 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA State Transition Model for Mobile Notifications via Survival Analysis
Jul 07, 2022


Mobile notifications have become a major communication channel for social networking services to keep users informed and engaged. As more mobile applications push notifications to users, they constantly face decisions on what to send, when and how. A lack of research and methodology commonly leads to heuristic decision making. Many notifications arrive at an inappropriate moment or introduce too many interruptions, failing to provide value to users and spurring users' complaints. In this paper we explore unique features of interactions between mobile notifications and user engagement. We propose a state transition framework to quantitatively evaluate the effectiveness of notifications. Within this framework, we develop a survival model for badging notifications assuming a log-linear structure and a Weibull distribution. Our results show that this model achieves more flexibility for applications and superior prediction accuracy than a logistic regression model. In particular, we provide an online use case on notification delivery time optimization to show how we make better decisions, drive more user engagement, and provide more value to users.
* 9 pages, 7 figures. Published in WSDM 19'
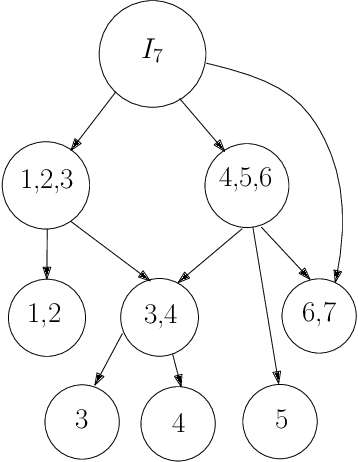
Generalized Causal Tree for Uplift Modeling
Feb 04, 2022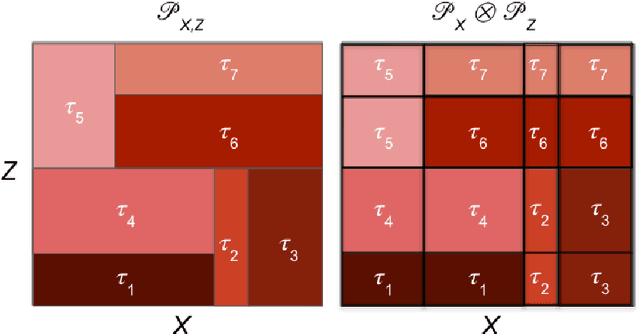
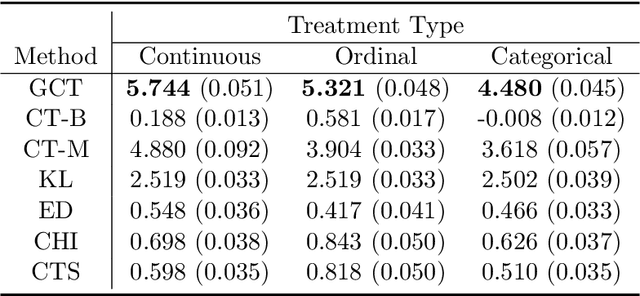
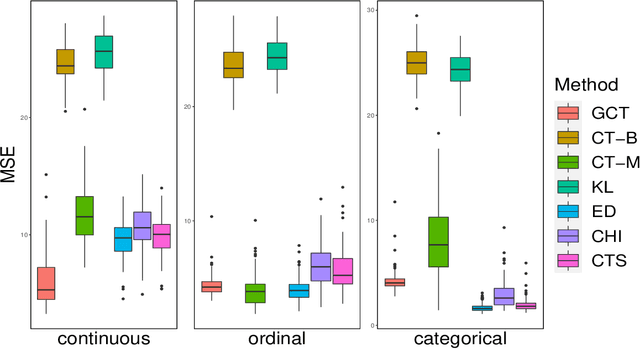

Uplift modeling is crucial in various applications ranging from marketing and policy-making to personalized recommendations. The main objective is to learn optimal treatment allocations for a heterogeneous population. A primary line of existing work modifies the loss function of the decision tree algorithm to identify cohorts with heterogeneous treatment effects. Another line of work estimates the individual treatment effects separately for the treatment group and the control group using off-the-shelf supervised learning algorithms. The former approach that directly models the heterogeneous treatment effect is known to outperform the latter in practice. However, the existing tree-based methods are mostly limited to a single treatment and a single control use case, except for a handful of extensions to multiple discrete treatments. In this paper, we fill this gap in the literature by proposing a generalization to the tree-based approaches to tackle multiple discrete and continuous-valued treatments. We focus on a generalization of the well-known causal tree algorithm due to its desirable statistical properties, but our generalization technique can be applied to other tree-based approaches as well. We perform extensive experiments to showcase the efficacy of our method when compared to other methods.
Feedback Shaping: A Modeling Approach to Nurture Content Creation
Jun 21, 2021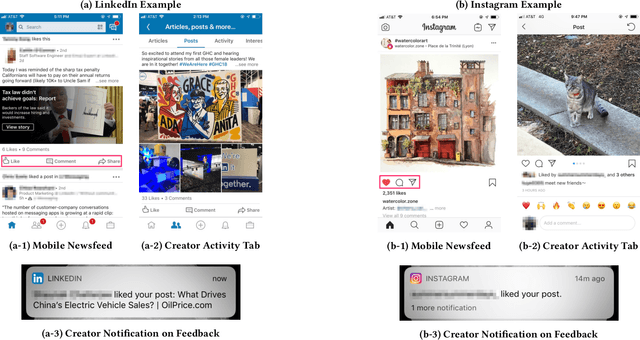
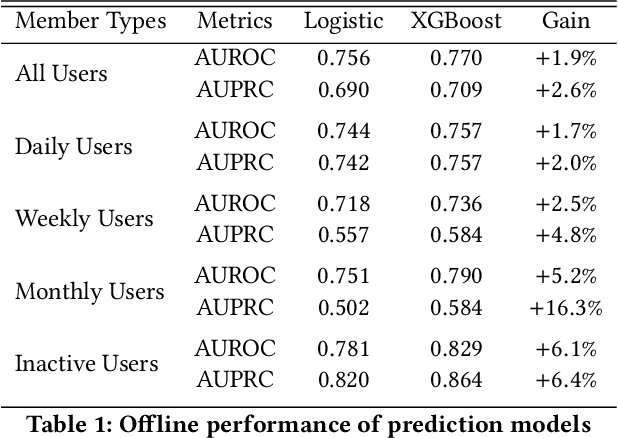

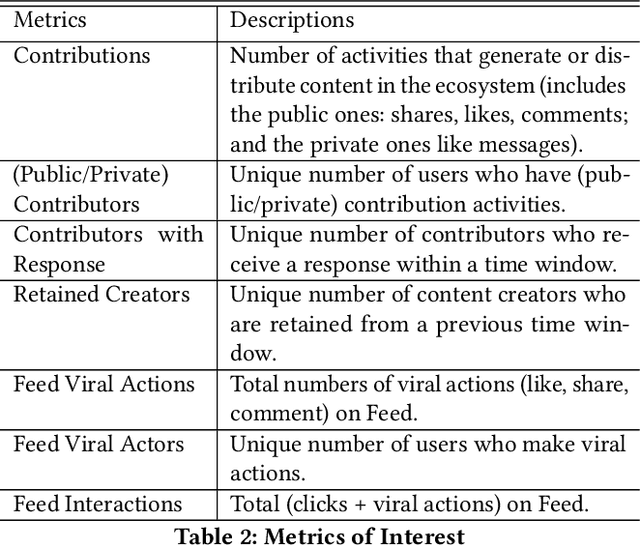
Social media platforms bring together content creators and content consumers through recommender systems like newsfeed. The focus of such recommender systems has thus far been primarily on modeling the content consumer preferences and optimizing for their experience. However, it is equally critical to nurture content creation by prioritizing the creators' interests, as quality content forms the seed for sustainable engagement and conversations, bringing in new consumers while retaining existing ones. In this work, we propose a modeling approach to predict how feedback from content consumers incentivizes creators. We then leverage this model to optimize the newsfeed experience for content creators by reshaping the feedback distribution, leading to a more active content ecosystem. Practically, we discuss how we balance the user experience for both consumers and creators, and how we carry out online A/B tests with strong network effects. We present a deployed use case on the LinkedIn newsfeed, where we used this approach to improve content creation significantly without compromising the consumers' experience.
Personalization and Optimization of Decision Parameters via Heterogenous Causal Effects
Feb 04, 2019


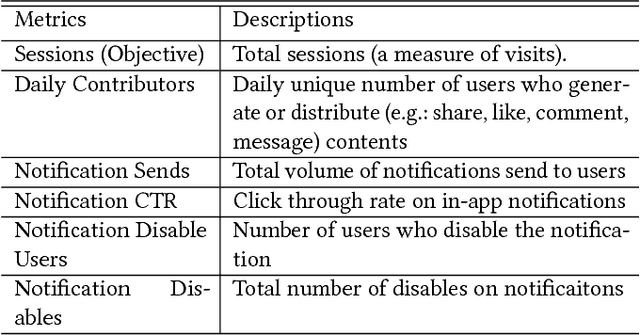
Randomized experimentation (also known as A/B testing or bucket testing) is very commonly used in the internet industry to measure the effect of a new treatment. Often, the decision on the basis of such A/B testing is to ramp the treatment variant that did best for the entire population. However, the effect of any given treatment varies across experimental units, and choosing a single variant to ramp to the whole population can be quite suboptimal. In this work, we propose a method which automatically identifies the collection of cohorts exhibiting heterogeneous treatment effect (using causal trees). We then use stochastic optimization to identify the optimal treatment variant in each cohort. We use two real-life examples - one related to serving notifications and the other related to modulating ads density on feed. In both examples, using offline simulation and online experimentation, we demonstrate the benefits of our approach. At the time of writing this paper, the method described has been deployed on the LinkedIn Ads and Notifications system.
Measuring Long-term Impact of Ads on LinkedIn Feed
Jan 29, 2019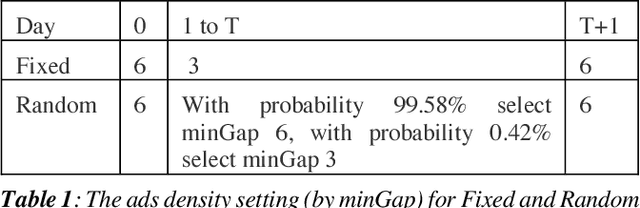
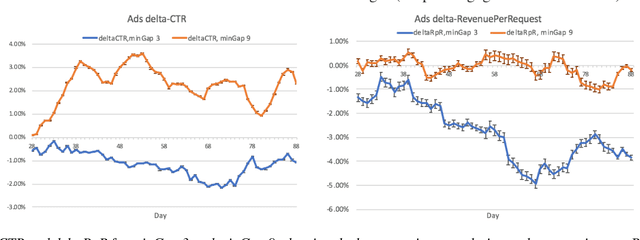
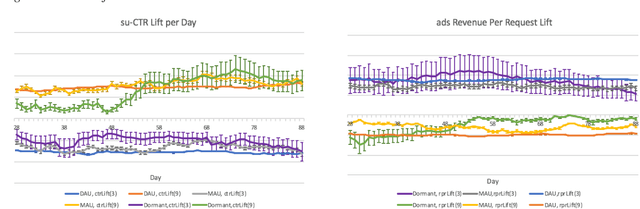
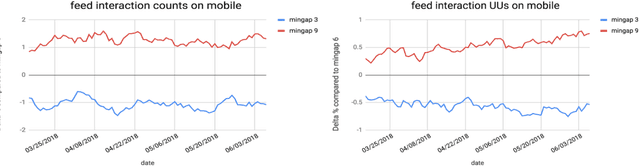
Organic updates (from a member's network) and sponsored updates (or ads, from advertisers) together form the newsfeed on LinkedIn. The newsfeed, the default homepage for members, attracts them to engage, brings them value and helps LinkedIn grow. Engagement and Revenue on feed are two critical, yet often conflicting objectives. Hence, it is important to design a good Revenue-Engagement Tradeoff (RENT) mechanism to blend ads in the feed. In this paper, we design experiments to understand how members' behavior evolve over time given different ads experiences. These experiences vary on ads density, while the quality of ads (ensured by relevance models) is held constant. Our experiments have been conducted on randomized member buckets and we use two experimental designs to measure the short term and long term effects of the various treatments. Based on the first three months' data, we observe that the long term impact is at a much smaller scale than the short term impact in our application. Furthermore, we observe different member cohorts (based on user activity level) adapt and react differently over time.
Large-Scale Quadratically Constrained Quadratic Program via Low-Discrepancy Sequences
Oct 02, 2017
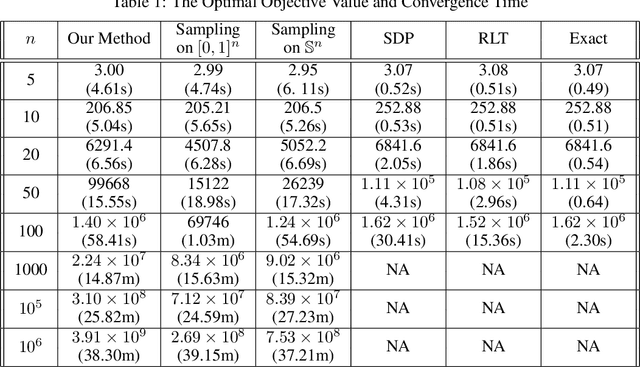
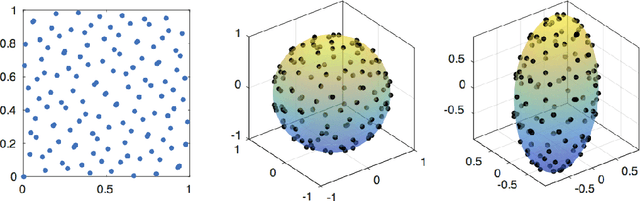
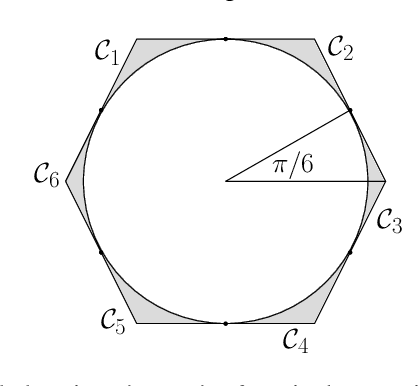
We consider the problem of solving a large-scale Quadratically Constrained Quadratic Program. Such problems occur naturally in many scientific and web applications. Although there are efficient methods which tackle this problem, they are mostly not scalable. In this paper, we develop a method that transforms the quadratic constraint into a linear form by sampling a set of low-discrepancy points. The transformed problem can then be solved by applying any state-of-the-art large-scale quadratic programming solvers. We show the convergence of our approximate solution to the true solution as well as some finite sample error bounds. Experimental results are also shown to prove scalability as well as improved quality of approximation in practice.
Constrained Multi-Slot Optimization for Ranking Recommendations
May 16, 2017
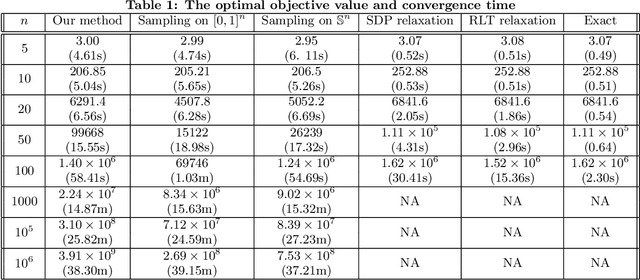
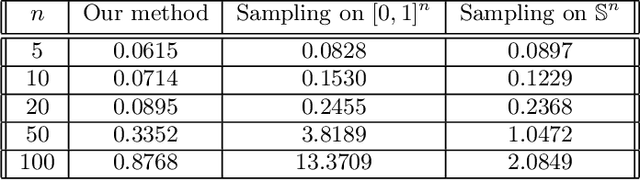
Ranking items to be recommended to users is one of the main problems in large scale social media applications. This problem can be set up as a multi-objective optimization problem to allow for trading off multiple, potentially conflicting objectives (that are driven by those items) against each other. Most previous approaches to this problem optimize for a single slot without considering the interaction effect of these items on one another. In this paper, we develop a constrained multi-slot optimization formulation, which allows for modeling interactions among the items on the different slots. We characterize the solution in terms of problem parameters and identify conditions under which an efficient solution is possible. The problem formulation results in a quadratically constrained quadratic program (QCQP). We provide an algorithm that gives us an efficient solution by relaxing the constraints of the QCQP minimally. Through simulated experiments, we show the benefits of modeling interactions in a multi-slot ranking context, and the speed and accuracy of our QCQP approximate solver against other state of the art methods.
Large scale multi-objective optimization: Theoretical and practical challenges
Feb 13, 2016

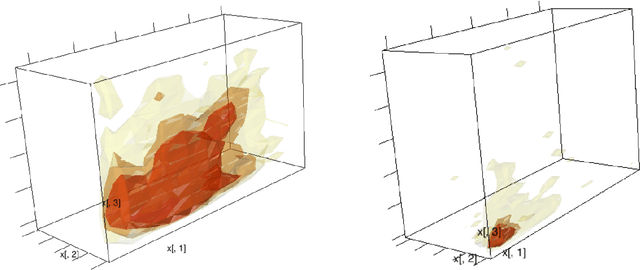
Multi-objective optimization (MOO) is a well-studied problem for several important recommendation problems. While multiple approaches have been proposed, in this work, we focus on using constrained optimization formulations (e.g., quadratic and linear programs) to formulate and solve MOO problems. This approach can be used to pick desired operating points on the trade-off curve between multiple objectives. It also works well for internet applications which serve large volumes of online traffic, by working with Lagrangian duality formulation to connect dual solutions (computed offline) with the primal solutions (computed online). We identify some key limitations of this approach -- namely the inability to handle user and item level constraints, scalability considerations and variance of dual estimates introduced by sampling processes. We propose solutions for each of the problems and demonstrate how through these solutions we significantly advance the state-of-the-art in this realm. Our proposed methods can exactly handle user and item (and other such local) constraints, achieve a $100\times$ scalability boost over existing packages in R and reduce variance of dual estimates by two orders of magnitude.
A temporally abstracted Viterbi algorithm
Feb 14, 2012



Hierarchical problem abstraction, when applicable, may offer exponential reductions in computational complexity. Previous work on coarse-to-fine dynamic programming (CFDP) has demonstrated this possibility using state abstraction to speed up the Viterbi algorithm. In this paper, we show how to apply temporal abstraction to the Viterbi problem. Our algorithm uses bounds derived from analysis of coarse timescales to prune large parts of the state trellis at finer timescales. We demonstrate improvements of several orders of magnitude over the standard Viterbi algorithm, as well as significant speedups over CFDP, for problems whose state variables evolve at widely differing rates.