 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantizing Intent: Cross-Domain Semantic IDs from Organic Activity for Industrial Ranking
May 31, 2026Ads click-through rate (CTR) prediction is constrained by sparse user supervision: most users engage with ads infrequently while generating dense behavioral evidence in organic surfaces such as feed. Transferring these cross-domain signals into ads ranking is difficult due to domain mismatch, serving cost, and production complexity. We introduce cross-domain user Semantic IDs (SIDs) derived from organic feed activity and show that behavioral activity richness governs cross-domain transfer quality: SIDs from user profile text yield +0.036% AUC, SIDs from an activity-tuned LLaMA-based user embedding model yield +0.107%, and SIDs from direct feed activity behavioral embeddings yield +0.213%. We further propose RQ-FSQ, a residual finite scalar quantization method that discretizes pre-trained embeddings while matching dense-embedding AUC at substantially smaller storage. Across two heterogeneous sources, RQ-FSQ matches or slightly exceeds dense source embeddings, achieving +0.351% AUC for Feed Activity at about 30x smaller storage and +0.265% AUC for Activity-Tuned LLaMA at about 280x smaller storage. We also introduce a Hierarchical Discrete Embedding module that encodes multi-level SIDs through prefix n-gram sparse embedding tables trained end-to-end under the CTR objective. In a large-scale industrial ads ranking system, cold-start segment analysis shows gains up to +1.522% for users with near-zero ad interaction history, validating cross-domain behavioral transfer as an effective bridge for sparse-history ranking.
Large Scalable Cross-Domain Graph Neural Networks for Personalized Notification at LinkedIn
Jun 15, 2025



Notification recommendation systems are critical to driving user engagement on professional platforms like LinkedIn. Designing such systems involves integrating heterogeneous signals across domains, capturing temporal dynamics, and optimizing for multiple, often competing, objectives. Graph Neural Networks (GNNs) provide a powerful framework for modeling complex interactions in such environments. In this paper, we present a cross-domain GNN-based system deployed at LinkedIn that unifies user, content, and activity signals into a single, large-scale graph. By training on this cross-domain structure, our model significantly outperforms single-domain baselines on key tasks, including click-through rate (CTR) prediction and professional engagement. We introduce architectural innovations including temporal modeling and multi-task learning, which further enhance performance. Deployed in LinkedIn's notification system, our approach led to a 0.10% lift in weekly active users and a 0.62% improvement in CTR. We detail our graph construction process, model design, training pipeline, and both offline and online evaluations. Our work demonstrates the scalability and effectiveness of cross-domain GNNs in real-world, high-impact applications.
Efficient Zero-shot Visual Search via Target and Context-aware Transformer
Nov 24, 2022
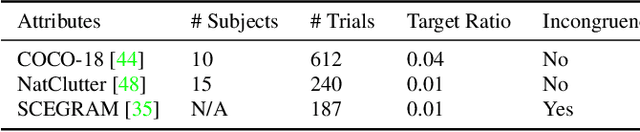


Visual search is a ubiquitous challenge in natural vision, including daily tasks such as finding a friend in a crowd or searching for a car in a parking lot. Human rely heavily on relevant target features to perform goal-directed visual search. Meanwhile, context is of critical importance for locating a target object in complex scenes as it helps narrow down the search area and makes the search process more efficient. However, few works have combined both target and context information in visual search computational models. Here we propose a zero-shot deep learning architecture, TCT (Target and Context-aware Transformer), that modulates self attention in the Vision Transformer with target and contextual relevant information to enable human-like zero-shot visual search performance. Target modulation is computed as patch-wise local relevance between the target and search images, whereas contextual modulation is applied in a global fashion. We conduct visual search experiments on TCT and other competitive visual search models on three natural scene datasets with varying levels of difficulty. TCT demonstrates human-like performance in terms of search efficiency and beats the SOTA models in challenging visual search tasks. Importantly, TCT generalizes well across datasets with novel objects without retraining or fine-tuning. Furthermore, we also introduce a new dataset to benchmark models for invariant visual search under incongruent contexts. TCT manages to search flexibly via target and context modulation, even under incongruent contexts.
The Sensorium competition on predicting large-scale mouse primary visual cortex activity
Jun 17, 2022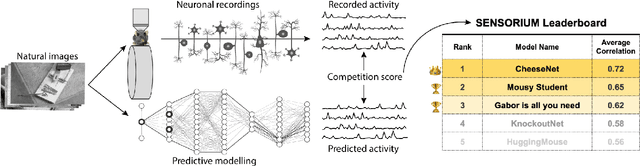
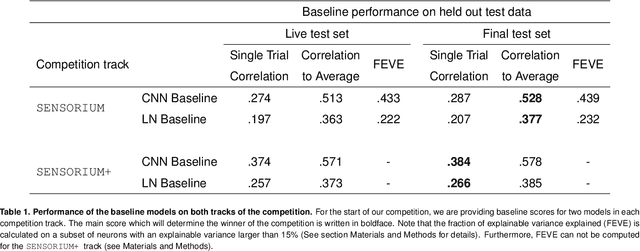
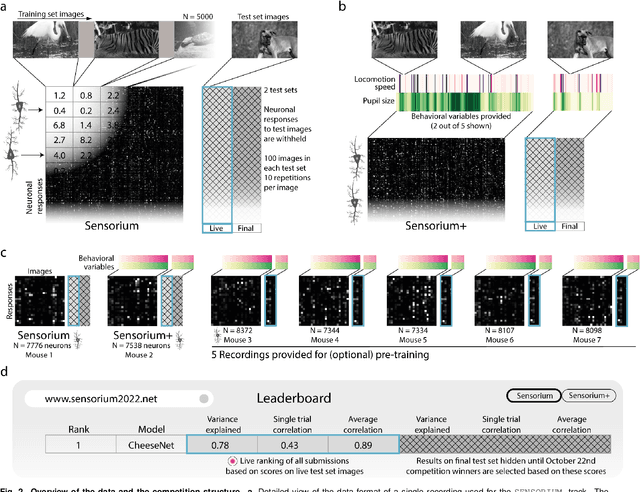
The neural underpinning of the biological visual system is challenging to study experimentally, in particular as the neuronal activity becomes increasingly nonlinear with respect to visual input. Artificial neural networks (ANNs) can serve a variety of goals for improving our understanding of this complex system, not only serving as predictive digital twins of sensory cortex for novel hypothesis generation in silico, but also incorporating bio-inspired architectural motifs to progressively bridge the gap between biological and machine vision. The mouse has recently emerged as a popular model system to study visual information processing, but no standardized large-scale benchmark to identify state-of-the-art models of the mouse visual system has been established. To fill this gap, we propose the Sensorium benchmark competition. We collected a large-scale dataset from mouse primary visual cortex containing the responses of more than 28,000 neurons across seven mice stimulated with thousands of natural images, together with simultaneous behavioral measurements that include running speed, pupil dilation, and eye movements. The benchmark challenge will rank models based on predictive performance for neuronal responses on a held-out test set, and includes two tracks for model input limited to either stimulus only (Sensorium) or stimulus plus behavior (Sensorium+). We provide a starting kit to lower the barrier for entry, including tutorials, pre-trained baseline models, and APIs with one line commands for data loading and submission. We would like to see this as a starting point for regular challenges and data releases, and as a standard tool for measuring progress in large-scale neural system identification models of the mouse visual system and beyond.