 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePF-D2M: A Pose-free Diffusion Model for Universal Dance-to-Music Generation
Jan 22, 2026Dance-to-music generation aims to generate music that is aligned with dance movements. Existing approaches typically rely on body motion features extracted from a single human dancer and limited dance-to-music datasets, which restrict their performance and applicability to real-world scenarios involving multiple dancers and non-human dancers. In this paper, we propose PF-D2M, a universal diffusion-based dance-to-music generation model that incorporates visual features extracted from dance videos. PF-D2M is trained with a progressive training strategy that effectively addresses data scarcity and generalization challenges. Both objective and subjective evaluations show that PF-D2M achieves state-of-the-art performance in dance-music alignment and music quality.
Predicting Artificial Neural Network Representations to Learn Recognition Model for Music Identification from Brain Recordings
Dec 20, 2024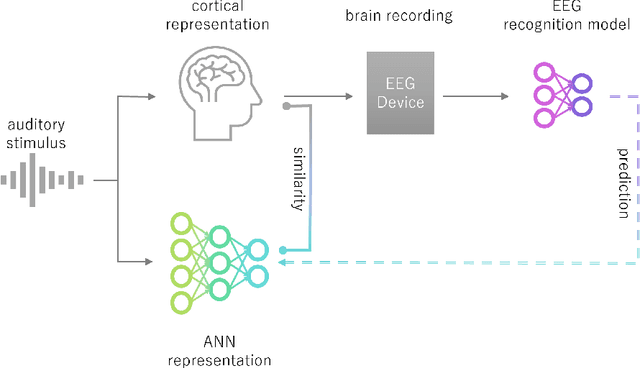
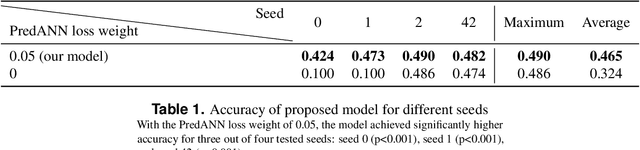
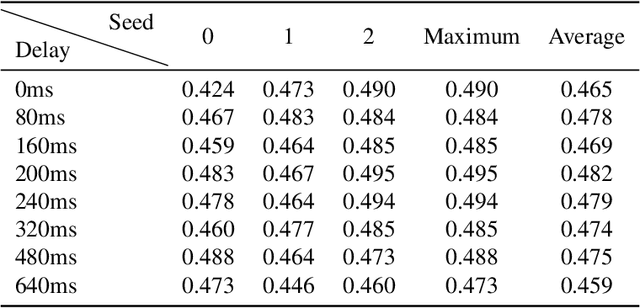
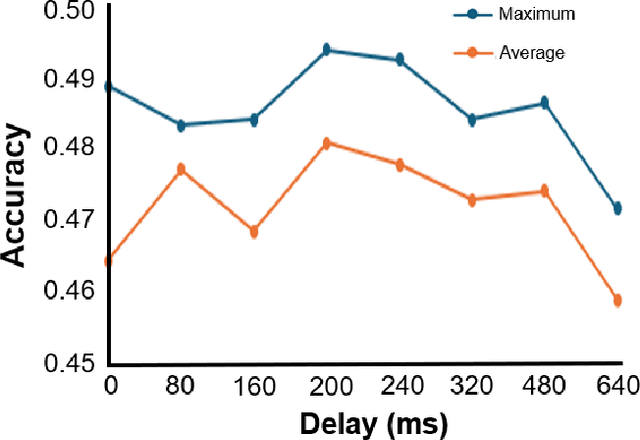
Recent studies have demonstrated that the representations of artificial neural networks (ANNs) can exhibit notable similarities to cortical representations when subjected to identical auditory sensory inputs. In these studies, the ability to predict cortical representations is probed by regressing from ANN representations to cortical representations. Building upon this concept, our approach reverses the direction of prediction: we utilize ANN representations as a supervisory signal to train recognition models using noisy brain recordings obtained through non-invasive measurements. Specifically, we focus on constructing a recognition model for music identification, where electroencephalography (EEG) brain recordings collected during music listening serve as input. By training an EEG recognition model to predict ANN representations-representations associated with music identification-we observed a substantial improvement in classification accuracy. This study introduces a novel approach to developing recognition models for brain recordings in response to external auditory stimuli. It holds promise for advancing brain-computer interfaces (BCI), neural decoding techniques, and our understanding of music cognition. Furthermore, it provides new insights into the relationship between auditory brain activity and ANN representations.
Naturalistic Music Decoding from EEG Data via Latent Diffusion Models
May 17, 2024In this article, we explore the potential of using latent diffusion models, a family of powerful generative models, for the task of reconstructing naturalistic music from electroencephalogram (EEG) recordings. Unlike simpler music with limited timbres, such as MIDI-generated tunes or monophonic pieces, the focus here is on intricate music featuring a diverse array of instruments, voices, and effects, rich in harmonics and timbre. This study represents an initial foray into achieving general music reconstruction of high-quality using non-invasive EEG data, employing an end-to-end training approach directly on raw data without the need for manual pre-processing and channel selection. We train our models on the public NMED-T dataset and perform quantitative evaluation proposing neural embedding-based metrics. We additionally perform song classification based on the generated tracks. Our work contributes to the ongoing research in neural decoding and brain-computer interfaces, offering insights into the feasibility of using EEG data for complex auditory information reconstruction.
Self-supervised Auxiliary Loss for Metric Learning in Music Similarity-based Retrieval and Auto-tagging
Apr 15, 2023In the realm of music information retrieval, similarity-based retrieval and auto-tagging serve as essential components. Given the limitations and non-scalability of human supervision signals, it becomes crucial for models to learn from alternative sources to enhance their performance. Self-supervised learning, which exclusively relies on learning signals derived from music audio data, has demonstrated its efficacy in the context of auto-tagging. In this study, we propose a model that builds on the self-supervised learning approach to address the similarity-based retrieval challenge by introducing our method of metric learning with a self-supervised auxiliary loss. Furthermore, diverging from conventional self-supervised learning methodologies, we discovered the advantages of concurrently training the model with both self-supervision and supervision signals, without freezing pre-trained models. We also found that refraining from employing augmentation during the fine-tuning phase yields better results. Our experimental results confirm that the proposed methodology enhances retrieval and tagging performance metrics in two distinct scenarios: one where human-annotated tags are consistently available for all music tracks, and another where such tags are accessible only for a subset of tracks.