 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
Oct 09, 2025Large Language Models (LLMs) pose a new paradigm of modeling and computation for information tasks. Recommendation systems are a critical application domain poised to benefit significantly from the sequence modeling capabilities and world knowledge inherent in these large models. In this paper, we introduce PLUM, a framework designed to adapt pre-trained LLMs for industry-scale recommendation tasks. PLUM consists of item tokenization using Semantic IDs, continued pre-training (CPT) on domain-specific data, and task-specific fine-tuning for recommendation objectives. For fine-tuning, we focus particularly on generative retrieval, where the model is directly trained to generate Semantic IDs of recommended items based on user context. We conduct comprehensive experiments on large-scale internal video recommendation datasets. Our results demonstrate that PLUM achieves substantial improvements for retrieval compared to a heavily-optimized production model built with large embedding tables. We also present a scaling study for the model's retrieval performance, our learnings about CPT, a few enhancements to Semantic IDs, along with an overview of the training and inference methods that enable launching this framework to billions of users in YouTube.
A State Transition Model for Mobile Notifications via Survival Analysis
Jul 07, 2022


Mobile notifications have become a major communication channel for social networking services to keep users informed and engaged. As more mobile applications push notifications to users, they constantly face decisions on what to send, when and how. A lack of research and methodology commonly leads to heuristic decision making. Many notifications arrive at an inappropriate moment or introduce too many interruptions, failing to provide value to users and spurring users' complaints. In this paper we explore unique features of interactions between mobile notifications and user engagement. We propose a state transition framework to quantitatively evaluate the effectiveness of notifications. Within this framework, we develop a survival model for badging notifications assuming a log-linear structure and a Weibull distribution. Our results show that this model achieves more flexibility for applications and superior prediction accuracy than a logistic regression model. In particular, we provide an online use case on notification delivery time optimization to show how we make better decisions, drive more user engagement, and provide more value to users.
* 9 pages, 7 figures. Published in WSDM 19'
Evaluating Crowdsourcing Participants in the Absence of Ground-Truth
May 30, 2016
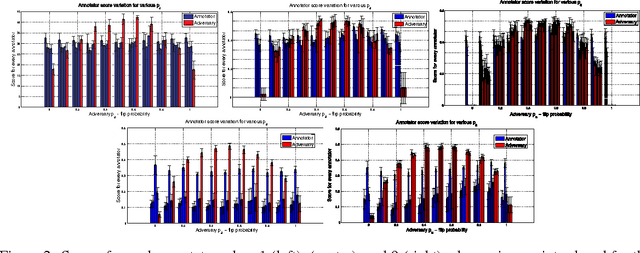
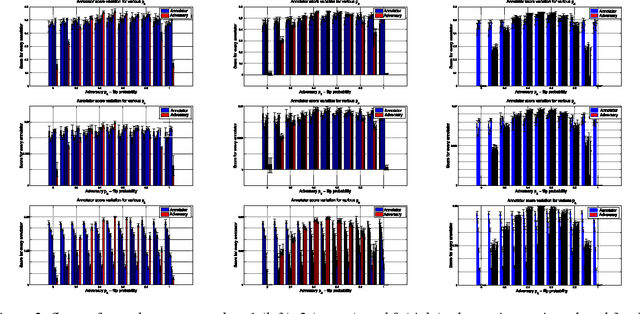
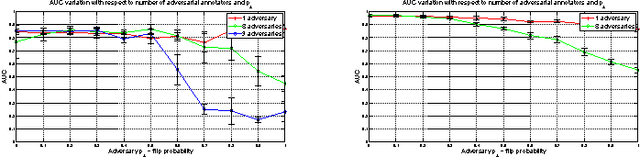
Given a supervised/semi-supervised learning scenario where multiple annotators are available, we consider the problem of identification of adversarial or unreliable annotators.
Learning Generative Models of Similarity Matrices
Oct 19, 2012
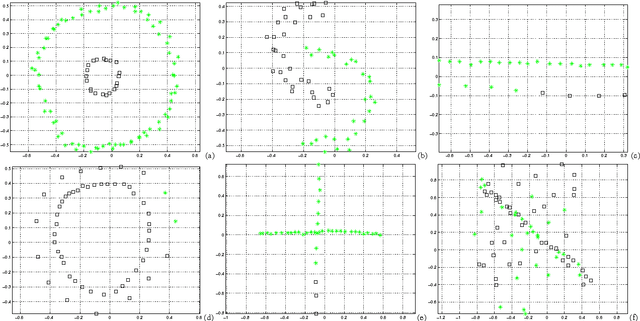


We describe a probabilistic (generative) view of affinity matrices along with inference algorithms for a subclass of problems associated with data clustering. This probabilistic view is helpful in understanding different models and algorithms that are based on affinity functions OF the data. IN particular, we show how(greedy) inference FOR a specific probabilistic model IS equivalent TO the spectral clustering algorithm.It also provides a framework FOR developing new algorithms AND extended models. AS one CASE, we present new generative data clustering models that allow us TO infer the underlying distance measure suitable for the clustering problem at hand. These models seem to perform well in a larger class of problems for which other clustering algorithms (including spectral clustering) usually fail. Experimental evaluation was performed in a variety point data sets, showing excellent performance.
Modeling Multiple Annotator Expertise in the Semi-Supervised Learning Scenario
Mar 15, 2012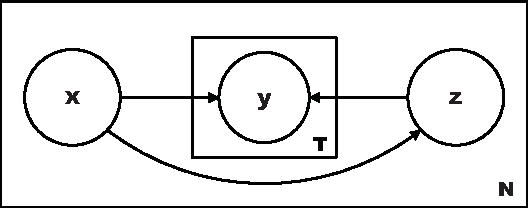



Learning algorithms normally assume that there is at most one annotation or label per data point. However, in some scenarios, such as medical diagnosis and on-line collaboration,multiple annotations may be available. In either case, obtaining labels for data points can be expensive and time-consuming (in some circumstances ground-truth may not exist). Semi-supervised learning approaches have shown that utilizing the unlabeled data is often beneficial in these cases. This paper presents a probabilistic semi-supervised model and algorithm that allows for learning from both unlabeled and labeled data in the presence of multiple annotators. We assume that it is known what annotator labeled which data points. The proposed approach produces annotator models that allow us to provide (1) estimates of the true label and (2) annotator variable expertise for both labeled and unlabeled data. We provide numerical comparisons under various scenarios and with respect to standard semi-supervised learning. Experiments showed that the presented approach provides clear advantages over multi-annotator methods that do not use the unlabeled data and over methods that do not use multi-labeler information.