 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGathering Strength, Gathering Storms: The One Hundred Year Study on Artificial Intelligence (AI100) 2021 Study Panel Report
Oct 27, 2022In September 2021, the "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the second report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Michael Littman of Brown University. The report, entitled "Gathering Strength, Gathering Storms," answers a set of 14 questions probing critical areas of AI development addressing the major risks and dangers of AI, its effects on society, its public perception and the future of the field. The report concludes that AI has made a major leap from the lab to people's lives in recent years, which increases the urgency to understand its potential negative effects. The questions were developed by the AI100 Standing Committee, chaired by Peter Stone of the University of Texas at Austin, consisting of a group of AI leaders with expertise in computer science, sociology, ethics, economics, and other disciplines.
A Novel Corpus of Discourse Structure in Humans and Computers
Nov 10, 2021We present a novel corpus of 445 human- and computer-generated documents, comprising about 27,000 clauses, annotated for semantic clause types and coherence relations that allow for nuanced comparison of artificial and natural discourse modes. The corpus covers both formal and informal discourse, and contains documents generated using fine-tuned GPT-2 (Zellers et al., 2019) and GPT-3(Brown et al., 2020). We showcase the usefulness of this corpus for detailed discourse analysis of text generation by providing preliminary evidence that less numerous, shorter and more often incoherent clause relations are associated with lower perceived quality of computer-generated narratives and arguments.
Using Human-Guided Causal Knowledge for More Generalized Robot Task Planning
Oct 09, 2021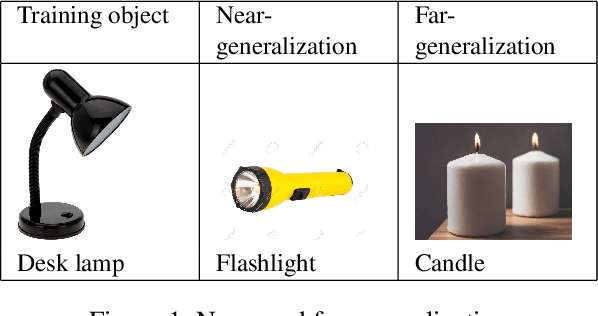
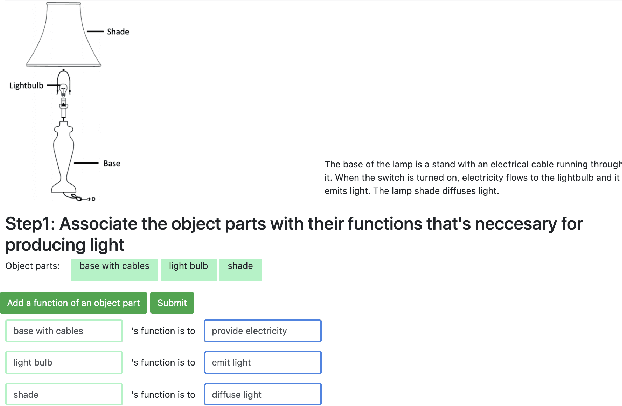
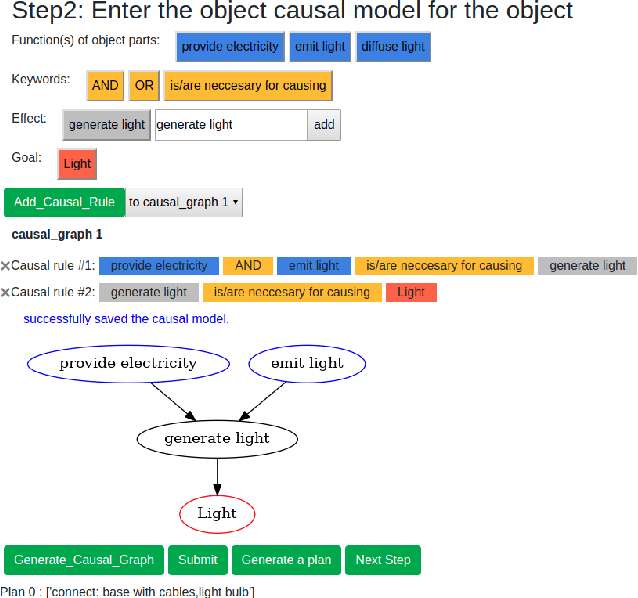
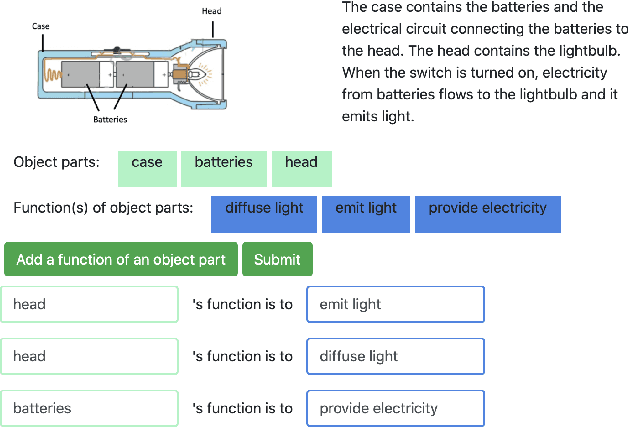
A major challenge in research involving artificial intelligence (AI) is the development of algorithms that can find solutions to problems that can generalize to different environments and tasks. Unlike AI, humans are adept at finding solutions that can transfer. We hypothesize this is because their solutions are informed by causal models. We propose to use human-guided causal knowledge to help robots find solutions that can generalize to a new environment. We develop and test the feasibility of a language interface that na\"ive participants can use to communicate these causal models to a planner. We find preliminary evidence that participants are able to use our interface and generate causal models that achieve near-generalization. We outline an experiment aimed at testing far-generalization using our interface and describe our longer terms goals for these causal models.