 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Walk the Line: Examining the Role of Gestalt Continuity in Object Binding for Vision Transformers
Apr 10, 2026Object binding is a foundational process in visual cognition, during which low-level perceptual features are joined into object representations. Binding has been considered a fundamental challenge for neural networks, and a major milestone on the way to artificial models with flexible visual intelligence. Recently, several investigations have demonstrated evidence that binding mechanisms emerge in pretrained vision models, enabling them to associate portions of an image that contain an object. The question remains: how are these models binding objects together? In this work, we investigate whether vision models rely on the principle of Gestalt continuity to perform object binding, over and above other principles like similarity and proximity. Using synthetic datasets, we demonstrate that binding probes are sensitive to continuity across a wide range of pretrained vision transformers. Next, we uncover particular attention heads that track continuity, and show that these heads generalize across datasets. Finally, we ablate these attention heads, and show that they often contribute to producing representations that encode object binding.
Language Models Struggle to Use Representations Learned In-Context
Feb 04, 2026Though large language models (LLMs) have enabled great success across a wide variety of tasks, they still appear to fall short of one of the loftier goals of artificial intelligence research: creating an artificial system that can adapt its behavior to radically new contexts upon deployment. One important step towards this goal is to create systems that can induce rich representations of data that are seen in-context, and then flexibly deploy these representations to accomplish goals. Recently, Park et al. (2024) demonstrated that current LLMs are indeed capable of inducing such representation from context (i.e., in-context representation learning). The present study investigates whether LLMs can use these representations to complete simple downstream tasks. We first assess whether open-weights LLMs can use in-context representations for next-token prediction, and then probe models using a novel task, adaptive world modeling. In both tasks, we find evidence that open-weights LLMs struggle to deploy representations of novel semantics that are defined in-context, even if they encode these semantics in their latent representations. Furthermore, we assess closed-source, state-of-the-art reasoning models on the adaptive world modeling task, demonstrating that even the most performant LLMs cannot reliably leverage novel patterns presented in-context. Overall, this work seeks to inspire novel methods for encouraging models to not only encode information presented in-context, but to do so in a manner that supports flexible deployment of this information.
Linking forward-pass dynamics in Transformers and real-time human processing
Apr 18, 2025Modern AI models are increasingly being used as theoretical tools to study human cognition. One dominant approach is to evaluate whether human-derived measures (such as offline judgments or real-time processing) are predicted by a model's output: that is, the end-product of forward pass(es) through the network. At the same time, recent advances in mechanistic interpretability have begun to reveal the internal processes that give rise to model outputs, raising the question of whether models and humans might arrive at outputs using similar "processing strategies". Here, we investigate the link between real-time processing in humans and "layer-time" dynamics in Transformer models. Across five studies spanning domains and modalities, we test whether the dynamics of computation in a single forward pass of pre-trained Transformers predict signatures of processing in humans, above and beyond properties of the model's output probability distribution. We consistently find that layer-time dynamics provide additional predictive power on top of output measures. Our results suggest that Transformer processing and human processing may be facilitated or impeded by similar properties of an input stimulus, and this similarity has emerged through general-purpose objectives such as next-token prediction or image recognition. Our work suggests a new way of using AI models to study human cognition: not just as a black box mapping stimuli to responses, but potentially also as explicit processing models.
Are LLMs Models of Distributional Semantics? A Case Study on Quantifiers
Oct 17, 2024



Distributional semantics is the linguistic theory that a word's meaning can be derived from its distribution in natural language (i.e., its use). Language models are commonly viewed as an implementation of distributional semantics, as they are optimized to capture the statistical features of natural language. It is often argued that distributional semantics models should excel at capturing graded/vague meaning based on linguistic conventions, but struggle with truth-conditional reasoning and symbolic processing. We evaluate this claim with a case study on vague (e.g. "many") and exact (e.g. "more than half") quantifiers. Contrary to expectations, we find that, across a broad range of models of various types, LLMs align more closely with human judgements on exact quantifiers versus vague ones. These findings call for a re-evaluation of the assumptions underpinning what distributional semantics models are, as well as what they can capture.
Racing Thoughts: Explaining Large Language Model Contextualization Errors
Oct 02, 2024



The profound success of transformer-based language models can largely be attributed to their ability to integrate relevant contextual information from an input sequence in order to generate a response or complete a task. However, we know very little about the algorithms that a model employs to implement this capability, nor do we understand their failure modes. For example, given the prompt "John is going fishing, so he walks over to the bank. Can he make an ATM transaction?", a model may incorrectly respond "Yes" if it has not properly contextualized "bank" as a geographical feature, rather than a financial institution. We propose the LLM Race Conditions Hypothesis as an explanation of contextualization errors of this form. This hypothesis identifies dependencies between tokens (e.g., "bank" must be properly contextualized before the final token, "?", integrates information from "bank"), and claims that contextualization errors are a result of violating these dependencies. Using a variety of techniques from mechanistic intepretability, we provide correlational and causal evidence in support of the hypothesis, and suggest inference-time interventions to address it.
Beyond the Doors of Perception: Vision Transformers Represent Relations Between Objects
Jun 22, 2024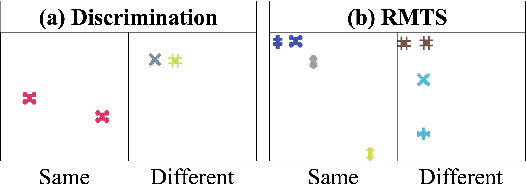
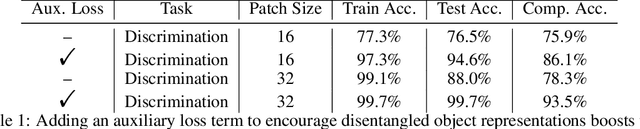
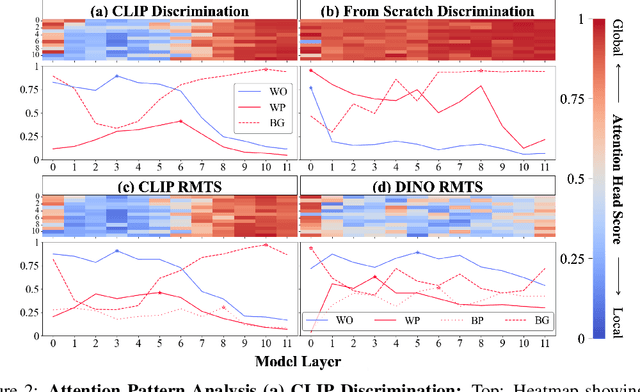
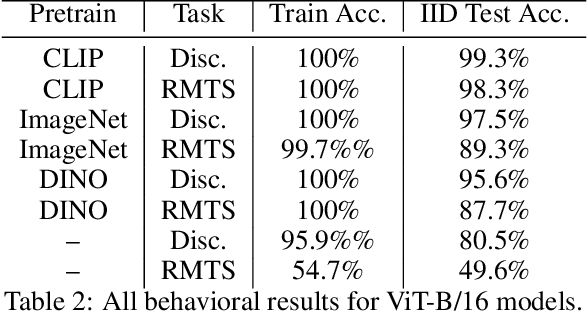
Though vision transformers (ViTs) have achieved state-of-the-art performance in a variety of settings, they exhibit surprising failures when performing tasks involving visual relations. This begs the question: how do ViTs attempt to perform tasks that require computing visual relations between objects? Prior efforts to interpret ViTs tend to focus on characterizing relevant low-level visual features. In contrast, we adopt methods from mechanistic interpretability to study the higher-level visual algorithms that ViTs use to perform abstract visual reasoning. We present a case study of a fundamental, yet surprisingly difficult, relational reasoning task: judging whether two visual entities are the same or different. We find that pretrained ViTs fine-tuned on this task often exhibit two qualitatively different stages of processing despite having no obvious inductive biases to do so: 1) a perceptual stage wherein local object features are extracted and stored in a disentangled representation, and 2) a relational stage wherein object representations are compared. In the second stage, we find evidence that ViTs can learn to represent somewhat abstract visual relations, a capability that has long been considered out of reach for artificial neural networks. Finally, we demonstrate that failure points at either stage can prevent a model from learning a generalizable solution to our fairly simple tasks. By understanding ViTs in terms of discrete processing stages, one can more precisely diagnose and rectify shortcomings of existing and future models.
Who's asking? User personas and the mechanics of latent misalignment
Jun 17, 2024



Despite investments in improving model safety, studies show that misaligned capabilities remain latent in safety-tuned models. In this work, we shed light on the mechanics of this phenomenon. First, we show that even when model generations are safe, harmful content can persist in hidden representations and can be extracted by decoding from earlier layers. Then, we show that whether the model divulges such content depends significantly on its perception of who it is talking to, which we refer to as user persona. In fact, we find manipulating user persona to be even more effective for eliciting harmful content than direct attempts to control model refusal. We study both natural language prompting and activation steering as control methods and show that activation steering is significantly more effective at bypassing safety filters. We investigate why certain personas break model safeguards and find that they enable the model to form more charitable interpretations of otherwise dangerous queries. Finally, we show we can predict a persona's effect on refusal given only the geometry of its steering vector.
Dual Process Learning: Controlling Use of In-Context vs. In-Weights Strategies with Weight Forgetting
May 28, 2024



Language models have the ability to perform in-context learning (ICL), allowing them to flexibly adapt their behavior based on context. This contrasts with in-weights learning, where information is statically encoded in model parameters from iterated observations of the data. Despite this apparent ability to learn in-context, language models are known to struggle when faced with unseen or rarely seen tokens. Hence, we study $\textbf{structural in-context learning}$, which we define as the ability of a model to execute in-context learning on arbitrary tokens -- so called because the model must generalize on the basis of e.g. sentence structure or task structure, rather than semantic content encoded in token embeddings. An ideal model would be able to do both: flexibly deploy in-weights operations (in order to robustly accommodate ambiguous or unknown contexts using encoded semantic information) and structural in-context operations (in order to accommodate novel tokens). We study structural in-context algorithms in a simple part-of-speech setting using both practical and toy models. We find that active forgetting, a technique that was recently introduced to help models generalize to new languages, forces models to adopt structural in-context learning solutions. Finally, we introduce $\textbf{temporary forgetting}$, a straightforward extension of active forgetting that enables one to control how much a model relies on in-weights vs. in-context solutions. Importantly, temporary forgetting allows us to induce a $\textit{dual process strategy}$ where in-context and in-weights solutions coexist within a single model.
Uncovering Intermediate Variables in Transformers using Circuit Probing
Nov 17, 2023Neural network models have achieved high performance on a wide variety of complex tasks, but the algorithms that they implement are notoriously difficult to interpret. In order to understand these algorithms, it is often necessary to hypothesize intermediate variables involved in the network's computation. For example, does a language model depend on particular syntactic properties when generating a sentence? However, existing analysis tools make it difficult to test hypotheses of this type. We propose a new analysis technique -- circuit probing -- that automatically uncovers low-level circuits that compute hypothesized intermediate variables. This enables causal analysis through targeted ablation at the level of model parameters. We apply this method to models trained on simple arithmetic tasks, demonstrating its effectiveness at (1) deciphering the algorithms that models have learned, (2) revealing modular structure within a model, and (3) tracking the development of circuits over training. We compare circuit probing to other methods across these three experiments, and find it on par or more effective than existing analysis methods. Finally, we demonstrate circuit probing on a real-world use case, uncovering circuits that are responsible for subject-verb agreement and reflexive anaphora in GPT2-Small and Medium.
Instilling Inductive Biases with Subnetworks
Oct 17, 2023Despite the recent success of artificial neural networks on a variety of tasks, we have little knowledge or control over the exact solutions these models implement. Instilling inductive biases -- preferences for some solutions over others -- into these models is one promising path toward understanding and controlling their behavior. Much work has been done to study the inherent inductive biases of models and instill different inductive biases through hand-designed architectures or carefully curated training regimens. In this work, we explore a more mechanistic approach: Subtask Induction. Our method discovers a functional subnetwork that implements a particular subtask within a trained model and uses it to instill inductive biases towards solutions utilizing that subtask. Subtask Induction is flexible and efficient, and we demonstrate its effectiveness with two experiments. First, we show that Subtask Induction significantly reduces the amount of training data required for a model to adopt a specific, generalizable solution to a modular arithmetic task. Second, we demonstrate that Subtask Induction successfully induces a human-like shape bias while increasing data efficiency for convolutional and transformer-based image classification models.