 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning Without Copying
Nov 07, 2025Induction heads are attention heads that perform inductive copying by matching patterns from earlier context and copying their continuations verbatim. As models develop induction heads, they often experience a sharp drop in training loss, a phenomenon cited as evidence that induction heads may serve as a prerequisite for more complex in-context learning (ICL) capabilities. In this work, we ask whether transformers can still acquire ICL capabilities when inductive copying is suppressed. We propose Hapax, a setting where we omit the loss contribution of any token that can be correctly predicted by induction heads. Despite a significant reduction in inductive copying, performance on abstractive ICL tasks (i.e., tasks where the answer is not contained in the input context) remains comparable and surpasses the vanilla model on 13 of 21 tasks, even though 31.7\% of tokens are omitted from the loss. Furthermore, our model achieves lower loss values on token positions that cannot be predicted correctly by induction heads. Mechanistic analysis further shows that models trained with Hapax develop fewer and weaker induction heads but still preserve ICL capabilities. Taken together, our findings indicate that inductive copying is not essential for learning abstractive ICL mechanisms.
Erasing Conceptual Knowledge from Language Models
Oct 03, 2024Concept erasure in language models has traditionally lacked a comprehensive evaluation framework, leading to incomplete assessments of effectiveness of erasure methods. We propose an evaluation paradigm centered on three critical criteria: innocence (complete knowledge removal), seamlessness (maintaining conditional fluent generation), and specificity (preserving unrelated task performance). Our evaluation metrics naturally motivate the development of Erasure of Language Memory (ELM), a new method designed to address all three dimensions. ELM employs targeted low-rank updates to alter output distributions for erased concepts while preserving overall model capabilities including fluency when prompted for an erased concept. We demonstrate ELM's efficacy on biosecurity, cybersecurity, and literary domain erasure tasks. Comparative analysis shows that ELM achieves superior performance across our proposed metrics, including near-random scores on erased topic assessments, generation fluency, maintained accuracy on unrelated benchmarks, and robustness under adversarial attacks. Our code, data, and trained models are available at https://elm.baulab.info
Token Erasure as a Footprint of Implicit Vocabulary Items in LLMs
Jun 28, 2024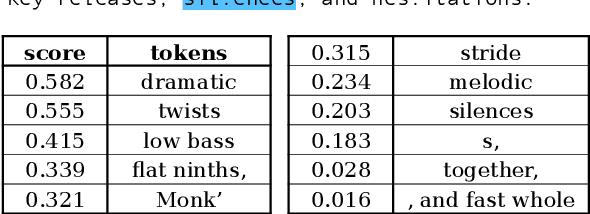
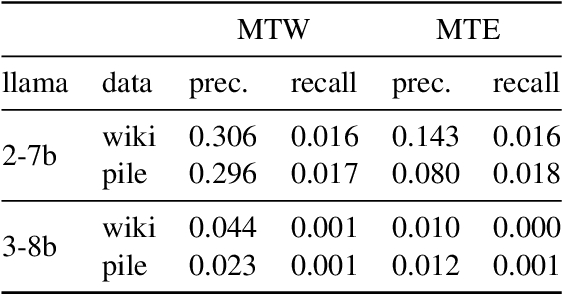
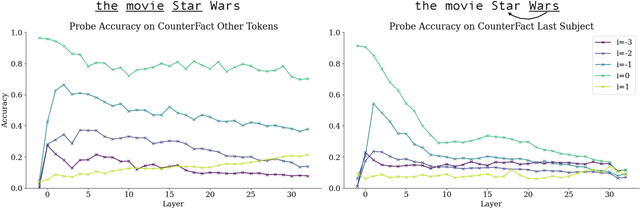
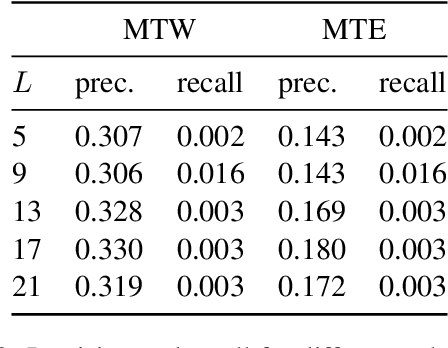
LLMs process text as sequences of tokens that roughly correspond to words, where less common words are represented by multiple tokens. However, individual tokens are often semantically unrelated to the meanings of the words/concepts they comprise. For example, Llama-2-7b's tokenizer splits the word "northeastern" into the tokens ['_n', 'ort', 'he', 'astern'], none of which correspond to semantically meaningful units like "north" or "east." Similarly, the overall meanings of named entities like "Neil Young" and multi-word expressions like "break a leg" cannot be directly inferred from their constituent tokens. Mechanistically, how do LLMs convert such arbitrary groups of tokens into useful higher-level representations? In this work, we find that last token representations of named entities and multi-token words exhibit a pronounced "erasure" effect, where information about previous and current tokens is rapidly forgotten in early layers. Using this observation, we propose a method to "read out" the implicit vocabulary of an autoregressive LLM by examining differences in token representations across layers, and present results of this method for Llama-2-7b and Llama-3-8B. To our knowledge, this is the first attempt to probe the implicit vocabulary of an LLM.
Deep Neural Networks Can Learn Generalizable Same-Different Visual Relations
Oct 14, 2023



Although deep neural networks can achieve human-level performance on many object recognition benchmarks, prior work suggests that these same models fail to learn simple abstract relations, such as determining whether two objects are the same or different. Much of this prior work focuses on training convolutional neural networks to classify images of two same or two different abstract shapes, testing generalization on within-distribution stimuli. In this article, we comprehensively study whether deep neural networks can acquire and generalize same-different relations both within and out-of-distribution using a variety of architectures, forms of pretraining, and fine-tuning datasets. We find that certain pretrained transformers can learn a same-different relation that generalizes with near perfect accuracy to out-of-distribution stimuli. Furthermore, we find that fine-tuning on abstract shapes that lack texture or color provides the strongest out-of-distribution generalization. Our results suggest that, with the right approach, deep neural networks can learn generalizable same-different visual relations.
NEWTS: A Corpus for News Topic-Focused Summarization
May 31, 2022

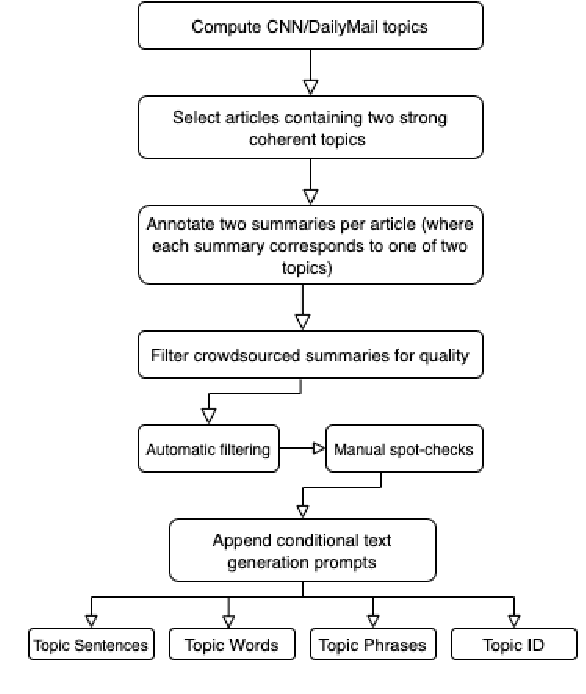
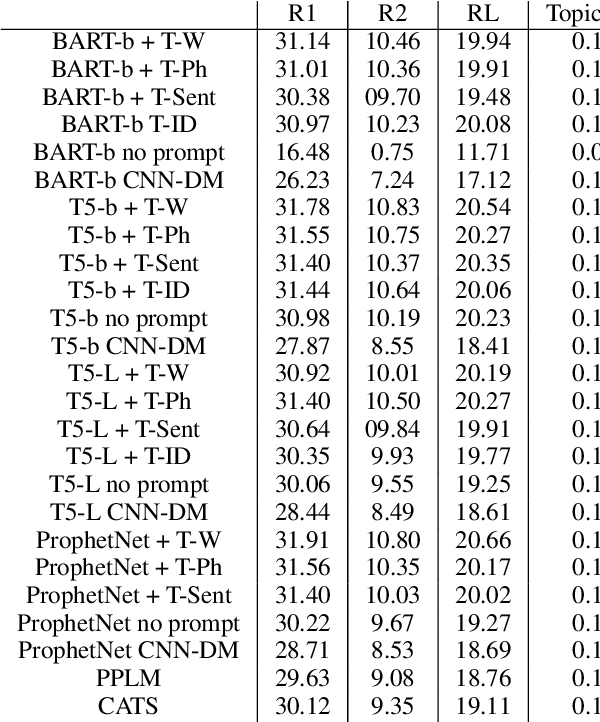
Text summarization models are approaching human levels of fidelity. Existing benchmarking corpora provide concordant pairs of full and abridged versions of Web, news or, professional content. To date, all summarization datasets operate under a one-size-fits-all paradigm that may not reflect the full range of organic summarization needs. Several recently proposed models (e.g., plug and play language models) have the capacity to condition the generated summaries on a desired range of themes. These capacities remain largely unused and unevaluated as there is no dedicated dataset that would support the task of topic-focused summarization. This paper introduces the first topical summarization corpus NEWTS, based on the well-known CNN/Dailymail dataset, and annotated via online crowd-sourcing. Each source article is paired with two reference summaries, each focusing on a different theme of the source document. We evaluate a representative range of existing techniques and analyze the effectiveness of different prompting methods.
A Novel Corpus of Discourse Structure in Humans and Computers
Nov 10, 2021We present a novel corpus of 445 human- and computer-generated documents, comprising about 27,000 clauses, annotated for semantic clause types and coherence relations that allow for nuanced comparison of artificial and natural discourse modes. The corpus covers both formal and informal discourse, and contains documents generated using fine-tuned GPT-2 (Zellers et al., 2019) and GPT-3(Brown et al., 2020). We showcase the usefulness of this corpus for detailed discourse analysis of text generation by providing preliminary evidence that less numerous, shorter and more often incoherent clause relations are associated with lower perceived quality of computer-generated narratives and arguments.