 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2P-MANN: Adaptive Attention Inference Hops Pruned Memory-Augmented Neural Networks
Jan 24, 2021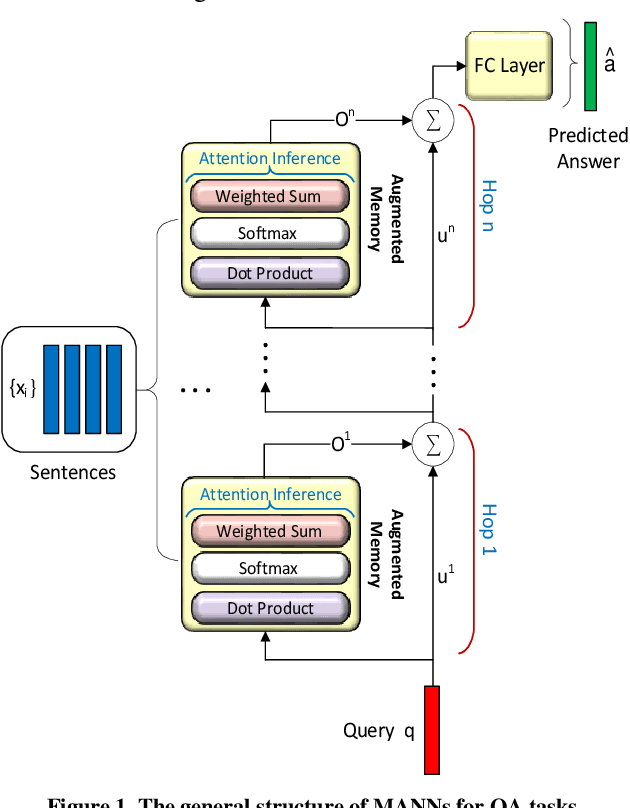
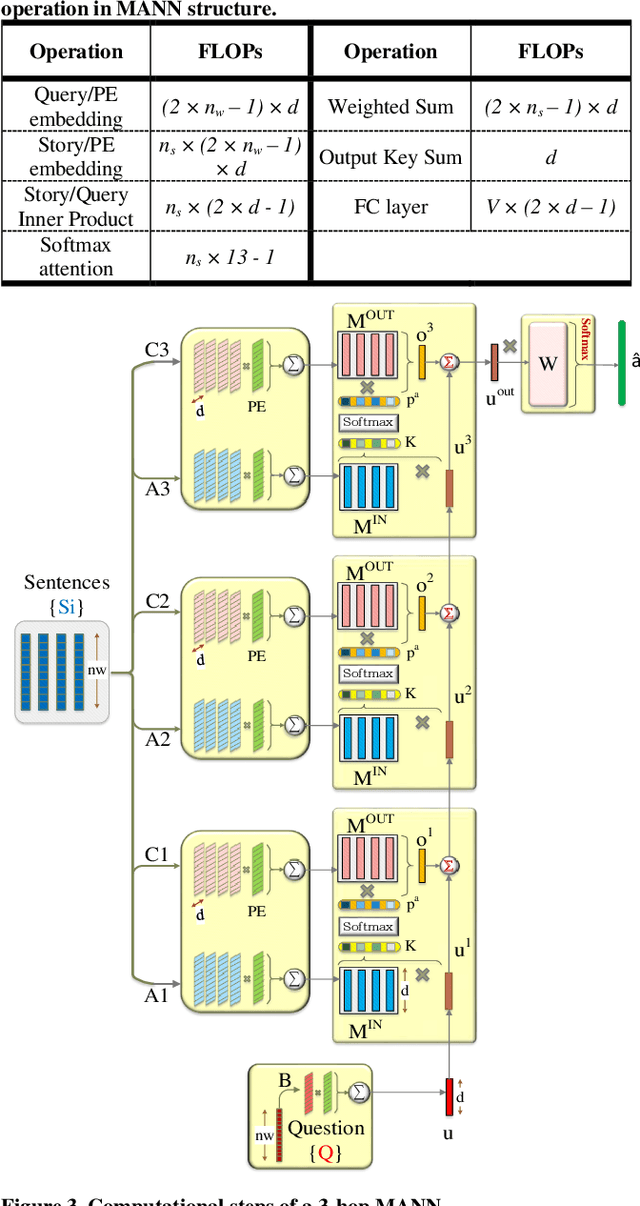
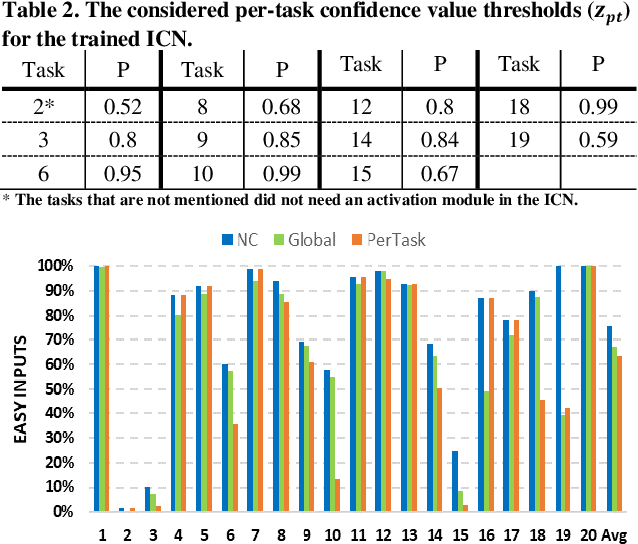

In this work, to limit the number of required attention inference hops in memory-augmented neural networks, we propose an online adaptive approach called A2P-MANN. By exploiting a small neural network classifier, an adequate number of attention inference hops for the input query is determined. The technique results in elimination of a large number of unnecessary computations in extracting the correct answer. In addition, to further lower computations in A2P-MANN, we suggest pruning weights of the final FC (fully-connected) layers. To this end, two pruning approaches, one with negligible accuracy loss and the other with controllable loss on the final accuracy, are developed. The efficacy of the technique is assessed by using the twenty question-answering (QA) tasks of bAbI dataset. The analytical assessment reveals, on average, more than 42% fewer computations compared to the baseline MANN at the cost of less than 1% accuracy loss. In addition, when used along with the previously published zero-skipping technique, a computation count reduction of up to 68% is achieved. Finally, when the proposed approach (without zero-skipping) is implemented on the CPU and GPU platforms, up to 43% runtime reduction is achieved.
BRDS: An FPGA-based LSTM Accelerator with Row-Balanced Dual-Ratio Sparsification
Jan 07, 2021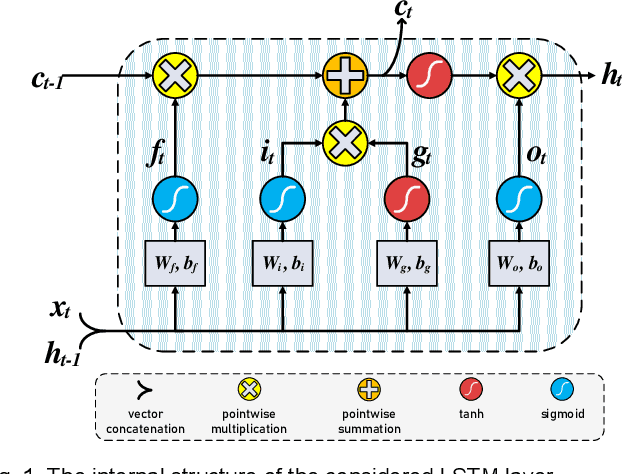

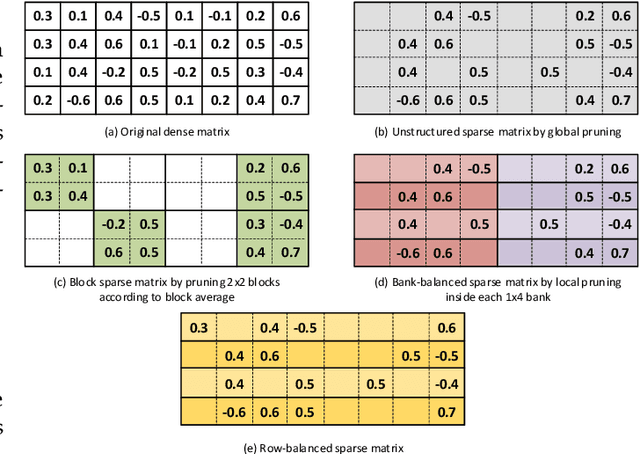
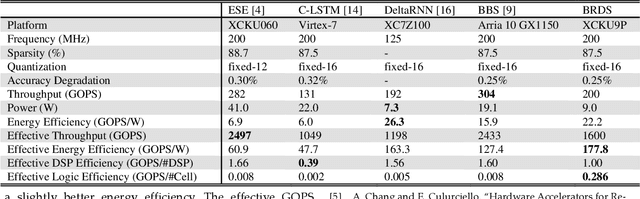
In this paper, first, a hardware-friendly pruning algorithm for reducing energy consumption and improving the speed of Long Short-Term Memory (LSTM) neural network accelerators is presented. Next, an FPGA-based platform for efficient execution of the pruned networks based on the proposed algorithm is introduced. By considering the sensitivity of two weight matrices of the LSTM models in pruning, different sparsity ratios (i.e., dual-ratio sparsity) are applied to these weight matrices. To reduce memory accesses, a row-wise sparsity pattern is adopted. The proposed hardware architecture makes use of computation overlapping and pipelining to achieve low-power and high-speed. The effectiveness of the proposed pruning algorithm and accelerator is assessed under some benchmarks for natural language processing, binary sentiment classification, and speech recognition. Results show that, e.g., compared to a recently published work in this field, the proposed accelerator could provide up to 272% higher effective GOPS/W and the perplexity error is reduced by up to 1.4% for the PTB dataset.
Space Expansion of Feature Selection for Designing more Accurate Error Predictors
Dec 30, 2018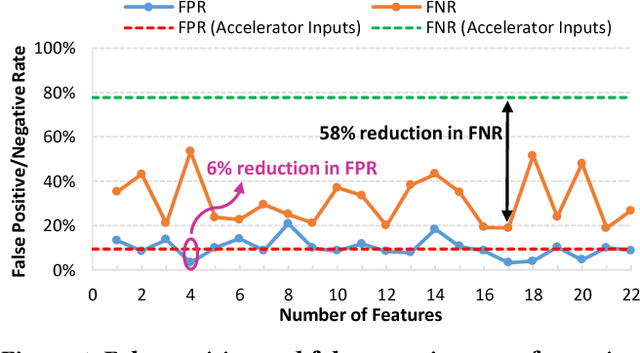

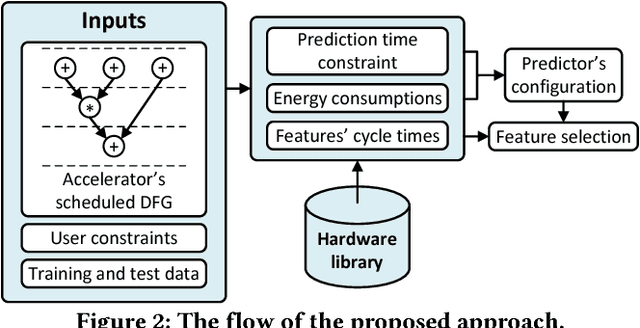
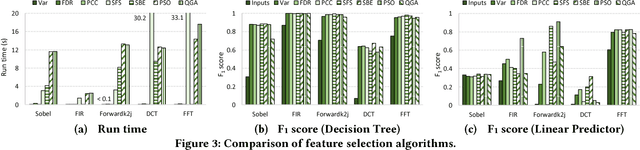
Approximate computing is being considered as a promising design paradigm to overcome the energy and performance challenges in computationally demanding applications. If the case where the accuracy can be configured, the quality level versus energy efficiency or delay also may be traded-off. For this technique to be used, one needs to make sure a satisfactory user experience. This requires employing error predictors to detect unacceptable approximation errors. In this work, we propose a scheduling-aware feature selection method which leverages the intermediate results of the hardware accelerator to improve the prediction accuracy. Additionally, it configures the error predictors according to the energy consumption and latency of the system. The approach enjoys the flexibility of the prediction time for a higher accuracy. The results on various benchmarks demonstrate significant improvements in the prediction accuracy compared to the prior works which used only the accelerator inputs for the prediction.