 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Doors of Perception: Vision Transformers Represent Relations Between Objects
Paper and Code
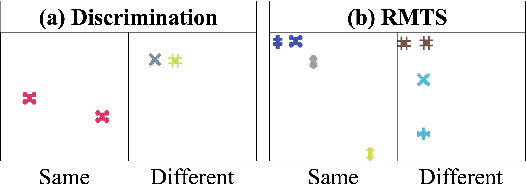
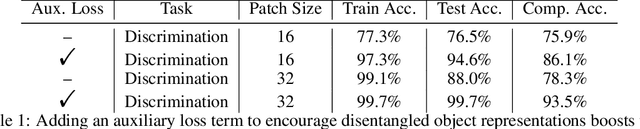
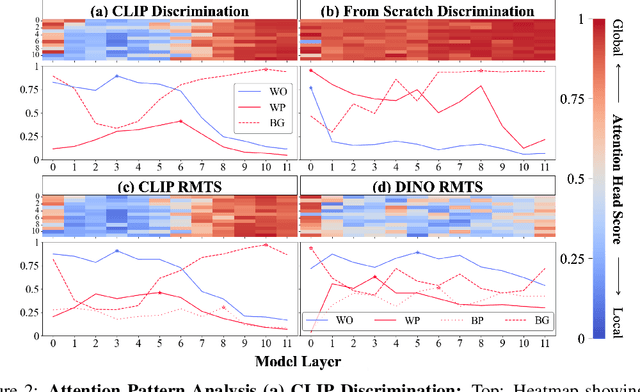
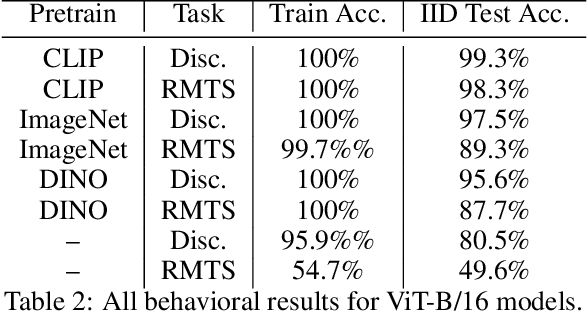
Though vision transformers (ViTs) have achieved state-of-the-art performance in a variety of settings, they exhibit surprising failures when performing tasks involving visual relations. This begs the question: how do ViTs attempt to perform tasks that require computing visual relations between objects? Prior efforts to interpret ViTs tend to focus on characterizing relevant low-level visual features. In contrast, we adopt methods from mechanistic interpretability to study the higher-level visual algorithms that ViTs use to perform abstract visual reasoning. We present a case study of a fundamental, yet surprisingly difficult, relational reasoning task: judging whether two visual entities are the same or different. We find that pretrained ViTs fine-tuned on this task often exhibit two qualitatively different stages of processing despite having no obvious inductive biases to do so: 1) a perceptual stage wherein local object features are extracted and stored in a disentangled representation, and 2) a relational stage wherein object representations are compared. In the second stage, we find evidence that ViTs can learn to represent somewhat abstract visual relations, a capability that has long been considered out of reach for artificial neural networks. Finally, we demonstrate that failure points at either stage can prevent a model from learning a generalizable solution to our fairly simple tasks. By understanding ViTs in terms of discrete processing stages, one can more precisely diagnose and rectify shortcomings of existing and future models.