 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRDS: An FPGA-based LSTM Accelerator with Row-Balanced Dual-Ratio Sparsification
Paper and Code
Jan 07, 2021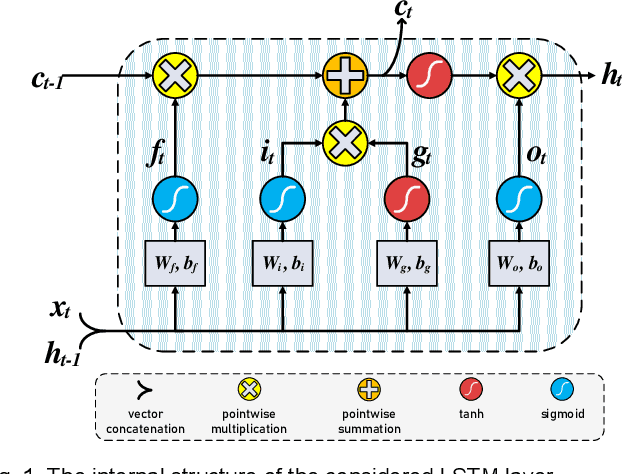

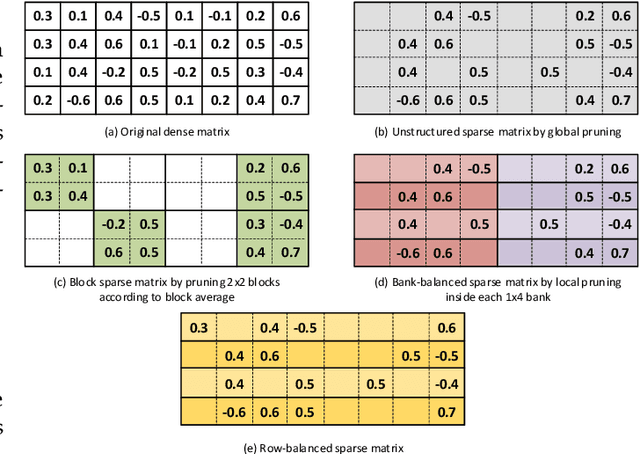
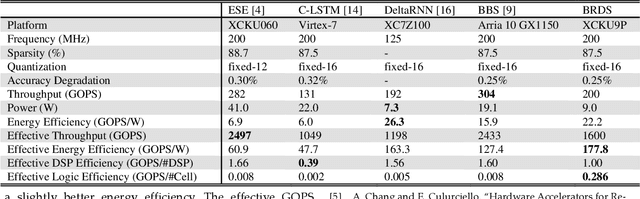
In this paper, first, a hardware-friendly pruning algorithm for reducing energy consumption and improving the speed of Long Short-Term Memory (LSTM) neural network accelerators is presented. Next, an FPGA-based platform for efficient execution of the pruned networks based on the proposed algorithm is introduced. By considering the sensitivity of two weight matrices of the LSTM models in pruning, different sparsity ratios (i.e., dual-ratio sparsity) are applied to these weight matrices. To reduce memory accesses, a row-wise sparsity pattern is adopted. The proposed hardware architecture makes use of computation overlapping and pipelining to achieve low-power and high-speed. The effectiveness of the proposed pruning algorithm and accelerator is assessed under some benchmarks for natural language processing, binary sentiment classification, and speech recognition. Results show that, e.g., compared to a recently published work in this field, the proposed accelerator could provide up to 272% higher effective GOPS/W and the perplexity error is reduced by up to 1.4% for the PTB dataset.