 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenMotion: Motion-Guided Vision Transformer for Video Camouflaged Object Detection Via Learnable Token Selection
Nov 05, 2023



The area of Video Camouflaged Object Detection (VCOD) presents unique challenges in the field of computer vision due to texture similarities between target objects and their surroundings, as well as irregular motion patterns caused by both objects and camera movement. In this paper, we introduce TokenMotion (TMNet), which employs a transformer-based model to enhance VCOD by extracting motion-guided features using a learnable token selection. Evaluated on the challenging MoCA-Mask dataset, TMNet achieves state-of-the-art performance in VCOD. It outperforms the existing state-of-the-art method by a 12.8% improvement in weighted F-measure, an 8.4% enhancement in S-measure, and a 10.7% boost in mean IoU. The results demonstrate the benefits of utilizing motion-guided features via learnable token selection within a transformer-based framework to tackle the intricate task of VCOD.
BRDS: An FPGA-based LSTM Accelerator with Row-Balanced Dual-Ratio Sparsification
Jan 07, 2021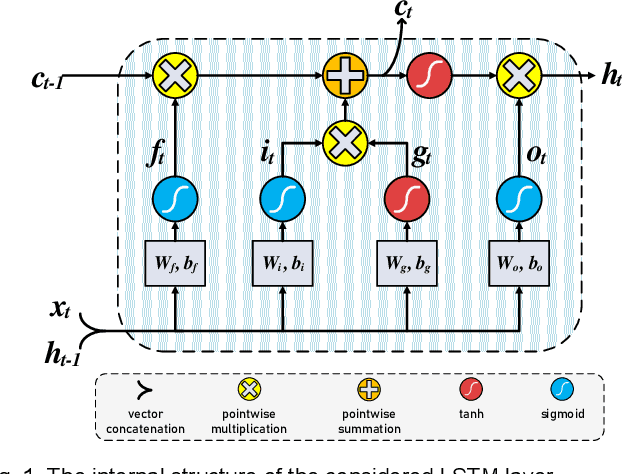

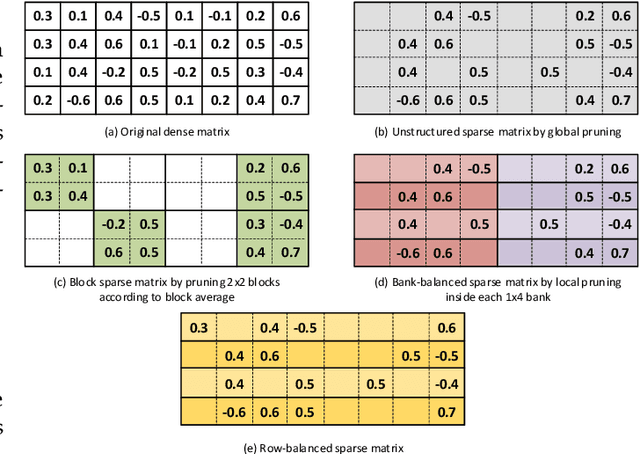
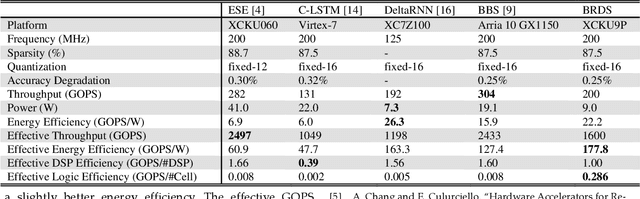
In this paper, first, a hardware-friendly pruning algorithm for reducing energy consumption and improving the speed of Long Short-Term Memory (LSTM) neural network accelerators is presented. Next, an FPGA-based platform for efficient execution of the pruned networks based on the proposed algorithm is introduced. By considering the sensitivity of two weight matrices of the LSTM models in pruning, different sparsity ratios (i.e., dual-ratio sparsity) are applied to these weight matrices. To reduce memory accesses, a row-wise sparsity pattern is adopted. The proposed hardware architecture makes use of computation overlapping and pipelining to achieve low-power and high-speed. The effectiveness of the proposed pruning algorithm and accelerator is assessed under some benchmarks for natural language processing, binary sentiment classification, and speech recognition. Results show that, e.g., compared to a recently published work in this field, the proposed accelerator could provide up to 272% higher effective GOPS/W and the perplexity error is reduced by up to 1.4% for the PTB dataset.
HALO 1.0: A Hardware-agnostic Accelerator Orchestration Framework for Enabling Hardware-agnostic Programming with True Performance Portability for Heterogeneous HPC
Nov 22, 2020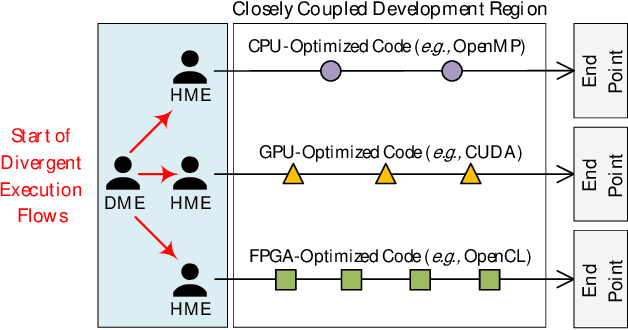
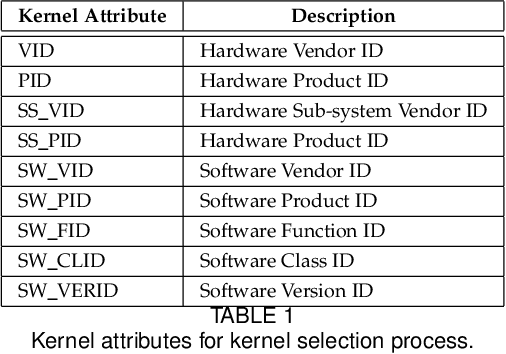
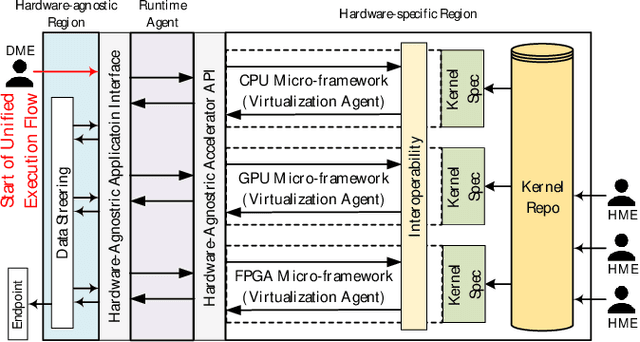
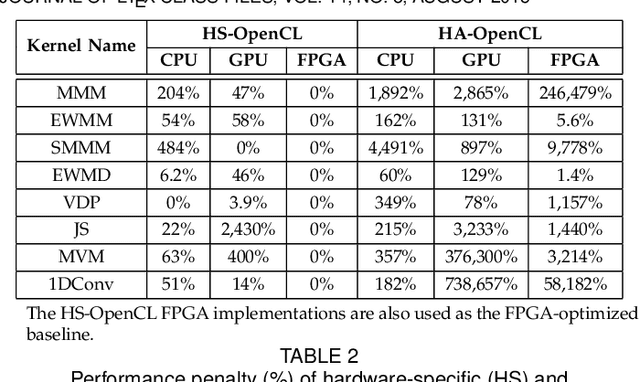
Hardware-agnostic programming with high performance portability will be the bedrock for realizing the ubiquitous adoption of emerging accelerator technologies in future heterogeneous high-performance computing (HPC) systems, which is the key to achieving the next level of HPC performance on an expanding accelerator landscape. In this paper, we present HALO 1.0, an open-ended extensible multi-agent software framework, that implements a set of proposed hardware-agnostic accelerator orchestration (HALO) principles and a novel compute-centric message passing interface (C^2MPI) specification for enabling the portable and performance-optimized execution of hardware-agnostic application codes across heterogeneous accelerator resources. The experiment results of evaluating eight widely used HPC subroutines based on Intel Xeon E5-2620 v4 CPUs, Intel Arria 10 GX FPGAs, and NVIDIA GeForce RTX 2080 Ti GPUs show that HALO 1.0 allows the same hardware-agnostic application codes of the HPC kernels, without any change, to run across all the computing devices with a consistently maximum performance portability score of 1.0, which is 2x-861,883x higher than the OpenCL-based solution that suffers from an unstably low performance portability score.