 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixFormer: Co-Scaling Up Dense and Sequence in Industrial Recommenders
Feb 15, 2026As industrial recommender systems enter a scaling-driven regime, Transformer architectures have become increasingly attractive for scaling models towards larger capacity and longer sequence. However, existing Transformer-based recommendation models remain structurally fragmented, where sequence modeling and feature interaction are implemented as separate modules with independent parameterization. Such designs introduce a fundamental co-scaling challenge, as model capacity must be suboptimally allocated between dense feature interaction and sequence modeling under a limited computational budget. In this work, we propose MixFormer, a unified Transformer-style architecture tailored for recommender systems, which jointly models sequential behaviors and feature interactions within a single backbone. Through a unified parameterization, MixFormer enables effective co-scaling across both dense capacity and sequence length, mitigating the trade-off observed in decoupled designs. Moreover, the integrated architecture facilitates deep interaction between sequential and non-sequential representations, allowing high-order feature semantics to directly inform sequence aggregation and enhancing overall expressiveness. To ensure industrial practicality, we further introduce a user-item decoupling strategy for efficiency optimizations that significantly reduce redundant computation and inference latency. Extensive experiments on large-scale industrial datasets demonstrate that MixFormer consistently exhibits superior accuracy and efficiency. Furthermore, large-scale online A/B tests on two production recommender systems, Douyin and Douyin Lite, show consistent improvements in user engagement metrics, including active days and in-app usage duration.
HyFormer: Revisiting the Roles of Sequence Modeling and Feature Interaction in CTR Prediction
Jan 19, 2026Industrial large-scale recommendation models (LRMs) face the challenge of jointly modeling long-range user behavior sequences and heterogeneous non-sequential features under strict efficiency constraints. However, most existing architectures employ a decoupled pipeline: long sequences are first compressed with a query-token based sequence compressor like LONGER, followed by fusion with dense features through token-mixing modules like RankMixer, which thereby limits both the representation capacity and the interaction flexibility. This paper presents HyFormer, a unified hybrid transformer architecture that tightly integrates long-sequence modeling and feature interaction into a single backbone. From the perspective of sequence modeling, we revisit and redesign query tokens in LRMs, and frame the LRM modeling task as an alternating optimization process that integrates two core components: Query Decoding which expands non-sequential features into Global Tokens and performs long sequence decoding over layer-wise key-value representations of long behavioral sequences; and Query Boosting which enhances cross-query and cross-sequence heterogeneous interactions via efficient token mixing. The two complementary mechanisms are performed iteratively to refine semantic representations across layers. Extensive experiments on billion-scale industrial datasets demonstrate that HyFormer consistently outperforms strong LONGER and RankMixer baselines under comparable parameter and FLOPs budgets, while exhibiting superior scaling behavior with increasing parameters and FLOPs. Large-scale online A/B tests in high-traffic production systems further validate its effectiveness, showing significant gains over deployed state-of-the-art models. These results highlight the practicality and scalability of HyFormer as a unified modeling framework for industrial LRMs.
Factorized-Dreamer: Training A High-Quality Video Generator with Limited and Low-Quality Data
Aug 19, 2024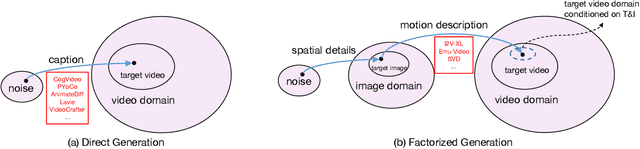
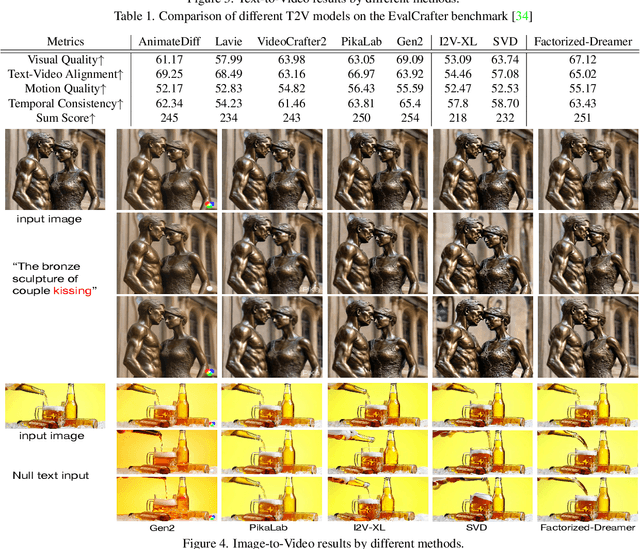
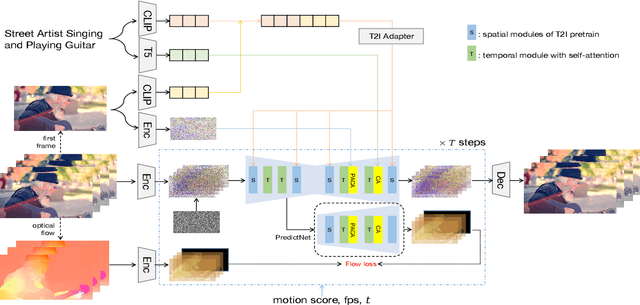

Text-to-video (T2V) generation has gained significant attention due to its wide applications to video generation, editing, enhancement and translation, \etc. However, high-quality (HQ) video synthesis is extremely challenging because of the diverse and complex motions existed in real world. Most existing works struggle to address this problem by collecting large-scale HQ videos, which are inaccessible to the community. In this work, we show that publicly available limited and low-quality (LQ) data are sufficient to train a HQ video generator without recaptioning or finetuning. We factorize the whole T2V generation process into two steps: generating an image conditioned on a highly descriptive caption, and synthesizing the video conditioned on the generated image and a concise caption of motion details. Specifically, we present \emph{Factorized-Dreamer}, a factorized spatiotemporal framework with several critical designs for T2V generation, including an adapter to combine text and image embeddings, a pixel-aware cross attention module to capture pixel-level image information, a T5 text encoder to better understand motion description, and a PredictNet to supervise optical flows. We further present a noise schedule, which plays a key role in ensuring the quality and stability of video generation. Our model lowers the requirements in detailed captions and HQ videos, and can be directly trained on limited LQ datasets with noisy and brief captions such as WebVid-10M, largely alleviating the cost to collect large-scale HQ video-text pairs. Extensive experiments in a variety of T2V and image-to-video generation tasks demonstrate the effectiveness of our proposed Factorized-Dreamer. Our source codes are available at \url{https://github.com/yangxy/Factorized-Dreamer/}.
Breast Lesion Diagnosis Using Static Images and Dynamic Video
Aug 19, 2023


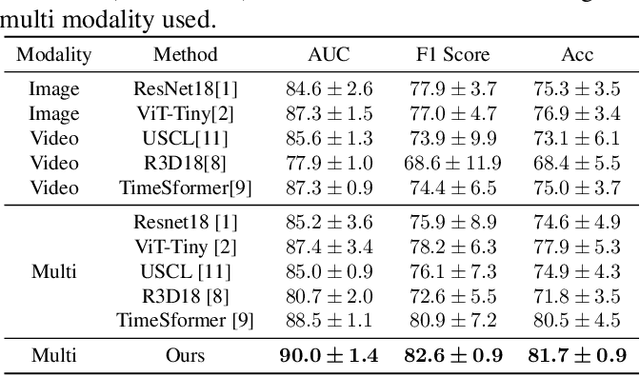
Deep learning based Computer Aided Diagnosis (CAD) systems have been developed to treat breast ultrasound. Most of them focus on a single ultrasound imaging modality, either using representative static images or the dynamic video of a real-time scan. In fact, these two image modalities are complementary for lesion diagnosis. Dynamic videos provide detailed three-dimensional information about the lesion, while static images capture the typical sections of the lesion. In this work, we propose a multi-modality breast tumor diagnosis model to imitate the diagnosing process of radiologists, which learns the features of both static images and dynamic video and explores the potential relationship between the two modalities. Considering that static images are carefully selected by professional radiologists, we propose to aggregate dynamic video features under the guidance of domain knowledge from static images before fusing multi-modality features. Our work is validated on a breast ultrasound dataset composed of 897 sets of ultrasound images and videos. Experimental results show that our model boosts the performance of Benign/Malignant classification, achieving 90.0% in AUC and 81.7% in accuracy.