 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRIP: Generative Robust Inference and Perception for Semantic Robot Manipulation in Adversarial Environments
Paper and Code

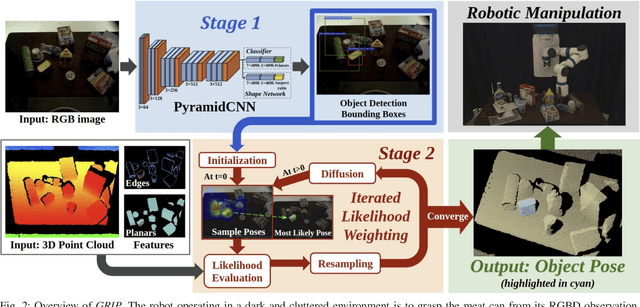
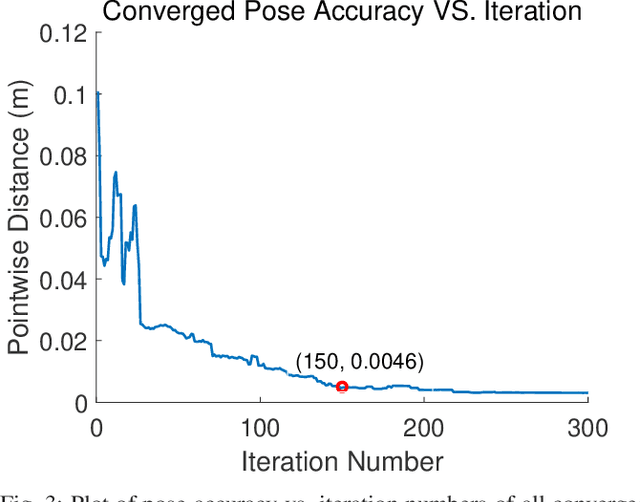

Recent advancements have led to a proliferation of machine learning systems used to assist humans in a wide range of tasks. However, we are still far from accurate, reliable, and resource-efficient operations of these systems. For robot perception, convolutional neural networks (CNNs) for object detection and pose estimation are recently coming into widespread use. However, neural networks are known to suffer overfitting during training process and are less robust within unseen conditions, which are especially vulnerable to {\em adversarial scenarios}. In this work, we propose {\em Generative Robust Inference and Perception (GRIP)} as a two-stage object detection and pose estimation system that aims to combine relative strengths of discriminative CNNs and generative inference methods to achieve robust estimation. Our results show that a second stage of sample-based generative inference is able to recover from false object detection by CNNs, and produce robust estimations in adversarial conditions. We demonstrate the efficacy of {\em GRIP} robustness through comparison with state-of-the-art learning-based pose estimators and pick-and-place manipulation in dark and cluttered environments.