 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Vocabulary High-Resolution 3D (OVHR3D) Data Segmentation and Annotation Framework
Dec 09, 2024In the domain of the U.S. Army modeling and simulation, the availability of high quality annotated 3D data is pivotal to creating virtual environments for training and simulations. Traditional methodologies for 3D semantic and instance segmentation, such as KpConv, RandLA, Mask3D, etc., are designed to train on extensive labeled datasets to obtain satisfactory performance in practical tasks. This requirement presents a significant challenge, given the inherent scarcity of manually annotated 3D datasets, particularly for the military use cases. Recognizing this gap, our previous research leverages the One World Terrain data repository manually annotated databases, as showcased at IITSEC 2019 and 2021, to enrich the training dataset for deep learning models. However, collecting and annotating large scale 3D data for specific tasks remains costly and inefficient. To this end, the objective of this research is to design and develop a comprehensive and efficient framework for 3D segmentation tasks to assist in 3D data annotation. This framework integrates Grounding DINO and Segment anything Model, augmented by an enhancement in 2D image rendering via 3D mesh. Furthermore, the authors have also developed a user friendly interface that facilitates the 3D annotation process, offering intuitive visualization of rendered images and the 3D point cloud.
TokenMotion: Motion-Guided Vision Transformer for Video Camouflaged Object Detection Via Learnable Token Selection
Nov 05, 2023



The area of Video Camouflaged Object Detection (VCOD) presents unique challenges in the field of computer vision due to texture similarities between target objects and their surroundings, as well as irregular motion patterns caused by both objects and camera movement. In this paper, we introduce TokenMotion (TMNet), which employs a transformer-based model to enhance VCOD by extracting motion-guided features using a learnable token selection. Evaluated on the challenging MoCA-Mask dataset, TMNet achieves state-of-the-art performance in VCOD. It outperforms the existing state-of-the-art method by a 12.8% improvement in weighted F-measure, an 8.4% enhancement in S-measure, and a 10.7% boost in mean IoU. The results demonstrate the benefits of utilizing motion-guided features via learnable token selection within a transformer-based framework to tackle the intricate task of VCOD.
Frequency-domain Learning for Volumetric-based 3D Data Perception
Feb 20, 2023



Frequency-domain learning draws attention due to its superior tradeoff between inference accuracy and input data size. Frequency-domain learning in 2D computer vision tasks has shown that 2D convolutional neural networks (CNN) have a stationary spectral bias towards low-frequency channels so that high-frequency channels can be pruned with no or little accuracy degradation. However, frequency-domain learning has not been studied in the context of 3D CNNs with 3D volumetric data. In this paper, we study frequency-domain learning for volumetric-based 3D data perception to reveal the spectral bias and the accuracy-input-data-size tradeoff of 3D CNNs. Our study finds that 3D CNNs are sensitive to a limited number of critical frequency channels, especially low-frequency channels. Experiment results show that frequency-domain learning can significantly reduce the size of volumetric-based 3D inputs (based on spectral bias) while achieving comparable accuracy with conventional spatial-domain learning approaches. Specifically, frequency-domain learning is able to reduce the input data size by 98% in 3D shape classification while limiting the average accuracy drop within 2%, and by 98% in the 3D point cloud semantic segmentation with a 1.48% mean-class accuracy improvement while limiting the mean-class IoU loss within 1.55%. Moreover, by learning from higher-resolution 3D data (i.e., 2x of the original image in the spatial domain), frequency-domain learning improves the mean-class accuracy and mean-class IoU by 3.04% and 0.63%, respectively, while achieving an 87.5% input data size reduction in 3D point cloud semantic segmentation.
TransUPR: A Transformer-based Uncertain Point Refiner for LiDAR Point Cloud Semantic Segmentation
Feb 20, 2023



In this work, we target the problem of uncertain points refinement for image-based LiDAR point cloud semantic segmentation (LiDAR PCSS). This problem mainly results from the boundary-blurring problem of convolution neural networks (CNNs) and quantitation loss of spherical projection, which are often hard to avoid for common image-based LiDAR PCSS approaches. We propose a plug-and-play transformer-based uncertain point refiner (TransUPR) to address the problem. Through local feature aggregation, uncertain point localization, and self-attention-based transformer design, TransUPR, integrated into an existing range image-based LiDAR PCSS approach (e.g., CENet), achieves the state-of-the-art performance (68.2% mIoU) on Semantic-KITTI benchmark, which provides a performance improvement of 0.6% on the mIoU.
Enhanced Low-resolution LiDAR-Camera Calibration Via Depth Interpolation and Supervised Contrastive Learning
Nov 08, 2022



Motivated by the increasing application of low-resolution LiDAR recently, we target the problem of low-resolution LiDAR-camera calibration in this work. The main challenges are two-fold: sparsity and noise in point clouds. To address the problem, we propose to apply depth interpolation to increase the point density and supervised contrastive learning to learn noise-resistant features. The experiments on RELLIS-3D demonstrate that our approach achieves an average mean absolute rotation/translation errors of 0.15cm/0.33\textdegree on 32-channel LiDAR point cloud data, which significantly outperforms all reference methods.
Automatic Error Detection in Integrated Circuits Image Segmentation: A Data-driven Approach
Nov 08, 2022
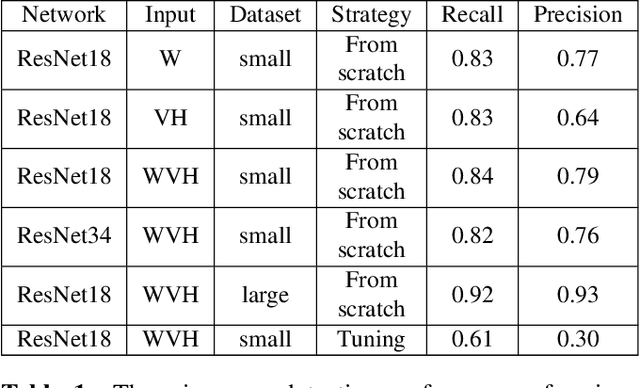
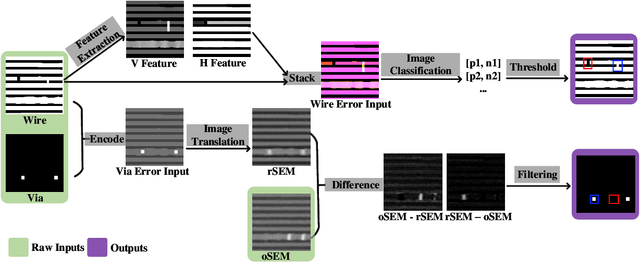

Due to the complicated nanoscale structures of current integrated circuits(IC) builds and low error tolerance of IC image segmentation tasks, most existing automated IC image segmentation approaches require human experts for visual inspection to ensure correctness, which is one of the major bottlenecks in large-scale industrial applications. In this paper, we present the first data-driven automatic error detection approach targeting two types of IC segmentation errors: wire errors and via errors. On an IC image dataset collected from real industry, we demonstrate that, by adapting existing CNN-based approaches of image classification and image translation with additional pre-processing and post-processing techniques, we are able to achieve recall/precision of 0.92/0.93 in wire error detection and 0.96/0.90 in via error detection, respectively.
Object Detection on Single Monocular Images through Canonical Correlation Analysis
Feb 13, 2020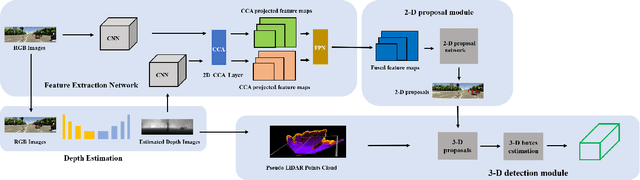
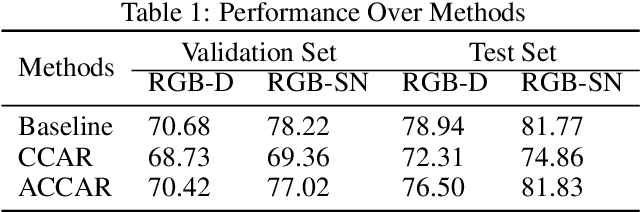


Without using extra 3-D data like points cloud or depth images for providing 3-D information, we retrieve the 3-D object information from single monocular images. The high-quality predicted depth images are recovered from single monocular images, and it is fed into the 2-D object proposal network with corresponding monocular images. Most existing deep learning frameworks with two-streams input data always fuse separate data by concatenating or adding, which views every part of a feature map can contribute equally to the whole task. However, when data are noisy, and too much information is redundant, these methods no longer produce predictions or classifications efficiently. In this report, we propose a two-dimensional CCA(canonical correlation analysis) framework to fuse monocular images and corresponding predicted depth images for basic computer vision tasks like image classification and object detection. Firstly, we implemented different structures with one-dimensional CCA and Alexnet to test the performance on the image classification task. And then, we applied one of these structures with 2D-CCA for object detection. During these experiments, we found that our proposed framework behaves better when taking predicted depth images as inputs with the model trained from ground truth depth.