 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Retrieve for Job Matching
Feb 21, 2024



Web-scale search systems typically tackle the scalability challenge with a two-step paradigm: retrieval and ranking. The retrieval step, also known as candidate selection, often involves extracting standardized entities, creating an inverted index, and performing term matching for retrieval. Such traditional methods require manual and time-consuming development of query models. In this paper, we discuss applying learning-to-retrieve technology to enhance LinkedIns job search and recommendation systems. In the realm of promoted jobs, the key objective is to improve the quality of applicants, thereby delivering value to recruiter customers. To achieve this, we leverage confirmed hire data to construct a graph that evaluates a seeker's qualification for a job, and utilize learned links for retrieval. Our learned model is easy to explain, debug, and adjust. On the other hand, the focus for organic jobs is to optimize seeker engagement. We accomplished this by training embeddings for personalized retrieval, fortified by a set of rules derived from the categorization of member feedback. In addition to a solution based on a conventional inverted index, we developed an on-GPU solution capable of supporting both KNN and term matching efficiently.
LinkSAGE: Optimizing Job Matching Using Graph Neural Networks
Feb 20, 2024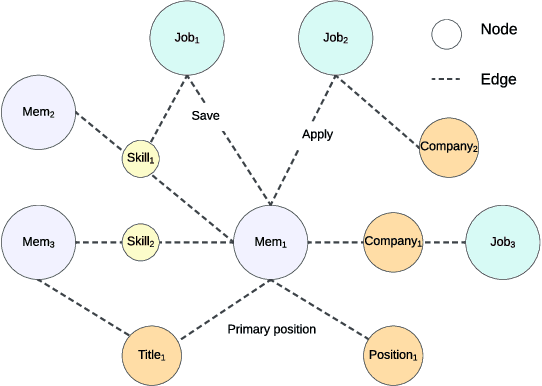

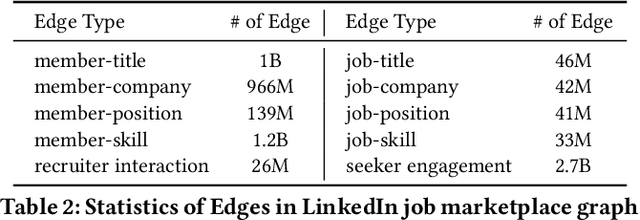

We present LinkSAGE, an innovative framework that integrates Graph Neural Networks (GNNs) into large-scale personalized job matching systems, designed to address the complex dynamics of LinkedIns extensive professional network. Our approach capitalizes on a novel job marketplace graph, the largest and most intricate of its kind in industry, with billions of nodes and edges. This graph is not merely extensive but also richly detailed, encompassing member and job nodes along with key attributes, thus creating an expansive and interwoven network. A key innovation in LinkSAGE is its training and serving methodology, which effectively combines inductive graph learning on a heterogeneous, evolving graph with an encoder-decoder GNN model. This methodology decouples the training of the GNN model from that of existing Deep Neural Nets (DNN) models, eliminating the need for frequent GNN retraining while maintaining up-to-date graph signals in near realtime, allowing for the effective integration of GNN insights through transfer learning. The subsequent nearline inference system serves the GNN encoder within a real-world setting, significantly reducing online latency and obviating the need for costly real-time GNN infrastructure. Validated across multiple online A/B tests in diverse product scenarios, LinkSAGE demonstrates marked improvements in member engagement, relevance matching, and member retention, confirming its generalizability and practical impact.
WikiReading: A Novel Large-scale Language Understanding Task over Wikipedia
Mar 15, 2017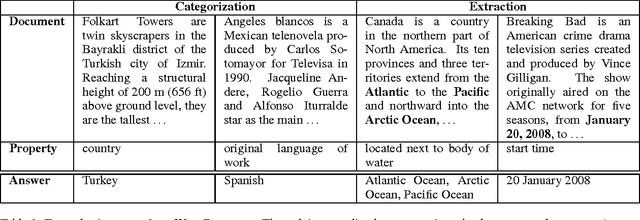
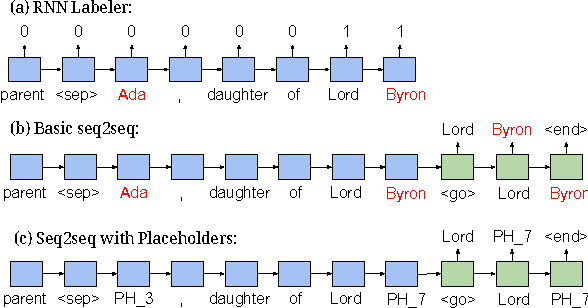
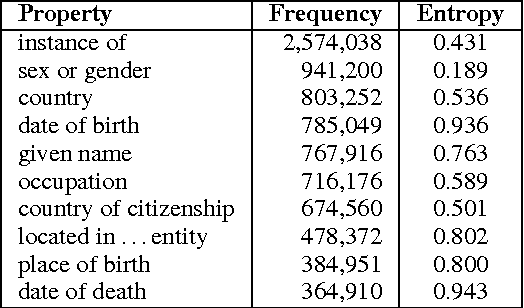
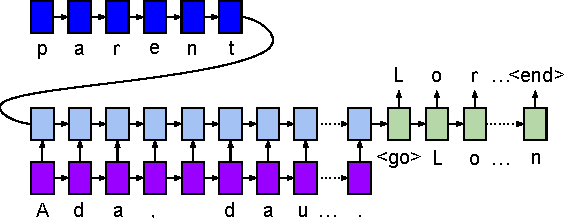
We present WikiReading, a large-scale natural language understanding task and publicly-available dataset with 18 million instances. The task is to predict textual values from the structured knowledge base Wikidata by reading the text of the corresponding Wikipedia articles. The task contains a rich variety of challenging classification and extraction sub-tasks, making it well-suited for end-to-end models such as deep neural networks (DNNs). We compare various state-of-the-art DNN-based architectures for document classification, information extraction, and question answering. We find that models supporting a rich answer space, such as word or character sequences, perform best. Our best-performing model, a word-level sequence to sequence model with a mechanism to copy out-of-vocabulary words, obtains an accuracy of 71.8%.
Hierarchical Question Answering for Long Documents
Feb 08, 2017
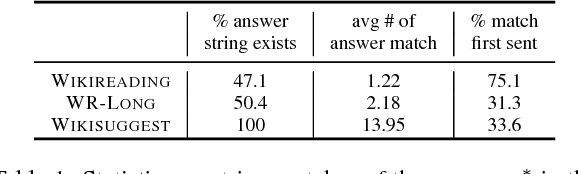


We present a framework for question answering that can efficiently scale to longer documents while maintaining or even improving performance of state-of-the-art models. While most successful approaches for reading comprehension rely on recurrent neural networks (RNNs), running them over long documents is prohibitively slow because it is difficult to parallelize over sequences. Inspired by how people first skim the document, identify relevant parts, and carefully read these parts to produce an answer, we combine a coarse, fast model for selecting relevant sentences and a more expensive RNN for producing the answer from those sentences. We treat sentence selection as a latent variable trained jointly from the answer only using reinforcement learning. Experiments demonstrate the state of the art performance on a challenging subset of the Wikireading and on a new dataset, while speeding up the model by 3.5x-6.7x.