 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZSL-RPPO: Zero-Shot Learning for Quadrupedal Locomotion in Challenging Terrains using Recurrent Proximal Policy Optimization
Paper and Code
Mar 04, 2024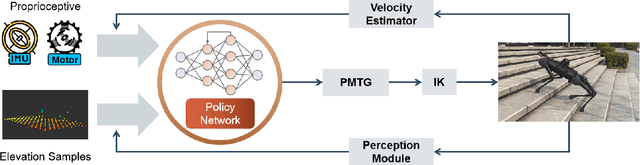
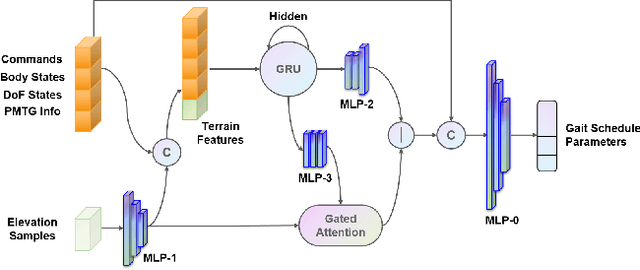
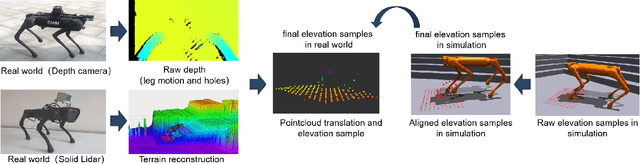
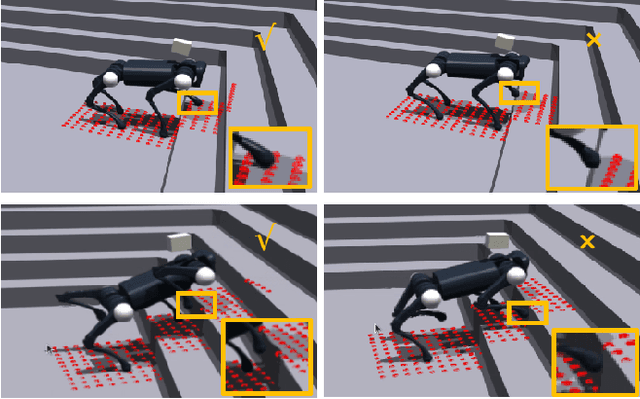
We present ZSL-RPPO, an improved zero-shot learning architecture that overcomes the limitations of teacher-student neural networks and enables generating robust, reliable, and versatile locomotion for quadrupedal robots in challenging terrains. We propose a new algorithm RPPO (Recurrent Proximal Policy Optimization) that directly trains recurrent neural network in partially observable environments and results in more robust training using domain randomization. Our locomotion controller supports extensive perturbation across simulation-to-reality transfer for both intrinsic and extrinsic physical parameters without further fine-tuning. This can avoid the significant decline of student's performance during simulation-to-reality transfer and therefore enhance the robustness and generalization of the locomotion controller. We deployed our controller on the Unitree A1 and Aliengo robots in real environment and exteroceptive perception is provided by either a solid-state Lidar or a depth camera. Our locomotion controller was tested in various challenging terrains like slippery surfaces, Grassy Terrain, and stairs. Our experiment results and comparison show that our approach significantly outperforms the state-of-the-art.