 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Causal Tree for Uplift Modeling
Feb 04, 2022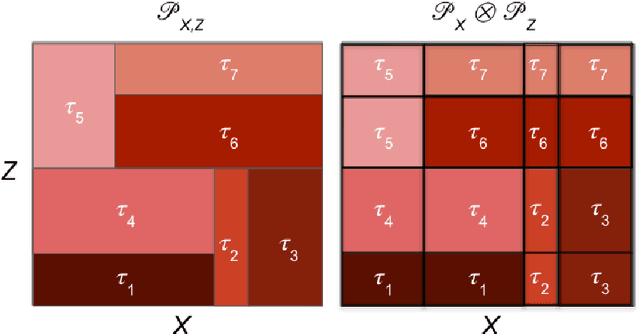
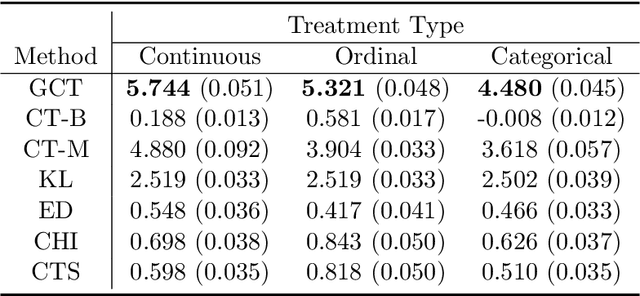
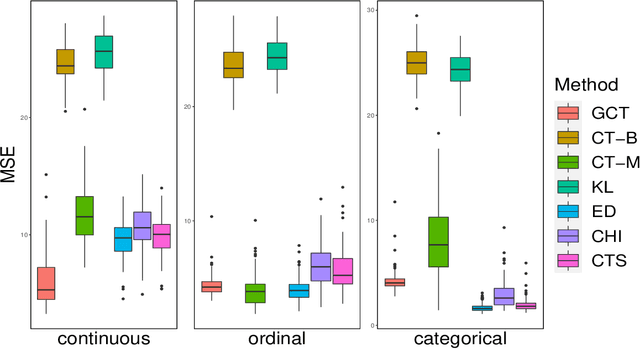

Uplift modeling is crucial in various applications ranging from marketing and policy-making to personalized recommendations. The main objective is to learn optimal treatment allocations for a heterogeneous population. A primary line of existing work modifies the loss function of the decision tree algorithm to identify cohorts with heterogeneous treatment effects. Another line of work estimates the individual treatment effects separately for the treatment group and the control group using off-the-shelf supervised learning algorithms. The former approach that directly models the heterogeneous treatment effect is known to outperform the latter in practice. However, the existing tree-based methods are mostly limited to a single treatment and a single control use case, except for a handful of extensions to multiple discrete treatments. In this paper, we fill this gap in the literature by proposing a generalization to the tree-based approaches to tackle multiple discrete and continuous-valued treatments. We focus on a generalization of the well-known causal tree algorithm due to its desirable statistical properties, but our generalization technique can be applied to other tree-based approaches as well. We perform extensive experiments to showcase the efficacy of our method when compared to other methods.
Feedback Shaping: A Modeling Approach to Nurture Content Creation
Jun 21, 2021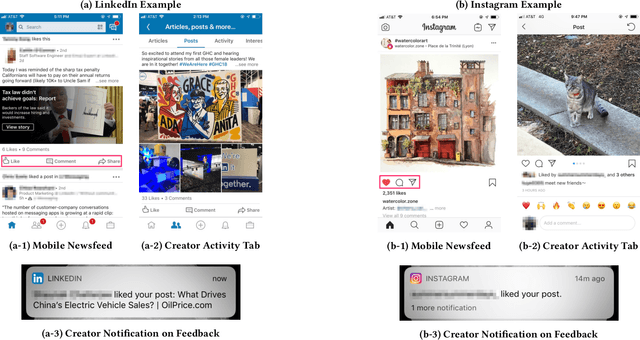
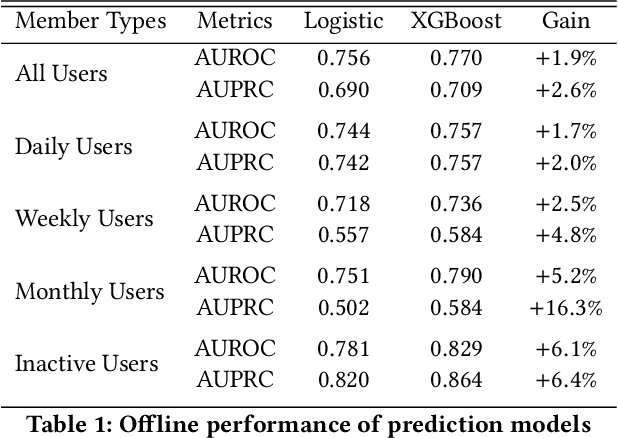

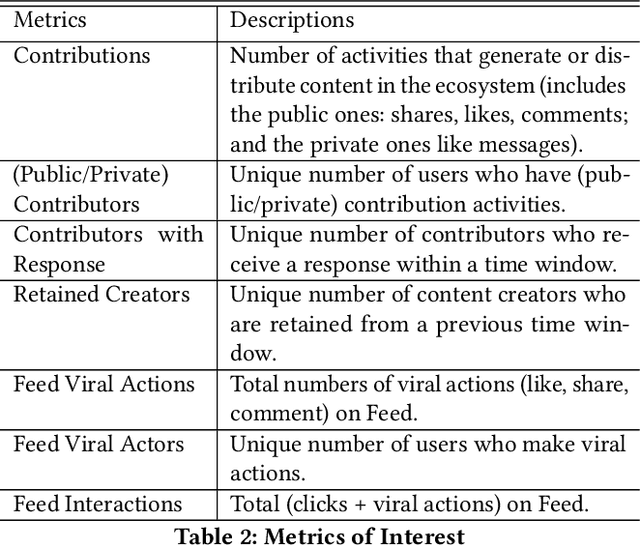
Social media platforms bring together content creators and content consumers through recommender systems like newsfeed. The focus of such recommender systems has thus far been primarily on modeling the content consumer preferences and optimizing for their experience. However, it is equally critical to nurture content creation by prioritizing the creators' interests, as quality content forms the seed for sustainable engagement and conversations, bringing in new consumers while retaining existing ones. In this work, we propose a modeling approach to predict how feedback from content consumers incentivizes creators. We then leverage this model to optimize the newsfeed experience for content creators by reshaping the feedback distribution, leading to a more active content ecosystem. Practically, we discuss how we balance the user experience for both consumers and creators, and how we carry out online A/B tests with strong network effects. We present a deployed use case on the LinkedIn newsfeed, where we used this approach to improve content creation significantly without compromising the consumers' experience.
Personalization and Optimization of Decision Parameters via Heterogenous Causal Effects
Feb 04, 2019


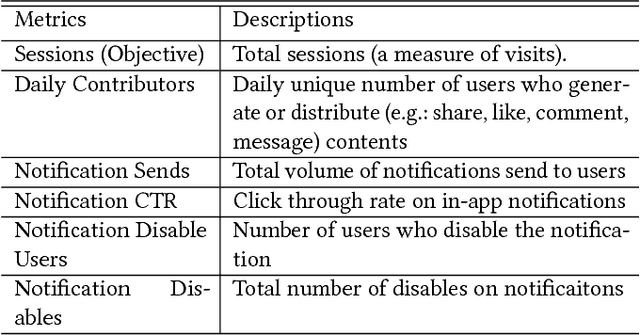
Randomized experimentation (also known as A/B testing or bucket testing) is very commonly used in the internet industry to measure the effect of a new treatment. Often, the decision on the basis of such A/B testing is to ramp the treatment variant that did best for the entire population. However, the effect of any given treatment varies across experimental units, and choosing a single variant to ramp to the whole population can be quite suboptimal. In this work, we propose a method which automatically identifies the collection of cohorts exhibiting heterogeneous treatment effect (using causal trees). We then use stochastic optimization to identify the optimal treatment variant in each cohort. We use two real-life examples - one related to serving notifications and the other related to modulating ads density on feed. In both examples, using offline simulation and online experimentation, we demonstrate the benefits of our approach. At the time of writing this paper, the method described has been deployed on the LinkedIn Ads and Notifications system.