 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Human-Guided Causal Knowledge for More Generalized Robot Task Planning
Oct 09, 2021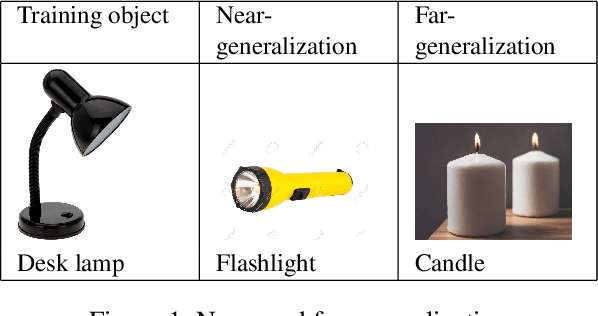
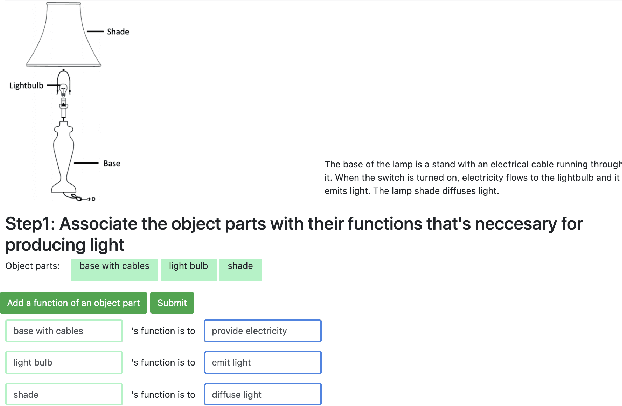
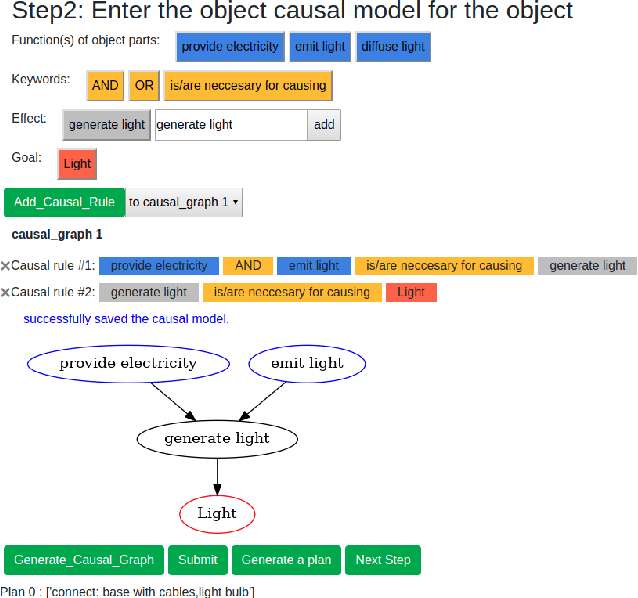
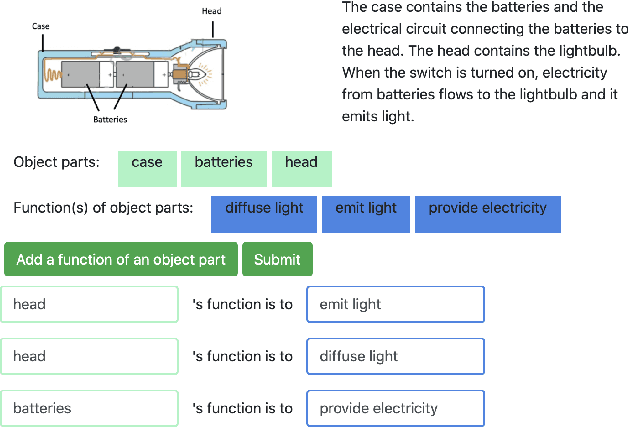
A major challenge in research involving artificial intelligence (AI) is the development of algorithms that can find solutions to problems that can generalize to different environments and tasks. Unlike AI, humans are adept at finding solutions that can transfer. We hypothesize this is because their solutions are informed by causal models. We propose to use human-guided causal knowledge to help robots find solutions that can generalize to a new environment. We develop and test the feasibility of a language interface that na\"ive participants can use to communicate these causal models to a planner. We find preliminary evidence that participants are able to use our interface and generate causal models that achieve near-generalization. We outline an experiment aimed at testing far-generalization using our interface and describe our longer terms goals for these causal models.
Hardware Acceleration of Monte-Carlo Sampling for Energy Efficient Robust Robot Manipulation
Jul 15, 2020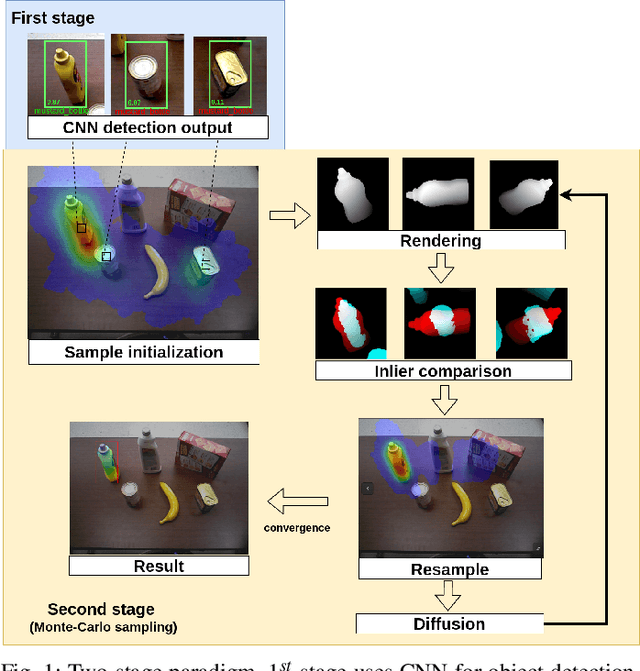
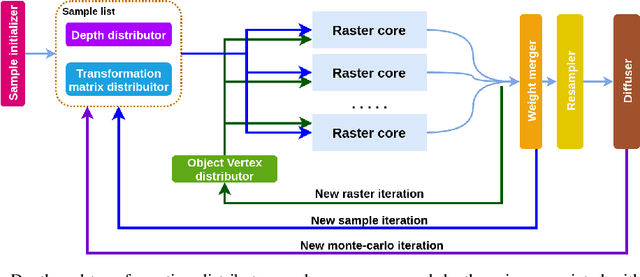
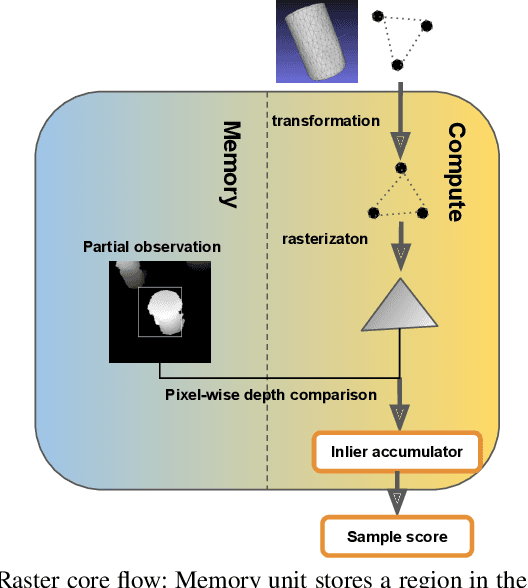

Algorithms based on Monte-Carlo sampling have been widely adapted in robotics and other areas of engineering due to their performance robustness. However, these sampling-based approaches have high computational requirements, making them unsuitable for real-time applications with tight energy constraints. In this paper, we investigate 6 degree-of-freedom (6DoF) pose estimation for robot manipulation using this method, which uses rendering combined with sequential Monte-Carlo sampling. While potentially very accurate, the significant computational complexity of the algorithm makes it less attractive for mobile robots, where runtime and energy consumption are tightly constrained. To address these challenges, we develop a novel hardware implementation of Monte-Carlo sampling on an FPGA with lower computational complexity and memory usage, while achieving high parallelism and modularization. Our results show 12X-21X improvements in energy efficiency over low-power and high-end GPU implementations, respectively. Moreover, we achieve real time performance without compromising accuracy.
GRIP: Generative Robust Inference and Perception for Semantic Robot Manipulation in Adversarial Environments
Mar 20, 2019
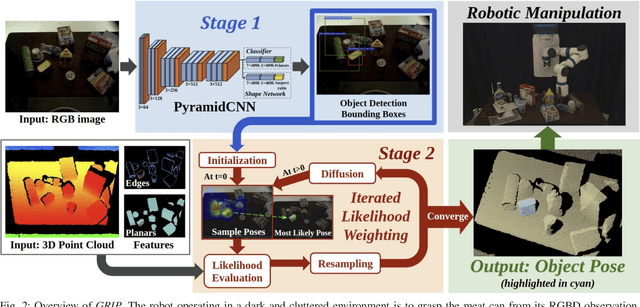
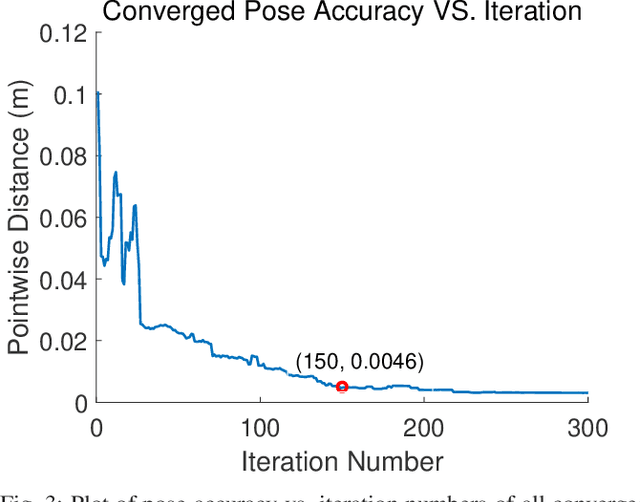

Recent advancements have led to a proliferation of machine learning systems used to assist humans in a wide range of tasks. However, we are still far from accurate, reliable, and resource-efficient operations of these systems. For robot perception, convolutional neural networks (CNNs) for object detection and pose estimation are recently coming into widespread use. However, neural networks are known to suffer overfitting during training process and are less robust within unseen conditions, which are especially vulnerable to {\em adversarial scenarios}. In this work, we propose {\em Generative Robust Inference and Perception (GRIP)} as a two-stage object detection and pose estimation system that aims to combine relative strengths of discriminative CNNs and generative inference methods to achieve robust estimation. Our results show that a second stage of sample-based generative inference is able to recover from false object detection by CNNs, and produce robust estimations in adversarial conditions. We demonstrate the efficacy of {\em GRIP} robustness through comparison with state-of-the-art learning-based pose estimators and pick-and-place manipulation in dark and cluttered environments.