 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Personalized Page Content Ranking Using Customer Representation
May 09, 2023On E-commerce stores (Amazon, eBay etc.) there are rich recommendation content to help shoppers shopping more efficiently. However given numerous products, it's crucial to select most relevant content to reduce the burden of information overload. We introduced a content ranking service powered by a linear causal bandit algorithm to rank and select content for each shopper under each context. The algorithm mainly leverages aggregated customer behavior features, and ignores single shopper level past activities. We study the problem of inferring shoppers interest from historical activities. We propose a deep learning based bandit algorithm that incorporates historical shopping behavior, customer latent shopping goals, and the correlation between customers and content categories. This model produces more personalized content ranking measured by 12.08% nDCG lift. In the online A/B test setting, the model improved 0.02% annualized commercial impact measured by our business metric, validating its effectiveness.
Personalization and Optimization of Decision Parameters via Heterogenous Causal Effects
Feb 04, 2019


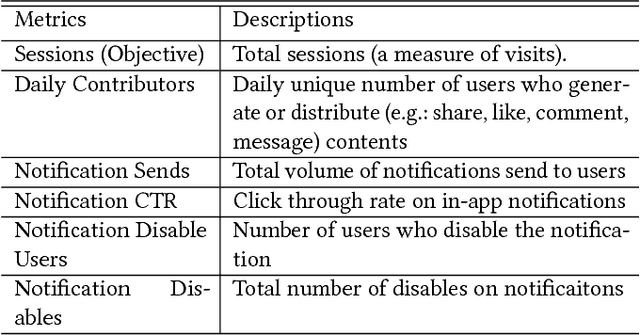
Randomized experimentation (also known as A/B testing or bucket testing) is very commonly used in the internet industry to measure the effect of a new treatment. Often, the decision on the basis of such A/B testing is to ramp the treatment variant that did best for the entire population. However, the effect of any given treatment varies across experimental units, and choosing a single variant to ramp to the whole population can be quite suboptimal. In this work, we propose a method which automatically identifies the collection of cohorts exhibiting heterogeneous treatment effect (using causal trees). We then use stochastic optimization to identify the optimal treatment variant in each cohort. We use two real-life examples - one related to serving notifications and the other related to modulating ads density on feed. In both examples, using offline simulation and online experimentation, we demonstrate the benefits of our approach. At the time of writing this paper, the method described has been deployed on the LinkedIn Ads and Notifications system.
Measuring Long-term Impact of Ads on LinkedIn Feed
Jan 29, 2019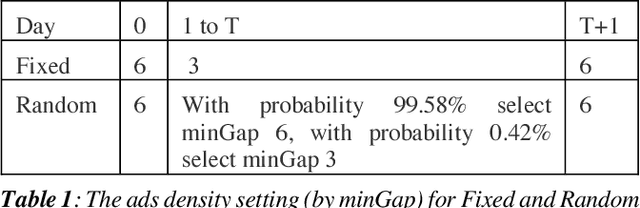
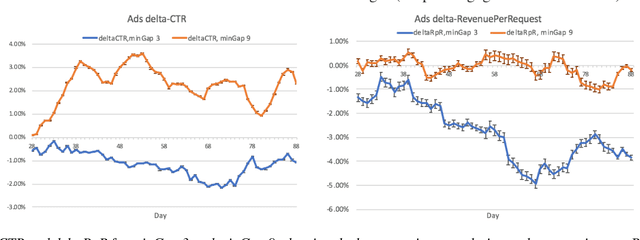
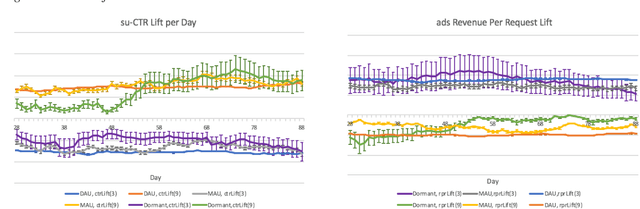
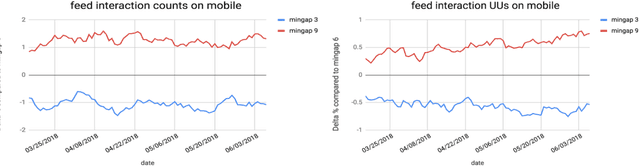
Organic updates (from a member's network) and sponsored updates (or ads, from advertisers) together form the newsfeed on LinkedIn. The newsfeed, the default homepage for members, attracts them to engage, brings them value and helps LinkedIn grow. Engagement and Revenue on feed are two critical, yet often conflicting objectives. Hence, it is important to design a good Revenue-Engagement Tradeoff (RENT) mechanism to blend ads in the feed. In this paper, we design experiments to understand how members' behavior evolve over time given different ads experiences. These experiences vary on ads density, while the quality of ads (ensured by relevance models) is held constant. Our experiments have been conducted on randomized member buckets and we use two experimental designs to measure the short term and long term effects of the various treatments. Based on the first three months' data, we observe that the long term impact is at a much smaller scale than the short term impact in our application. Furthermore, we observe different member cohorts (based on user activity level) adapt and react differently over time.
Who and Where: People and Location Co-Clustering
Jul 31, 2013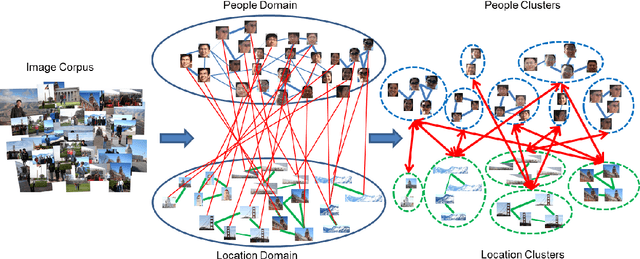
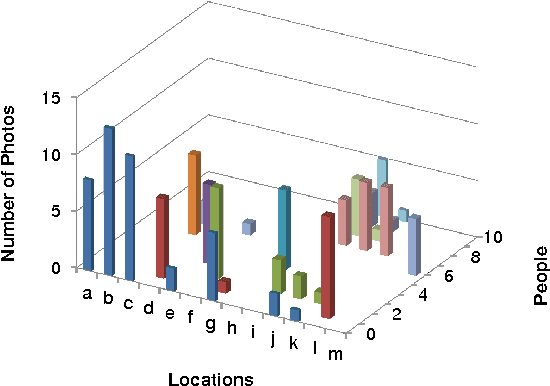


In this paper, we consider the clustering problem on images where each image contains patches in people and location domains. We exploit the correlation between people and location domains, and proposed a semi-supervised co-clustering algorithm to cluster images. Our algorithm updates the correlation links at the runtime, and produces clustering in both domains simultaneously. We conduct experiments in a manually collected dataset and a Flickr dataset. The result shows that the such correlation improves the clustering performance.