 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Detection on Single Monocular Images through Canonical Correlation Analysis
Paper and Code
Feb 13, 2020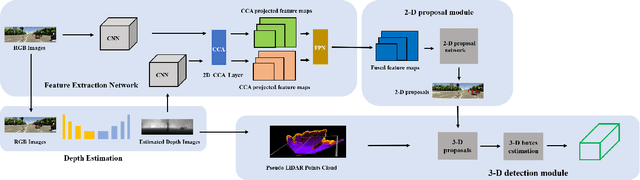
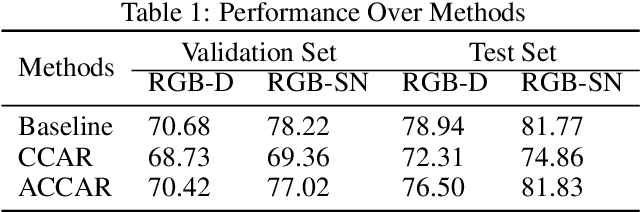


Without using extra 3-D data like points cloud or depth images for providing 3-D information, we retrieve the 3-D object information from single monocular images. The high-quality predicted depth images are recovered from single monocular images, and it is fed into the 2-D object proposal network with corresponding monocular images. Most existing deep learning frameworks with two-streams input data always fuse separate data by concatenating or adding, which views every part of a feature map can contribute equally to the whole task. However, when data are noisy, and too much information is redundant, these methods no longer produce predictions or classifications efficiently. In this report, we propose a two-dimensional CCA(canonical correlation analysis) framework to fuse monocular images and corresponding predicted depth images for basic computer vision tasks like image classification and object detection. Firstly, we implemented different structures with one-dimensional CCA and Alexnet to test the performance on the image classification task. And then, we applied one of these structures with 2D-CCA for object detection. During these experiments, we found that our proposed framework behaves better when taking predicted depth images as inputs with the model trained from ground truth depth.