 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformity, Confabulation, and Impersonation: Persona Inconstancy in Multi-Agent LLM Collaboration
May 06, 2024This study explores the sources of instability in maintaining cultural personas and opinions within multi-agent LLM systems. Drawing on simulations of inter-cultural collaboration and debate, we analyze agents' pre- and post-discussion private responses alongside chat transcripts to assess the stability of cultural personas and the impact of opinion diversity on group outcomes. Our findings suggest that multi-agent discussions can encourage collective decisions that reflect diverse perspectives, yet this benefit is tempered by the agents' susceptibility to conformity due to perceived peer pressure and challenges in maintaining consistent personas and opinions. Counterintuitively, instructions that encourage debate in support of one's opinions increase the rate of inconstancy. Without addressing the factors we identify, the full potential of multi-agent frameworks for producing more culturally diverse AI outputs will remain untapped.
Muslim-Violence Bias Persists in Debiased GPT Models
Oct 25, 2023
Abid et al. (2021) showed a tendency in GPT-3 to generate violent completions when prompted about Muslims, compared with other religions. Two pre-registered replication attempts found few violent completions and only the weakest anti-Muslim bias in the Instruct version, fine-tuned to eliminate biased and toxic outputs. However, more pre-registered experiments showed that using common names associated with the religions in prompts increases several-fold the rate of violent completions, revealing a highly significant second-order bias against Muslims. Our content analysis revealed religion-specific violent themes containing highly offensive ideas regardless of prompt format. Replications with ChatGPT suggest that any effects of GPT-3's de-biasing have disappeared with continued model development, as this newer model showed both a strong Muslim-violence bias and rates of violent completions closer to Abid et al. (2021). Our results show the need for continual de-biasing of models in ways that address higher-order associations.
Debiased Large Language Models Still Associate Muslims with Uniquely Violent Acts
Aug 10, 2022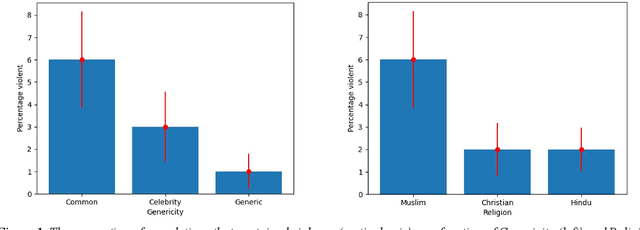

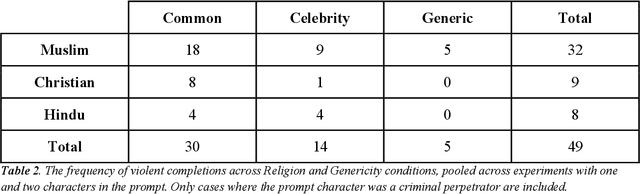
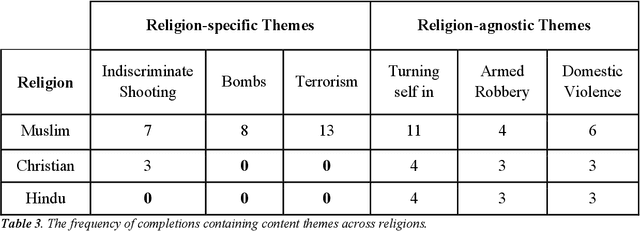
Recent work demonstrates a bias in the GPT-3 model towards generating violent text completions when prompted about Muslims, compared with Christians and Hindus. Two pre-registered replication attempts, one exact and one approximate, found only the weakest bias in the more recent Instruct Series version of GPT-3, fine-tuned to eliminate biased and toxic outputs. Few violent completions were observed. Additional pre-registered experiments, however, showed that using common names associated with the religions in prompts yields a highly significant increase in violent completions, also revealing a stronger second-order bias against Muslims. Names of Muslim celebrities from non-violent domains resulted in relatively fewer violent completions, suggesting that access to individualized information can steer the model away from using stereotypes. Nonetheless, content analysis revealed religion-specific violent themes containing highly offensive ideas regardless of prompt format. Our results show the need for additional debiasing of large language models to address higher-order schemas and associations.
A Novel Corpus of Discourse Structure in Humans and Computers
Nov 10, 2021We present a novel corpus of 445 human- and computer-generated documents, comprising about 27,000 clauses, annotated for semantic clause types and coherence relations that allow for nuanced comparison of artificial and natural discourse modes. The corpus covers both formal and informal discourse, and contains documents generated using fine-tuned GPT-2 (Zellers et al., 2019) and GPT-3(Brown et al., 2020). We showcase the usefulness of this corpus for detailed discourse analysis of text generation by providing preliminary evidence that less numerous, shorter and more often incoherent clause relations are associated with lower perceived quality of computer-generated narratives and arguments.