 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARCO: Hardware-Aware Neural Architecture Search for Edge Devices with Multi-Agent Reinforcement Learning and Conformal Prediction Filtering
Jun 16, 2025This paper introduces MARCO (Multi-Agent Reinforcement learning with Conformal Optimization), a novel hardware-aware framework for efficient neural architecture search (NAS) targeting resource-constrained edge devices. By significantly reducing search time and maintaining accuracy under strict hardware constraints, MARCO bridges the gap between automated DNN design and CAD for edge AI deployment. MARCO's core technical contribution lies in its unique combination of multi-agent reinforcement learning (MARL) with Conformal Prediction (CP) to accelerate the hardware/software co-design process for deploying deep neural networks. Unlike conventional once-for-all (OFA) supernet approaches that require extensive pretraining, MARCO decomposes the NAS task into a hardware configuration agent (HCA) and a Quantization Agent (QA). The HCA optimizes high-level design parameters, while the QA determines per-layer bit-widths under strict memory and latency budgets using a shared reward signal within a centralized-critic, decentralized-execution (CTDE) paradigm. A key innovation is the integration of a calibrated CP surrogate model that provides statistical guarantees (with a user-defined miscoverage rate) to prune unpromising candidate architectures before incurring the high costs of partial training or hardware simulation. This early filtering drastically reduces the search space while ensuring that high-quality designs are retained with a high probability. Extensive experiments on MNIST, CIFAR-10, and CIFAR-100 demonstrate that MARCO achieves a 3-4x reduction in total search time compared to an OFA baseline while maintaining near-baseline accuracy (within 0.3%). Furthermore, MARCO also reduces inference latency. Validation on a MAX78000 evaluation board confirms that simulator trends hold in practice, with simulator estimates deviating from measured values by less than 5%.
FAIR-SIGHT: Fairness Assurance in Image Recognition via Simultaneous Conformal Thresholding and Dynamic Output Repair
Apr 10, 2025



We introduce FAIR-SIGHT, an innovative post-hoc framework designed to ensure fairness in computer vision systems by combining conformal prediction with a dynamic output repair mechanism. Our approach calculates a fairness-aware non-conformity score that simultaneously assesses prediction errors and fairness violations. Using conformal prediction, we establish an adaptive threshold that provides rigorous finite-sample, distribution-free guarantees. When the non-conformity score for a new image exceeds the calibrated threshold, FAIR-SIGHT implements targeted corrective adjustments, such as logit shifts for classification and confidence recalibration for detection, to reduce both group and individual fairness disparities, all without the need for retraining or having access to internal model parameters. Comprehensive theoretical analysis validates our method's error control and convergence properties. At the same time, extensive empirical evaluations on benchmark datasets show that FAIR-SIGHT significantly reduces fairness disparities while preserving high predictive performance.
RocketPPA: Ultra-Fast LLM-Based PPA Estimator at Code-Level Abstraction
Mar 27, 2025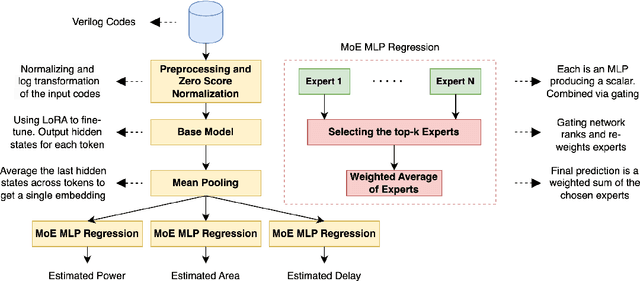
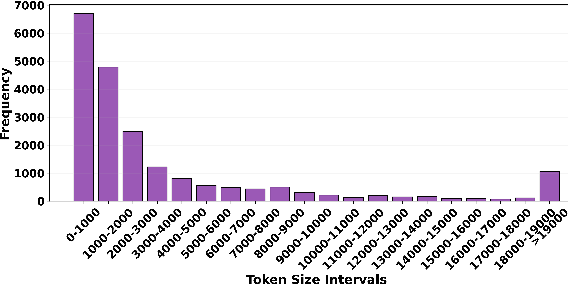
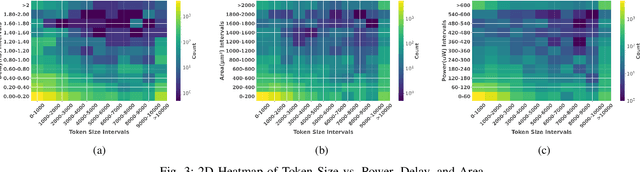
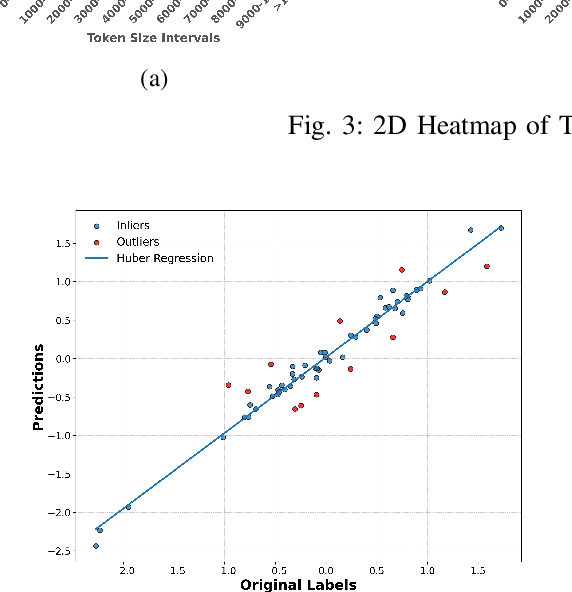
Large language models have recently transformed hardware design, yet bridging the gap between code synthesis and PPA (power, performance, and area) estimation remains a challenge. In this work, we introduce a novel framework that leverages a 21k dataset of thoroughly cleaned and synthesizable Verilog modules, each annotated with detailed power, delay, and area metrics. By employing chain-of-thought techniques, we automatically debug and curate this dataset to ensure high fidelity in downstream applications. We then fine-tune CodeLlama using LoRA-based parameter-efficient methods, framing the task as a regression problem to accurately predict PPA metrics from Verilog code. Furthermore, we augment our approach with a mixture-of-experts architecture-integrating both LoRA and an additional MLP expert layer-to further refine predictions. Experimental results demonstrate significant improvements: power estimation accuracy is enhanced by 5.9% at a 20% error threshold and by 7.2% at a 10% threshold, delay estimation improves by 5.1% and 3.9%, and area estimation sees gains of 4% and 7.9% for the 20% and 10% thresholds, respectively. Notably, the incorporation of the mixture-of-experts module contributes an additional 3--4% improvement across these tasks. Our results establish a new benchmark for PPA-aware Verilog generation, highlighting the effectiveness of our integrated dataset and modeling strategies for next-generation EDA workflows.
FACTER: Fairness-Aware Conformal Thresholding and Prompt Engineering for Enabling Fair LLM-Based Recommender Systems
Feb 05, 2025



We propose FACTER, a fairness-aware framework for LLM-based recommendation systems that integrates conformal prediction with dynamic prompt engineering. By introducing an adaptive semantic variance threshold and a violation-triggered mechanism, FACTER automatically tightens fairness constraints whenever biased patterns emerge. We further develop an adversarial prompt generator that leverages historical violations to reduce repeated demographic biases without retraining the LLM. Empirical results on MovieLens and Amazon show that FACTER substantially reduces fairness violations (up to 95.5%) while maintaining strong recommendation accuracy, revealing semantic variance as a potent proxy of bias.
Efficient Noise Mitigation for Enhancing Inference Accuracy in DNNs on Mixed-Signal Accelerators
Sep 27, 2024In this paper, we propose a framework to enhance the robustness of the neural models by mitigating the effects of process-induced and aging-related variations of analog computing components on the accuracy of the analog neural networks. We model these variations as the noise affecting the precision of the activations and introduce a denoising block inserted between selected layers of a pre-trained model. We demonstrate that training the denoising block significantly increases the model's robustness against various noise levels. To minimize the overhead associated with adding these blocks, we present an exploration algorithm to identify optimal insertion points for the denoising blocks. Additionally, we propose a specialized architecture to efficiently execute the denoising blocks, which can be integrated into mixed-signal accelerators. We evaluate the effectiveness of our approach using Deep Neural Network (DNN) models trained on the ImageNet and CIFAR-10 datasets. The results show that on average, by accepting 2.03% parameter count overhead, the accuracy drop due to the variations reduces from 31.7% to 1.15%.
Enhancing Layout Hotspot Detection Efficiency with YOLOv8 and PCA-Guided Augmentation
Jul 19, 2024



In this paper, we present a YOLO-based framework for layout hotspot detection, aiming to enhance the efficiency and performance of the design rule checking (DRC) process. Our approach leverages the YOLOv8 vision model to detect multiple hotspots within each layout image, even when dealing with large layout image sizes. Additionally, to enhance pattern-matching effectiveness, we introduce a novel approach to augment the layout image using information extracted through Principal Component Analysis (PCA). The core of our proposed method is an algorithm that utilizes PCA to extract valuable auxiliary information from the layout image. This extracted information is then incorporated into the layout image as an additional color channel. This augmentation significantly improves the accuracy of multi-hotspot detection while reducing the false alarm rate of the object detection algorithm. We evaluate the effectiveness of our framework using four datasets generated from layouts found in the ICCAD-2019 benchmark dataset. The results demonstrate that our framework achieves a precision (recall) of approximately 83% (86%) while maintaining a false alarm rate of less than 7.4\%. Also, the studies show that the proposed augmentation approach could improve the detection ability of never-seen-before (NSB) hotspots by about 10%.
ARCO:Adaptive Multi-Agent Reinforcement Learning-Based Hardware/Software Co-Optimization Compiler for Improved Performance in DNN Accelerator Design
Jul 11, 2024This paper presents ARCO, an adaptive Multi-Agent Reinforcement Learning (MARL)-based co-optimizing compilation framework designed to enhance the efficiency of mapping machine learning (ML) models - such as Deep Neural Networks (DNNs) - onto diverse hardware platforms. The framework incorporates three specialized actor-critic agents within MARL, each dedicated to a distinct aspect of compilation/optimization at an abstract level: one agent focuses on hardware, while two agents focus on software optimizations. This integration results in a collaborative hardware/software co-optimization strategy that improves the precision and speed of DNN deployments. Concentrating on high-confidence configurations simplifies the search space and delivers superior performance compared to current optimization methods. The ARCO framework surpasses existing leading frameworks, achieving a throughput increase of up to 37.95% while reducing the optimization time by up to 42.2% across various DNNs.
Scalable Superconductor Neuron with Ternary Synaptic Connections for Ultra-Fast SNN Hardware
Feb 27, 2024



A novel high-fan-in differential superconductor neuron structure designed for ultra-high-performance Spiking Neural Network (SNN) accelerators is presented. Utilizing a high-fan-in neuron structure allows us to design SNN accelerators with more synaptic connections, enhancing the overall network capabilities. The proposed neuron design is based on superconductor electronics fabric, incorporating multiple superconducting loops, each with two Josephson Junctions. This arrangement enables each input data branch to have positive and negative inductive coupling, supporting excitatory and inhibitory synaptic data. Compatibility with synaptic devices and thresholding operation is achieved using a single flux quantum (SFQ) pulse-based logic style. The neuron design, along with ternary synaptic connections, forms the foundation for a superconductor-based SNN inference. To demonstrate the capabilities of our design, we train the SNN using snnTorch, augmenting the PyTorch framework. After pruning, the demonstrated SNN inference achieves an impressive 96.1% accuracy on MNIST images. Notably, the network exhibits a remarkable throughput of 8.92 GHz while consuming only 1.5 nJ per inference, including the energy consumption associated with cooling to 4K. These results underscore the potential of superconductor electronics in developing high-performance and ultra-energy-efficient neural network accelerator architectures.
Low-Precision Mixed-Computation Models for Inference on Edge
Dec 03, 2023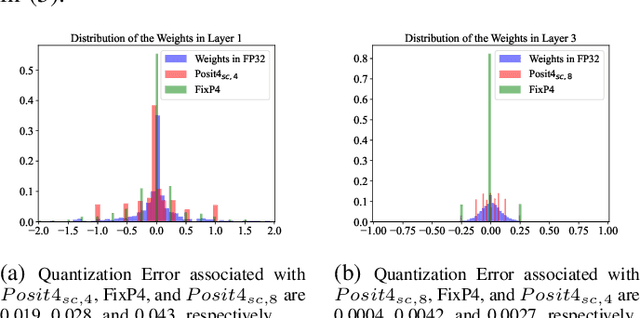
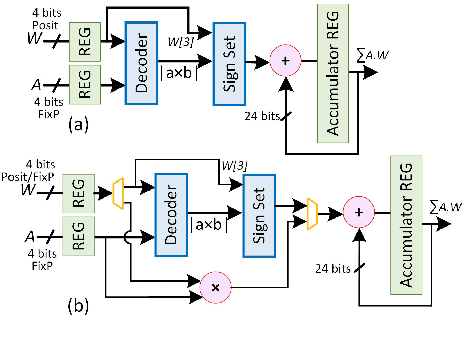
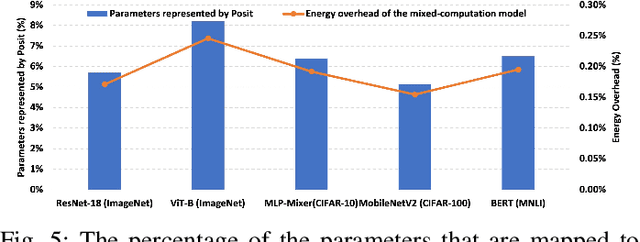
This paper presents a mixed-computation neural network processing approach for edge applications that incorporates low-precision (low-width) Posit and low-precision fixed point (FixP) number systems. This mixed-computation approach employs 4-bit Posit (Posit4), which has higher precision around zero, for representing weights with high sensitivity, while it uses 4-bit FixP (FixP4) for representing other weights. A heuristic for analyzing the importance and the quantization error of the weights is presented to assign the proper number system to different weights. Additionally, a gradient approximation for Posit representation is introduced to improve the quality of weight updates in the backpropagation process. Due to the high energy consumption of the fully Posit-based computations, neural network operations are carried out in FixP or Posit/FixP. An efficient hardware implementation of a MAC operation with a first Posit operand and FixP for a second operand and accumulator is presented. The efficacy of the proposed low-precision mixed-computation approach is extensively assessed on vision and language models. The results show that, on average, the accuracy of the mixed-computation is about 1.5% higher than that of FixP with a cost of 0.19% energy overhead.
A2P-MANN: Adaptive Attention Inference Hops Pruned Memory-Augmented Neural Networks
Jan 24, 2021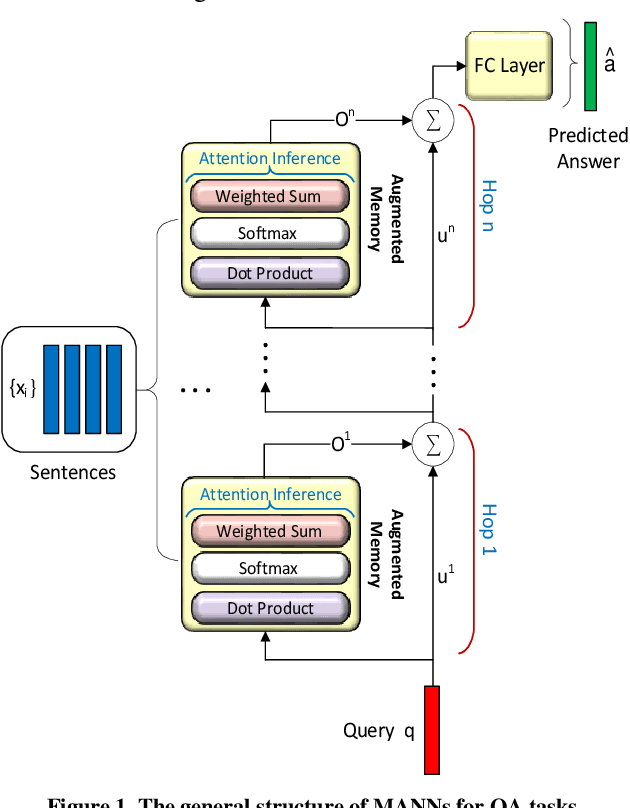
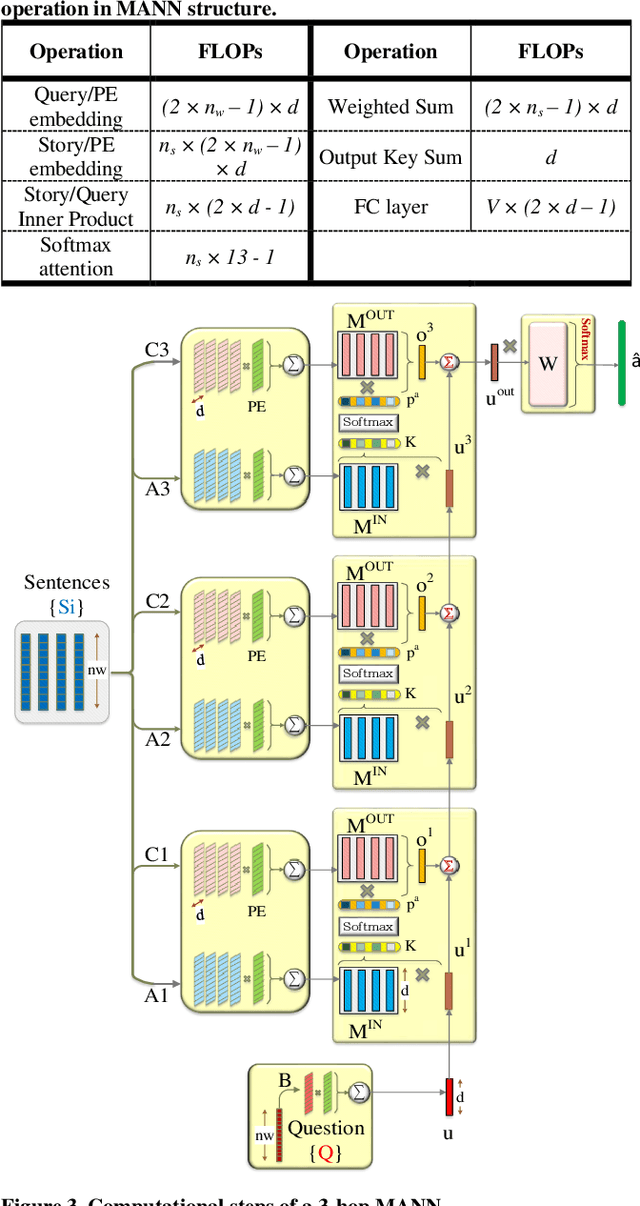
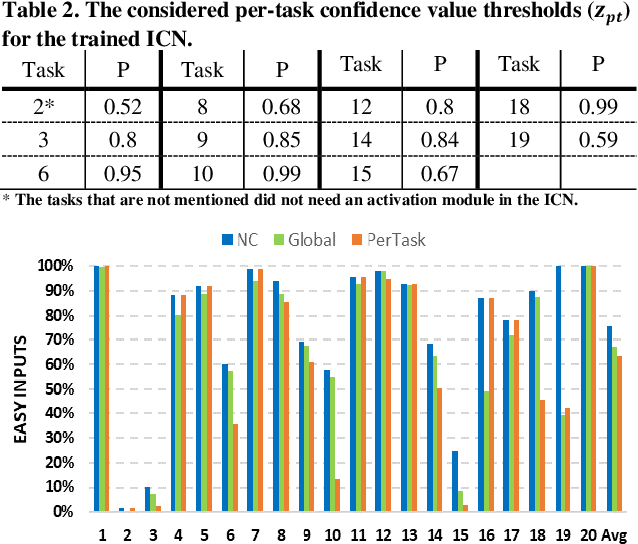

In this work, to limit the number of required attention inference hops in memory-augmented neural networks, we propose an online adaptive approach called A2P-MANN. By exploiting a small neural network classifier, an adequate number of attention inference hops for the input query is determined. The technique results in elimination of a large number of unnecessary computations in extracting the correct answer. In addition, to further lower computations in A2P-MANN, we suggest pruning weights of the final FC (fully-connected) layers. To this end, two pruning approaches, one with negligible accuracy loss and the other with controllable loss on the final accuracy, are developed. The efficacy of the technique is assessed by using the twenty question-answering (QA) tasks of bAbI dataset. The analytical assessment reveals, on average, more than 42% fewer computations compared to the baseline MANN at the cost of less than 1% accuracy loss. In addition, when used along with the previously published zero-skipping technique, a computation count reduction of up to 68% is achieved. Finally, when the proposed approach (without zero-skipping) is implemented on the CPU and GPU platforms, up to 43% runtime reduction is achieved.