 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2P-MANN: Adaptive Attention Inference Hops Pruned Memory-Augmented Neural Networks
Paper and Code
Jan 24, 2021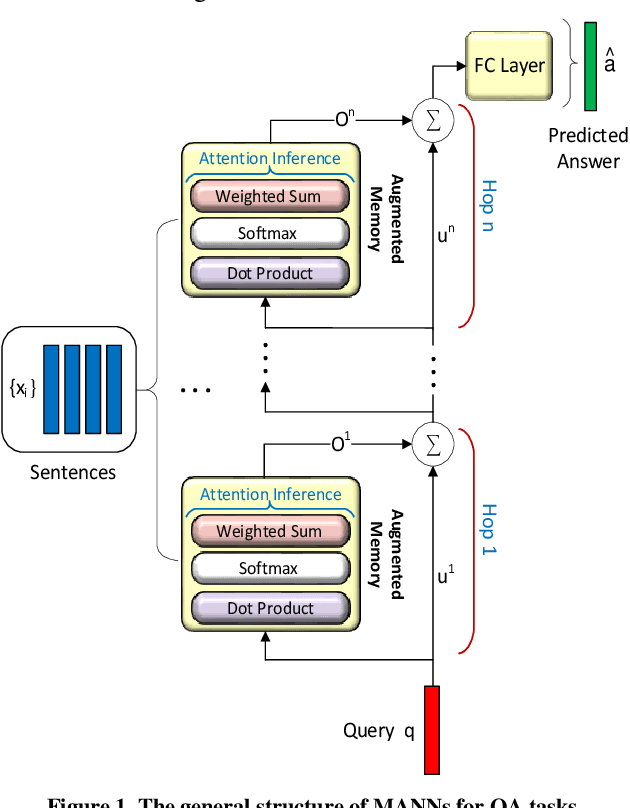
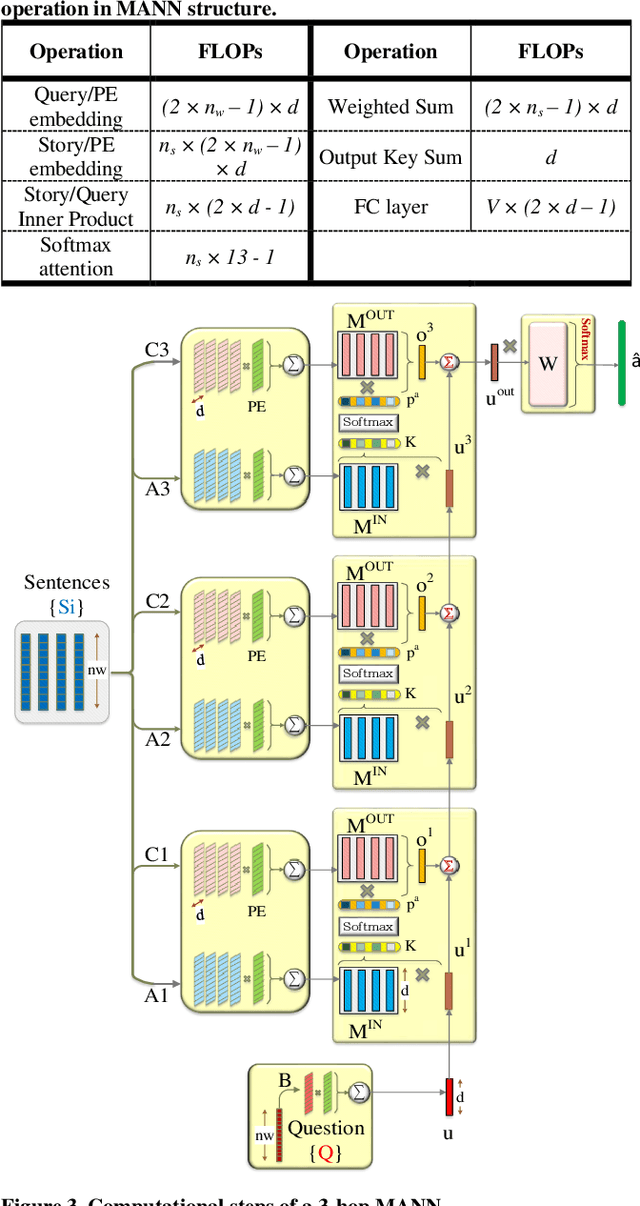
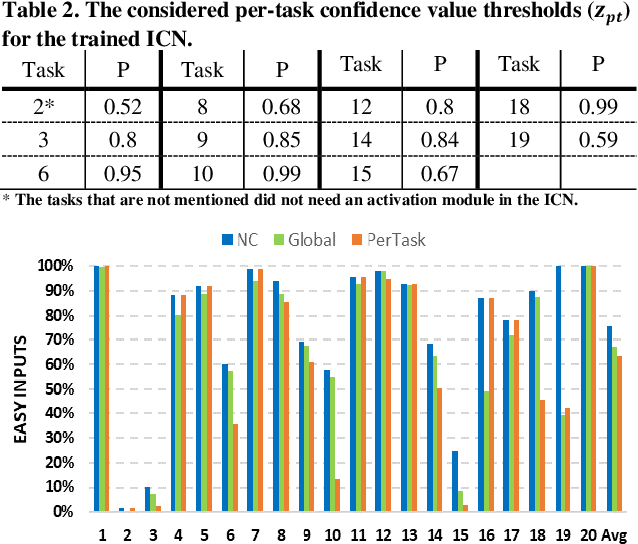

In this work, to limit the number of required attention inference hops in memory-augmented neural networks, we propose an online adaptive approach called A2P-MANN. By exploiting a small neural network classifier, an adequate number of attention inference hops for the input query is determined. The technique results in elimination of a large number of unnecessary computations in extracting the correct answer. In addition, to further lower computations in A2P-MANN, we suggest pruning weights of the final FC (fully-connected) layers. To this end, two pruning approaches, one with negligible accuracy loss and the other with controllable loss on the final accuracy, are developed. The efficacy of the technique is assessed by using the twenty question-answering (QA) tasks of bAbI dataset. The analytical assessment reveals, on average, more than 42% fewer computations compared to the baseline MANN at the cost of less than 1% accuracy loss. In addition, when used along with the previously published zero-skipping technique, a computation count reduction of up to 68% is achieved. Finally, when the proposed approach (without zero-skipping) is implemented on the CPU and GPU platforms, up to 43% runtime reduction is achieved.