
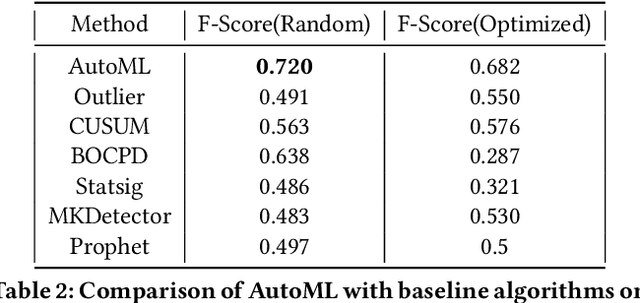
Organizations leverage anomaly and changepoint detection algorithms to detect changes in user behavior or service availability and performance. Many off-the-shelf detection algorithms, though effective, cannot readily be used in large organizations where thousands of users monitor millions of use cases and metrics with varied time series characteristics and anomaly patterns. The selection of algorithm and parameters needs to be precise for each use case: manual tuning does not scale, and automated tuning requires ground truth, which is rarely available. In this paper, we explore MOSPAT, an end-to-end automated machine learning based approach for model and parameter selection, combined with a generative model to produce labeled data. Our scalable end-to-end system allows individual users in large organizations to tailor time-series monitoring to their specific use case and data characteristics, without expert knowledge of anomaly detection algorithms or laborious manual labeling. Our extensive experiments on real and synthetic data demonstrate that this method consistently outperforms using any single algorithm.