 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Silence Is Golden: Can LLMs Learn to Abstain in Temporal QA and Beyond?
Feb 04, 2026Large language models (LLMs) rarely admit uncertainty, often producing fluent but misleading answers, rather than abstaining (i.e., refusing to answer). This weakness is even evident in temporal question answering, where models frequently ignore time-sensitive evidence and conflate facts across different time-periods. In this paper, we present the first empirical study of training LLMs with an abstention ability while reasoning about temporal QA. Existing approaches such as calibration might be unreliable in capturing uncertainty in complex reasoning. We instead frame abstention as a teachable skill and introduce a pipeline that couples Chain-of-Thought (CoT) supervision with Reinforcement Learning (RL) guided by abstention-aware rewards. Our goal is to systematically analyze how different information types and training techniques affect temporal reasoning with abstention behavior in LLMs. Through extensive experiments studying various methods, we find that RL yields strong empirical gains on reasoning: a model initialized by Qwen2.5-1.5B-Instruct surpasses GPT-4o by $3.46\%$ and $5.80\%$ in Exact Match on TimeQA-Easy and Hard, respectively. Moreover, it improves the True Positive rate on unanswerable questions by $20\%$ over a pure supervised fine-tuned (SFT) variant. Beyond performance, our analysis shows that SFT induces overconfidence and harms reliability, while RL improves prediction accuracy but exhibits similar risks. Finally, by comparing implicit reasoning cues (e.g., original context, temporal sub-context, knowledge graphs) with explicit CoT supervision, we find that implicit information provides limited benefit for reasoning with abstention. Our study provides new insights into how abstention and reasoning can be jointly optimized, providing a foundation for building more reliable LLMs.
Beyond Multiple Choice: Evaluating Steering Vectors for Adaptive Free-Form Summarization
May 30, 2025Steering vectors are a lightweight method for controlling text properties by adding a learned bias to language model activations at inference time. So far, steering vectors have predominantly been evaluated in multiple-choice settings, while their effectiveness in free-form generation tasks remains understudied. Moving "Beyond Multiple Choice," we thoroughly evaluate the effectiveness of steering vectors in adaptively controlling topical focus, sentiment, toxicity, and readability in abstractive summaries of the NEWTS dataset. We find that steering effectively controls the targeted summary properties, but high steering strengths consistently degrade both intrinsic and extrinsic text quality. Compared to steering, prompting offers weaker control, while preserving text quality. Combining steering and prompting yields the strongest control over text properties and offers the most favorable efficacy-quality trade-off at moderate steering strengths. Our results underscore the practical trade-off between control strength and text quality preservation when applying steering vectors to free-form generation tasks.
Understanding (Un)Reliability of Steering Vectors in Language Models
May 28, 2025



Steering vectors are a lightweight method to control language model behavior by adding a learned bias to the activations at inference time. Although steering demonstrates promising performance, recent work shows that it can be unreliable or even counterproductive in some cases. This paper studies the influence of prompt types and the geometry of activation differences on steering reliability. First, we find that all seven prompt types used in our experiments produce a net positive steering effect, but exhibit high variance across samples, and often give an effect opposite of the desired one. No prompt type clearly outperforms the others, and yet the steering vectors resulting from the different prompt types often differ directionally (as measured by cosine similarity). Second, we show that higher cosine similarity between training set activation differences predicts more effective steering. Finally, we observe that datasets where positive and negative activations are better separated are more steerable. Our results suggest that vector steering is unreliable when the target behavior is not represented by a coherent direction.
Enhancing Retrieval-Augmented Generation: A Study of Best Practices
Jan 13, 2025



Retrieval-Augmented Generation (RAG) systems have recently shown remarkable advancements by integrating retrieval mechanisms into language models, enhancing their ability to produce more accurate and contextually relevant responses. However, the influence of various components and configurations within RAG systems remains underexplored. A comprehensive understanding of these elements is essential for tailoring RAG systems to complex retrieval tasks and ensuring optimal performance across diverse applications. In this paper, we develop several advanced RAG system designs that incorporate query expansion, various novel retrieval strategies, and a novel Contrastive In-Context Learning RAG. Our study systematically investigates key factors, including language model size, prompt design, document chunk size, knowledge base size, retrieval stride, query expansion techniques, Contrastive In-Context Learning knowledge bases, multilingual knowledge bases, and Focus Mode retrieving relevant context at sentence-level. Through extensive experimentation, we provide a detailed analysis of how these factors influence response quality. Our findings offer actionable insights for developing RAG systems, striking a balance between contextual richness and retrieval-generation efficiency, thereby paving the way for more adaptable and high-performing RAG frameworks in diverse real-world scenarios. Our code and implementation details are publicly available.
Are LLMs effective psychological assessors? Leveraging adaptive RAG for interpretable mental health screening through psychometric practice
Jan 02, 2025

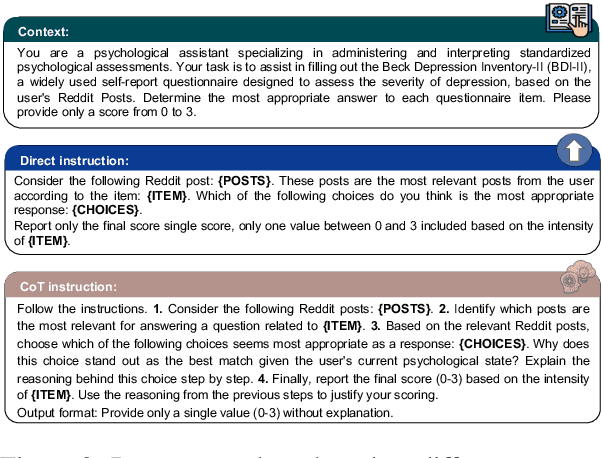
In psychological practice, standardized questionnaires serve as essential tools for assessing mental constructs (e.g., attitudes, traits, and emotions) through structured questions (aka items). With the increasing prevalence of social media platforms where users share personal experiences and emotions, researchers are exploring computational methods to leverage this data for rapid mental health screening. In this study, we propose a novel adaptive Retrieval-Augmented Generation (RAG) approach that completes psychological questionnaires by analyzing social media posts. Our method retrieves the most relevant user posts for each question in a psychological survey and uses Large Language Models (LLMs) to predict questionnaire scores in a zero-shot setting. Our findings are twofold. First we demonstrate that this approach can effectively predict users' responses to psychological questionnaires, such as the Beck Depression Inventory II (BDI-II), achieving performance comparable to or surpassing state-of-the-art models on Reddit-based benchmark datasets without relying on training data. Second, we show how this methodology can be generalized as a scalable screening tool, as the final assessment is systematically derived by completing standardized questionnaires and tracking how individual item responses contribute to the diagnosis, aligning with established psychometric practices.
Controllable Topic-Focused Abstractive Summarization
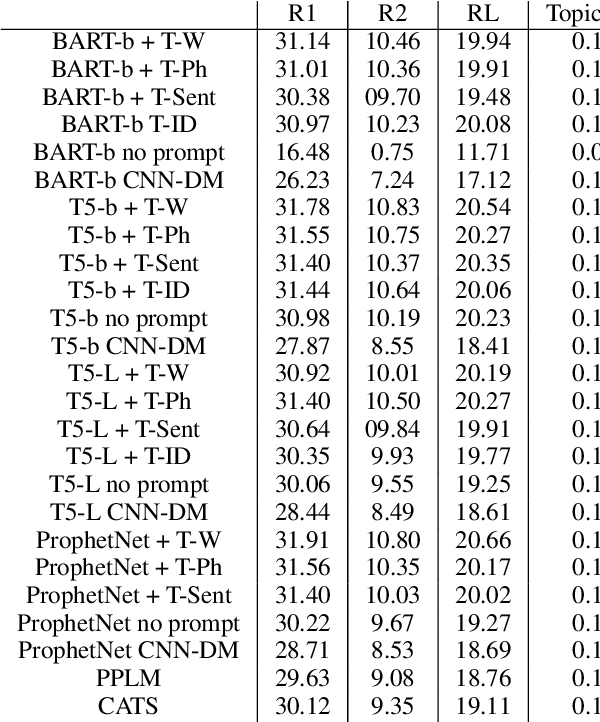
Nov 12, 2023Controlled abstractive summarization focuses on producing condensed versions of a source article to cover specific aspects by shifting the distribution of generated text towards a desired style, e.g., a set of topics. Subsequently, the resulting summaries may be tailored to user-defined requirements. This paper presents a new Transformer-based architecture capable of producing topic-focused summaries. The architecture modifies the cross-attention mechanism of the Transformer to bring topic-focus control to the generation process while not adding any further parameters to the model. We show that our model sets a new state of the art on the NEWTS dataset in terms of topic-focused abstractive summarization as well as a topic-prevalence score. Moreover, we show via extensive experiments that our proposed topical cross-attention mechanism can be plugged into various Transformer models, such as BART and T5, improving their performance on the CNN/Dailymail and XSum benchmark datasets for abstractive summarization. This is achieved via fine-tuning, without requiring training from scratch. Finally, we show through human evaluation that our model generates more faithful summaries outperforming the state-of-the-art Frost model.
Neural Summarization of Electronic Health Records
May 24, 2023



Hospital discharge documentation is among the most essential, yet time-consuming documents written by medical practitioners. The objective of this study was to automatically generate hospital discharge summaries using neural network summarization models. We studied various data preparation and neural network training techniques that generate discharge summaries. Using nursing notes and discharge summaries from the MIMIC-III dataset, we studied the viability of the automatic generation of various sections of a discharge summary using four state-of-the-art neural network summarization models (BART, T5, Longformer and FLAN-T5). Our experiments indicated that training environments including nursing notes as the source, and discrete sections of the discharge summary as the target output (e.g. "History of Present Illness") improve language model efficiency and text quality. According to our findings, the fine-tuned BART model improved its ROUGE F1 score by 43.6% against its standard off-the-shelf version. We also found that fine-tuning the baseline BART model with other setups caused different degrees of improvement (up to 80% relative improvement). We also observed that a fine-tuned T5 generally achieves higher ROUGE F1 scores than other fine-tuned models and a fine-tuned FLAN-T5 achieves the highest ROUGE score overall, i.e., 45.6. For majority of the fine-tuned language models, summarizing discharge summary report sections separately outperformed the summarization the entire report quantitatively. On the other hand, fine-tuning language models that were previously instruction fine-tuned showed better performance in summarizing entire reports. This study concludes that a focused dataset designed for the automatic generation of discharge summaries by a language model can produce coherent Discharge Summary sections.
NEWTS: A Corpus for News Topic-Focused Summarization
May 31, 2022

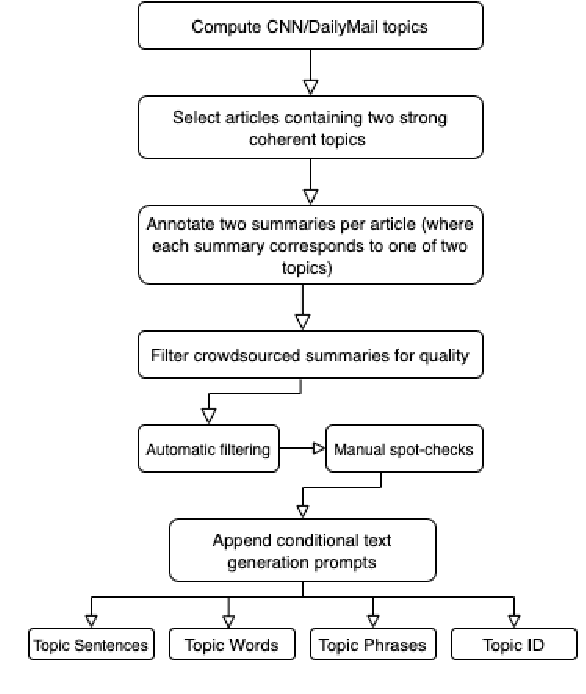
Text summarization models are approaching human levels of fidelity. Existing benchmarking corpora provide concordant pairs of full and abridged versions of Web, news or, professional content. To date, all summarization datasets operate under a one-size-fits-all paradigm that may not reflect the full range of organic summarization needs. Several recently proposed models (e.g., plug and play language models) have the capacity to condition the generated summaries on a desired range of themes. These capacities remain largely unused and unevaluated as there is no dedicated dataset that would support the task of topic-focused summarization. This paper introduces the first topical summarization corpus NEWTS, based on the well-known CNN/Dailymail dataset, and annotated via online crowd-sourcing. Each source article is paired with two reference summaries, each focusing on a different theme of the source document. We evaluate a representative range of existing techniques and analyze the effectiveness of different prompting methods.