 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLowDiff: Efficient Diffusion Sampling with Low-Resolution Condition
Sep 18, 2025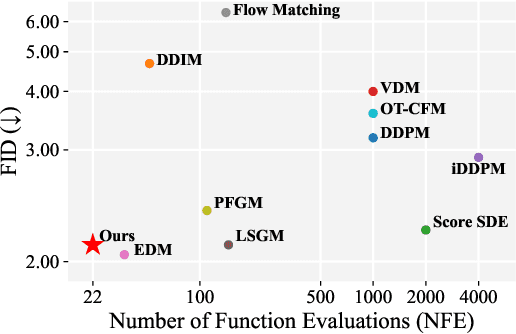
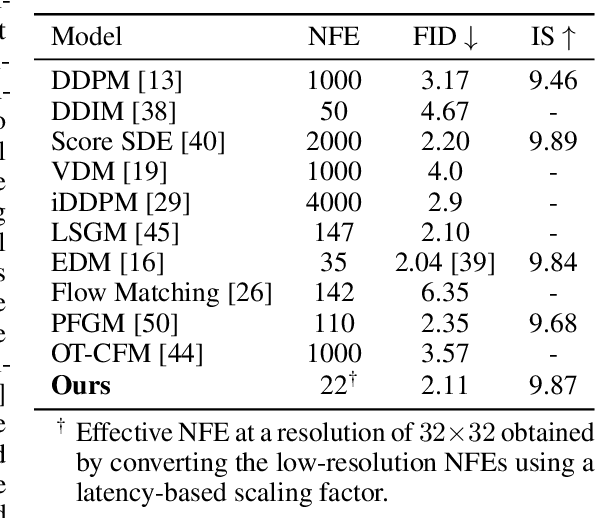
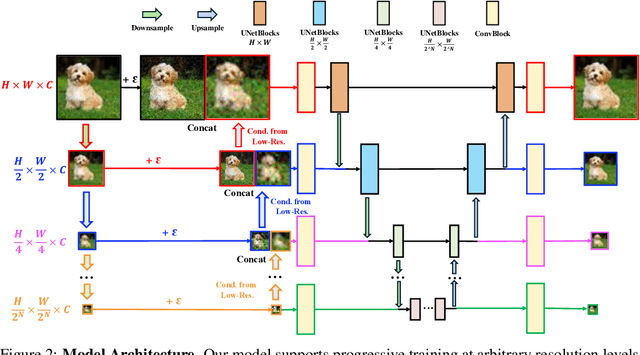
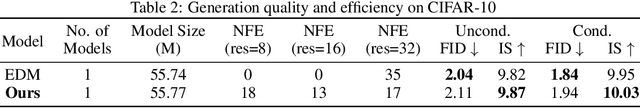
Diffusion models have achieved remarkable success in image generation but their practical application is often hindered by the slow sampling speed. Prior efforts of improving efficiency primarily focus on compressing models or reducing the total number of denoising steps, largely neglecting the possibility to leverage multiple input resolutions in the generation process. In this work, we propose LowDiff, a novel and efficient diffusion framework based on a cascaded approach by generating increasingly higher resolution outputs. Besides, LowDiff employs a unified model to progressively refine images from low resolution to the desired resolution. With the proposed architecture design and generation techniques, we achieve comparable or even superior performance with much fewer high-resolution sampling steps. LowDiff is applicable to diffusion models in both pixel space and latent space. Extensive experiments on both conditional and unconditional generation tasks across CIFAR-10, FFHQ and ImageNet demonstrate the effectiveness and generality of our method. Results show over 50% throughput improvement across all datasets and settings while maintaining comparable or better quality. On unconditional CIFAR-10, LowDiff achieves an FID of 2.11 and IS of 9.87, while on conditional CIFAR-10, an FID of 1.94 and IS of 10.03. On FFHQ 64x64, LowDiff achieves an FID of 2.43, and on ImageNet 256x256, LowDiff built on LightningDiT-B/1 produces high-quality samples with a FID of 4.00 and an IS of 195.06, together with substantial efficiency gains.
IDU: Incremental Dynamic Update of Existing 3D Virtual Environments with New Imagery Data
Aug 25, 2025For simulation and training purposes, military organizations have made substantial investments in developing high-resolution 3D virtual environments through extensive imaging and 3D scanning. However, the dynamic nature of battlefield conditions-where objects may appear or vanish over time-makes frequent full-scale updates both time-consuming and costly. In response, we introduce the Incremental Dynamic Update (IDU) pipeline, which efficiently updates existing 3D reconstructions, such as 3D Gaussian Splatting (3DGS), with only a small set of newly acquired images. Our approach starts with camera pose estimation to align new images with the existing 3D model, followed by change detection to pinpoint modifications in the scene. A 3D generative AI model is then used to create high-quality 3D assets of the new elements, which are seamlessly integrated into the existing 3D model. The IDU pipeline incorporates human guidance to ensure high accuracy in object identification and placement, with each update focusing on a single new object at a time. Experimental results confirm that our proposed IDU pipeline significantly reduces update time and labor, offering a cost-effective and targeted solution for maintaining up-to-date 3D models in rapidly evolving military scenarios.
Open-Vocabulary High-Resolution 3D (OVHR3D) Data Segmentation and Annotation Framework
Dec 09, 2024In the domain of the U.S. Army modeling and simulation, the availability of high quality annotated 3D data is pivotal to creating virtual environments for training and simulations. Traditional methodologies for 3D semantic and instance segmentation, such as KpConv, RandLA, Mask3D, etc., are designed to train on extensive labeled datasets to obtain satisfactory performance in practical tasks. This requirement presents a significant challenge, given the inherent scarcity of manually annotated 3D datasets, particularly for the military use cases. Recognizing this gap, our previous research leverages the One World Terrain data repository manually annotated databases, as showcased at IITSEC 2019 and 2021, to enrich the training dataset for deep learning models. However, collecting and annotating large scale 3D data for specific tasks remains costly and inefficient. To this end, the objective of this research is to design and develop a comprehensive and efficient framework for 3D segmentation tasks to assist in 3D data annotation. This framework integrates Grounding DINO and Segment anything Model, augmented by an enhancement in 2D image rendering via 3D mesh. Furthermore, the authors have also developed a user friendly interface that facilitates the 3D annotation process, offering intuitive visualization of rendered images and the 3D point cloud.
Factorized-Dreamer: Training A High-Quality Video Generator with Limited and Low-Quality Data
Aug 19, 2024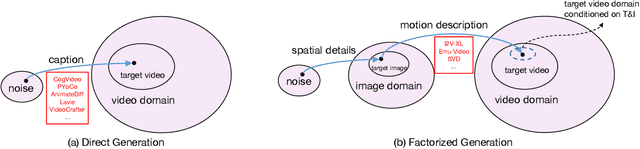
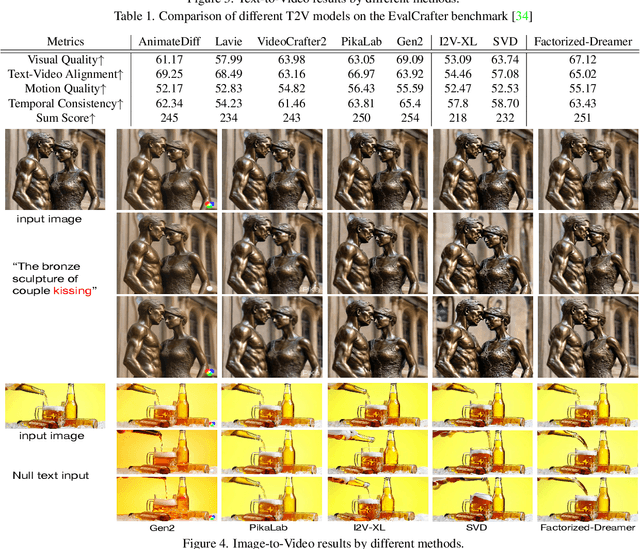
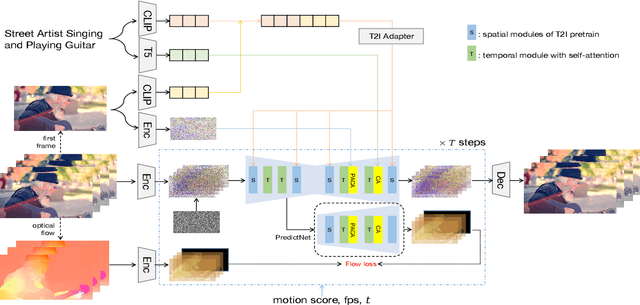

Text-to-video (T2V) generation has gained significant attention due to its wide applications to video generation, editing, enhancement and translation, \etc. However, high-quality (HQ) video synthesis is extremely challenging because of the diverse and complex motions existed in real world. Most existing works struggle to address this problem by collecting large-scale HQ videos, which are inaccessible to the community. In this work, we show that publicly available limited and low-quality (LQ) data are sufficient to train a HQ video generator without recaptioning or finetuning. We factorize the whole T2V generation process into two steps: generating an image conditioned on a highly descriptive caption, and synthesizing the video conditioned on the generated image and a concise caption of motion details. Specifically, we present \emph{Factorized-Dreamer}, a factorized spatiotemporal framework with several critical designs for T2V generation, including an adapter to combine text and image embeddings, a pixel-aware cross attention module to capture pixel-level image information, a T5 text encoder to better understand motion description, and a PredictNet to supervise optical flows. We further present a noise schedule, which plays a key role in ensuring the quality and stability of video generation. Our model lowers the requirements in detailed captions and HQ videos, and can be directly trained on limited LQ datasets with noisy and brief captions such as WebVid-10M, largely alleviating the cost to collect large-scale HQ video-text pairs. Extensive experiments in a variety of T2V and image-to-video generation tasks demonstrate the effectiveness of our proposed Factorized-Dreamer. Our source codes are available at \url{https://github.com/yangxy/Factorized-Dreamer/}.
APRNet: Attention-based Pixel-wise Rendering Network for Photo-Realistic Text Image Generation
Mar 15, 2022



Style-guided text image generation tries to synthesize text image by imitating reference image's appearance while keeping text content unaltered. The text image appearance includes many aspects. In this paper, we focus on transferring style image's background and foreground color patterns to the content image to generate photo-realistic text image. To achieve this goal, we propose 1) a content-style cross attention based pixel sampling approach to roughly mimicking the style text image's background; 2) a pixel-wise style modulation technique to transfer varying color patterns of the style image to the content image spatial-adaptively; 3) a cross attention based multi-scale style fusion approach to solving text foreground misalignment issue between style and content images; 4) an image patch shuffling strategy to create style, content and ground truth image tuples for training. Experimental results on Chinese handwriting text image synthesis with SCUT-HCCDoc and CASIA-OLHWDB datasets demonstrate that the proposed method can improve the quality of synthetic text images and make them more photo-realistic.
Low-light Image Enhancement Algorithm Based on Retinex and Generative Adversarial Network
Jun 14, 2019


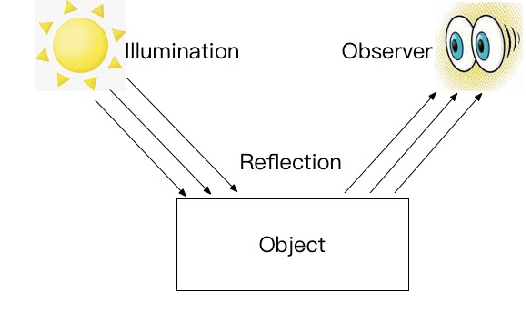
Low-light image enhancement is generally regarded as a challenging task in image processing, especially for the complex visual tasks at night or weakly illuminated. In order to reduce the blurs or noises on the low-light images, a large number of papers have contributed to applying different technologies. Regretfully, most of them had served little purposes in coping with the extremely poor illumination parts of images or test in practice. In this work, the authors propose a novel approach for processing low-light images based on the Retinex theory and generative adversarial network (GAN), which is composed of the decomposition part for splitting the image into illumination image and reflected image, and the enhancement part for generating high-quality image. Such a discriminative network is expected to make the generated image clearer. Couples of experiments have been implemented under the circumstance of different lighting strength on the basis of Converted See-In-the-Dark (CSID) datasets, and the satisfactory results have been achieved with exceeding expectation that much encourages the authors. In a word, the proposed GAN-based network and employed Retinex theory in this work have proven to be effective in dealing with the low-light image enhancement problems, which will benefit the image processing with no doubt.