 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Performance Envelope of DNN-based Recommendation Systems Inference on GPUs
Oct 29, 2024

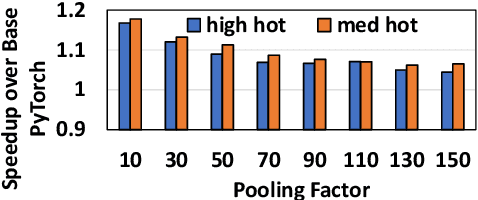

Personalized recommendation is a ubiquitous application on the internet, with many industries and hyperscalers extensively leveraging Deep Learning Recommendation Models (DLRMs) for their personalization needs (like ad serving or movie suggestions). With growing model and dataset sizes pushing computation and memory requirements, GPUs are being increasingly preferred for executing DLRM inference. However, serving newer DLRMs, while meeting acceptable latencies, continues to remain challenging, making traditional deployments increasingly more GPU-hungry, resulting in higher inference serving costs. In this paper, we show that the embedding stage continues to be the primary bottleneck in the GPU inference pipeline, leading up to a 3.2x embedding-only performance slowdown. To thoroughly grasp the problem, we conduct a detailed microarchitecture characterization and highlight the presence of low occupancy in the standard embedding kernels. By leveraging direct compiler optimizations, we achieve optimal occupancy, pushing the performance by up to 53%. Yet, long memory latency stalls continue to exist. To tackle this challenge, we propose specialized plug-and-play-based software prefetching and L2 pinning techniques, which help in hiding and decreasing the latencies. Further, we propose combining them, as they complement each other. Experimental evaluations using A100 GPUs with large models and datasets show that our proposed techniques improve performance by up to 103% for the embedding stage, and up to 77% for the overall DLRM inference pipeline.
Learn Locally, Correct Globally: A Distributed Algorithm for Training Graph Neural Networks
Dec 07, 2021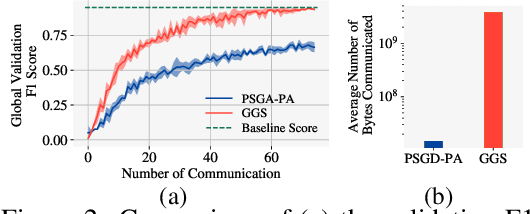

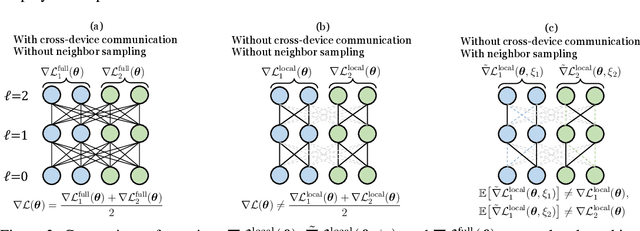
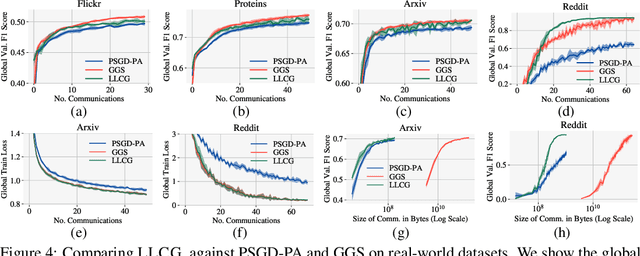
Despite the recent success of Graph Neural Networks (GNNs), training GNNs on large graphs remains challenging. The limited resource capacities of the existing servers, the dependency between nodes in a graph, and the privacy concern due to the centralized storage and model learning have spurred the need to design an effective distributed algorithm for GNN training. However, existing distributed GNN training methods impose either excessive communication costs or large memory overheads that hinders their scalability. To overcome these issues, we propose a communication-efficient distributed GNN training technique named $\text{{Learn Locally, Correct Globally}}$ (LLCG). To reduce the communication and memory overhead, each local machine in LLCG first trains a GNN on its local data by ignoring the dependency between nodes among different machines, then sends the locally trained model to the server for periodic model averaging. However, ignoring node dependency could result in significant performance degradation. To solve the performance degradation, we propose to apply $\text{{Global Server Corrections}}$ on the server to refine the locally learned models. We rigorously analyze the convergence of distributed methods with periodic model averaging for training GNNs and show that naively applying periodic model averaging but ignoring the dependency between nodes will suffer from an irreducible residual error. However, this residual error can be eliminated by utilizing the proposed global corrections to entail fast convergence rate. Extensive experiments on real-world datasets show that LLCG can significantly improve the efficiency without hurting the performance.
Predicting vehicular travel times by modeling heterogeneous influences between arterial roads
Nov 15, 2017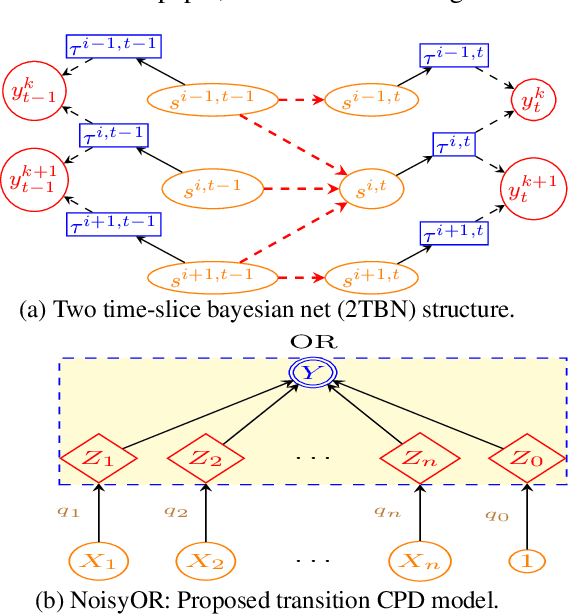

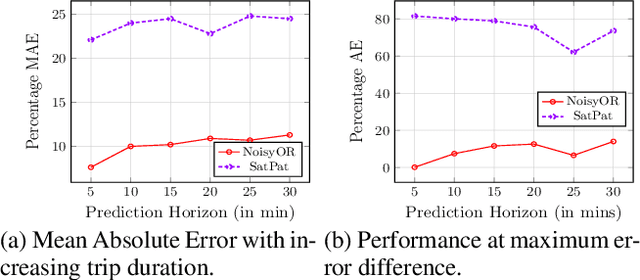
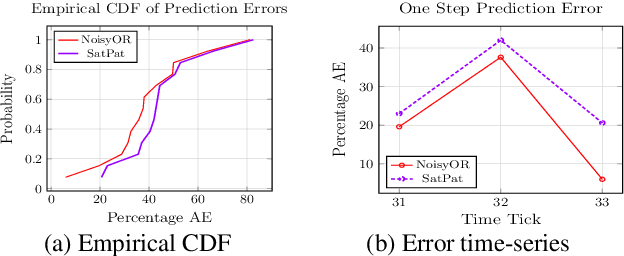
Predicting travel times of vehicles in urban settings is a useful and tangible quantity of interest in the context of intelligent transportation systems. We address the problem of travel time prediction in arterial roads using data sampled from probe vehicles. There is only a limited literature on methods using data input from probe vehicles. The spatio-temporal dependencies captured by existing data driven approaches are either too detailed or very simplistic. We strike a balance of the existing data driven approaches to account for varying degrees of influence a given road may experience from its neighbors, while controlling the number of parameters to be learnt. Specifically, we use a NoisyOR conditional probability distribution (CPD) in conjunction with a dynamic bayesian network (DBN) to model state transitions of various roads. We propose an efficient algorithm to learn model parameters. We propose an algorithm for predicting travel times on trips of arbitrary durations. Using synthetic and real world data traces we demonstrate the superior performance of the proposed method under different traffic conditions.