 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Zero-shot Visual Search via Target and Context-aware Transformer
Nov 24, 2022
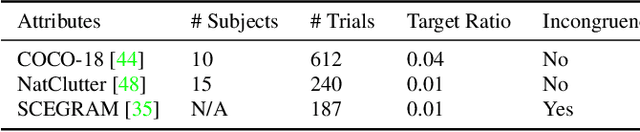


Visual search is a ubiquitous challenge in natural vision, including daily tasks such as finding a friend in a crowd or searching for a car in a parking lot. Human rely heavily on relevant target features to perform goal-directed visual search. Meanwhile, context is of critical importance for locating a target object in complex scenes as it helps narrow down the search area and makes the search process more efficient. However, few works have combined both target and context information in visual search computational models. Here we propose a zero-shot deep learning architecture, TCT (Target and Context-aware Transformer), that modulates self attention in the Vision Transformer with target and contextual relevant information to enable human-like zero-shot visual search performance. Target modulation is computed as patch-wise local relevance between the target and search images, whereas contextual modulation is applied in a global fashion. We conduct visual search experiments on TCT and other competitive visual search models on three natural scene datasets with varying levels of difficulty. TCT demonstrates human-like performance in terms of search efficiency and beats the SOTA models in challenging visual search tasks. Importantly, TCT generalizes well across datasets with novel objects without retraining or fine-tuning. Furthermore, we also introduce a new dataset to benchmark models for invariant visual search under incongruent contexts. TCT manages to search flexibly via target and context modulation, even under incongruent contexts.