 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternational AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Predicting Artificial Neural Network Representations to Learn Recognition Model for Music Identification from Brain Recordings
Dec 20, 2024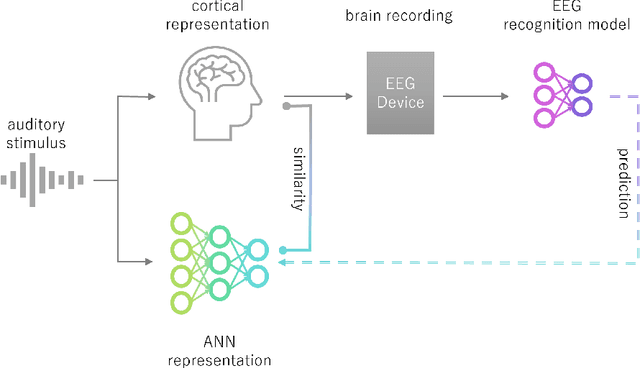
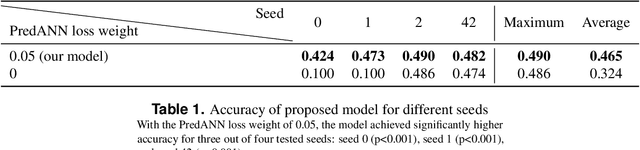
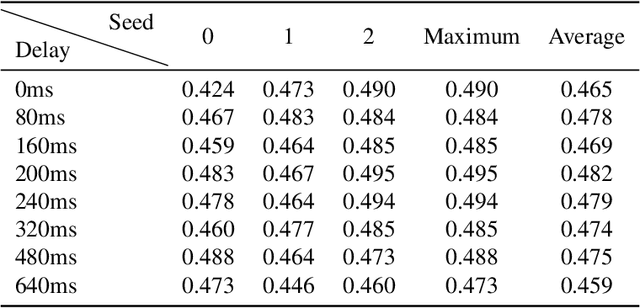
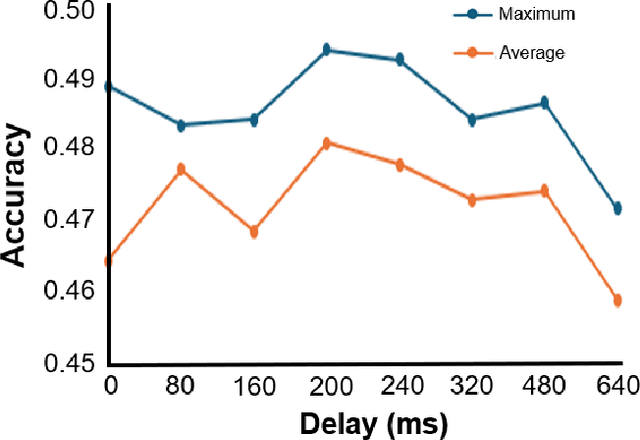
Recent studies have demonstrated that the representations of artificial neural networks (ANNs) can exhibit notable similarities to cortical representations when subjected to identical auditory sensory inputs. In these studies, the ability to predict cortical representations is probed by regressing from ANN representations to cortical representations. Building upon this concept, our approach reverses the direction of prediction: we utilize ANN representations as a supervisory signal to train recognition models using noisy brain recordings obtained through non-invasive measurements. Specifically, we focus on constructing a recognition model for music identification, where electroencephalography (EEG) brain recordings collected during music listening serve as input. By training an EEG recognition model to predict ANN representations-representations associated with music identification-we observed a substantial improvement in classification accuracy. This study introduces a novel approach to developing recognition models for brain recordings in response to external auditory stimuli. It holds promise for advancing brain-computer interfaces (BCI), neural decoding techniques, and our understanding of music cognition. Furthermore, it provides new insights into the relationship between auditory brain activity and ANN representations.
Naturalistic Music Decoding from EEG Data via Latent Diffusion Models
May 17, 2024In this article, we explore the potential of using latent diffusion models, a family of powerful generative models, for the task of reconstructing naturalistic music from electroencephalogram (EEG) recordings. Unlike simpler music with limited timbres, such as MIDI-generated tunes or monophonic pieces, the focus here is on intricate music featuring a diverse array of instruments, voices, and effects, rich in harmonics and timbre. This study represents an initial foray into achieving general music reconstruction of high-quality using non-invasive EEG data, employing an end-to-end training approach directly on raw data without the need for manual pre-processing and channel selection. We train our models on the public NMED-T dataset and perform quantitative evaluation proposing neural embedding-based metrics. We additionally perform song classification based on the generated tracks. Our work contributes to the ongoing research in neural decoding and brain-computer interfaces, offering insights into the feasibility of using EEG data for complex auditory information reconstruction.
The Future of Fundamental Science Led by Generative Closed-Loop Artificial Intelligence
Jul 09, 2023



Recent advances in machine learning and AI, including Generative AI and LLMs, are disrupting technological innovation, product development, and society as a whole. AI's contribution to technology can come from multiple approaches that require access to large training data sets and clear performance evaluation criteria, ranging from pattern recognition and classification to generative models. Yet, AI has contributed less to fundamental science in part because large data sets of high-quality data for scientific practice and model discovery are more difficult to access. Generative AI, in general, and Large Language Models in particular, may represent an opportunity to augment and accelerate the scientific discovery of fundamental deep science with quantitative models. Here we explore and investigate aspects of an AI-driven, automated, closed-loop approach to scientific discovery, including self-driven hypothesis generation and open-ended autonomous exploration of the hypothesis space. Integrating AI-driven automation into the practice of science would mitigate current problems, including the replication of findings, systematic production of data, and ultimately democratisation of the scientific process. Realising these possibilities requires a vision for augmented AI coupled with a diversity of AI approaches able to deal with fundamental aspects of causality analysis and model discovery while enabling unbiased search across the space of putative explanations. These advances hold the promise to unleash AI's potential for searching and discovering the fundamental structure of our world beyond what human scientists have been able to achieve. Such a vision would push the boundaries of new fundamental science rather than automatize current workflows and instead open doors for technological innovation to tackle some of the greatest challenges facing humanity today.
Self-supervised Auxiliary Loss for Metric Learning in Music Similarity-based Retrieval and Auto-tagging
Apr 15, 2023



In the realm of music information retrieval, similarity-based retrieval and auto-tagging serve as essential components. Given the limitations and non-scalability of human supervision signals, it becomes crucial for models to learn from alternative sources to enhance their performance. Self-supervised learning, which exclusively relies on learning signals derived from music audio data, has demonstrated its efficacy in the context of auto-tagging. In this study, we propose a model that builds on the self-supervised learning approach to address the similarity-based retrieval challenge by introducing our method of metric learning with a self-supervised auxiliary loss. Furthermore, diverging from conventional self-supervised learning methodologies, we discovered the advantages of concurrently training the model with both self-supervision and supervision signals, without freezing pre-trained models. We also found that refraining from employing augmentation during the fine-tuning phase yields better results. Our experimental results confirm that the proposed methodology enhances retrieval and tagging performance metrics in two distinct scenarios: one where human-annotated tags are consistently available for all music tracks, and another where such tags are accessible only for a subset of tracks.
Gathering Strength, Gathering Storms: The One Hundred Year Study on Artificial Intelligence (AI100) 2021 Study Panel Report
Oct 27, 2022In September 2021, the "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the second report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Michael Littman of Brown University. The report, entitled "Gathering Strength, Gathering Storms," answers a set of 14 questions probing critical areas of AI development addressing the major risks and dangers of AI, its effects on society, its public perception and the future of the field. The report concludes that AI has made a major leap from the lab to people's lives in recent years, which increases the urgency to understand its potential negative effects. The questions were developed by the AI100 Standing Committee, chaired by Peter Stone of the University of Texas at Austin, consisting of a group of AI leaders with expertise in computer science, sociology, ethics, economics, and other disciplines.