 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopula-Based Analysis of Fluid Antenna-Assisted Over-the-Air Computation
May 05, 2026This letter studies an uplink over-the-air computation (AirComp) framework in which multiple user equipments are equipped with fluid-antenna (FA) arrays and operate over spatially correlated fading channels. By explicitly modeling channel dependence using the Gumbel copula, closed-form analytical expressions are derived for the cumulative distribution function (CDF) of the mean-squared error (MSE) of the aggregated function. The proposed analysis provides a quantitative performance characterization of AirComp under spatial correlation and provides analytical insights into the role of FA-assisted transmission in correlated wireless environments. Numerical results validate the derived expressions and show that FA deployment can substantially reduce the MSE compared with conventional fixed-antenna systems, although the achievable gain decreases as spatial correlation becomes stronger.
AI-Empowered Resource Allocation for Wirelessly Powered Pinching-Antenna Systems
Apr 13, 2026This paper considers a multi-user system, where the users first harvest energy from the base station and then use the harvested energy to transmit information via non-orthogonal multiple access (NOMA). A pinching antenna array is adopted to assist the energy transfer and information transmission, owing to its ability to adapt to dynamic propagation conditions. To enhance the system's energy efficiency (EE), we formulate a joint optimization problem involving antenna positioning, transmit power control, and time-switching ratio selection. The problem is non-convex due to the coupled variables, nonlinear energy-harvesting characteristics, and uncertainties in user locations and battery states. To effectively solve this problem, a deep reinforcement learning-based algorithm is proposed to autonomously learn near-optimal resource allocation policies in dynamic environments. Simulation results demonstrate that the proposed PA-assisted scheme achieves significant gains in EE compared with conventional fixed-antenna schemes.
Fluid Antenna Systems under Channel Uncertainty and Hardware Impairments: Trends, Challenges, and Future Research Directions
Jan 30, 2026Fluid antenna systems (FAS) have recently emerged as a promising paradigm for achieving spatially reconfigurable, compact, and energy-efficient wireless communications in beyond fifth-generation (B5G) and sixth-generation (6G) networks. By dynamically repositioning a liquid-based radiating element within a confined physical structure, FAS can exploit spatial diversity without relying on multiple fixed antenna elements. This spatial mobility provides a new degree of freedom for mitigating channel fading and interference, while maintaining low hardware complexity and power consumption. However, the performance of FAS in realistic deployments is strongly affected by channel uncertainty, hardware nonidealities, and mechanical constraints, all of which can substantially deviate from idealized analytical assumptions. This paper presents a comprehensive survey of the operation and design of FAS under such practical considerations. Key aspects include the characterization of spatio-temporal channel uncertainty, analysis of hardware and mechanical impairments such as RF nonlinearity, port coupling, and fluid response delay, as well as the exploration of robust design and learning-based control strategies to enhance system reliability. Finally, open research directions are identified, aiming to guide future developments toward robust, adaptive, and cross-domain FAS design for next-generation wireless networks.
AnaFlow: Agentic LLM-based Workflow for Reasoning-Driven Explainable and Sample-Efficient Analog Circuit Sizing
Nov 05, 2025Analog/mixed-signal circuits are key for interfacing electronics with the physical world. Their design, however, remains a largely handcrafted process, resulting in long and error-prone design cycles. While the recent rise of AI-based reinforcement learning and generative AI has created new techniques to automate this task, the need for many time-consuming simulations is a critical bottleneck hindering the overall efficiency. Furthermore, the lack of explainability of the resulting design solutions hampers widespread adoption of the tools. To address these issues, a novel agentic AI framework for sample-efficient and explainable analog circuit sizing is presented. It employs a multi-agent workflow where specialized Large Language Model (LLM)-based agents collaborate to interpret the circuit topology, to understand the design goals, and to iteratively refine the circuit's design parameters towards the target goals with human-interpretable reasoning. The adaptive simulation strategy creates an intelligent control that yields a high sample efficiency. The AnaFlow framework is demonstrated for two circuits of varying complexity and is able to complete the sizing task fully automatically, differently from pure Bayesian optimization and reinforcement learning approaches. The system learns from its optimization history to avoid past mistakes and to accelerate convergence. The inherent explainability makes this a powerful tool for analog design space exploration and a new paradigm in analog EDA, where AI agents serve as transparent design assistants.
Robust Resource Allocation for Over-the-Air Computation Networks with Fluid Antenna Array
Apr 22, 2025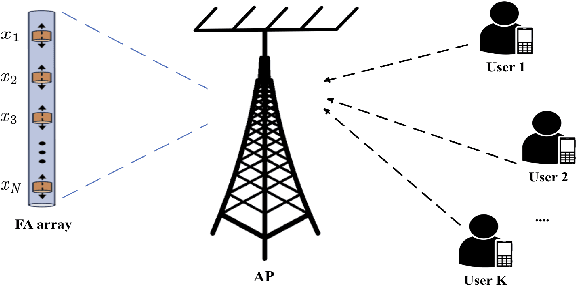
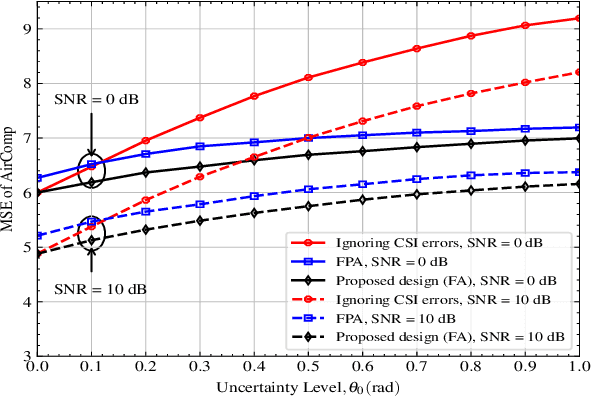
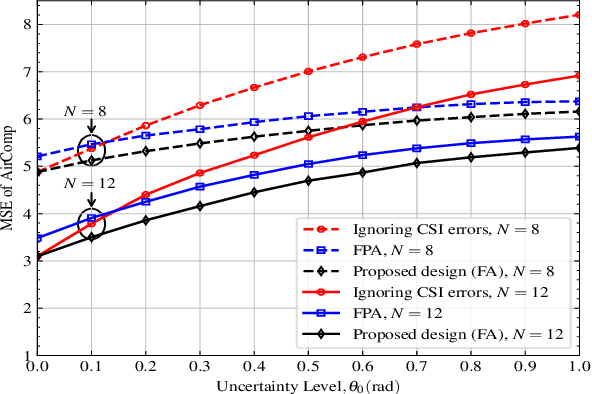
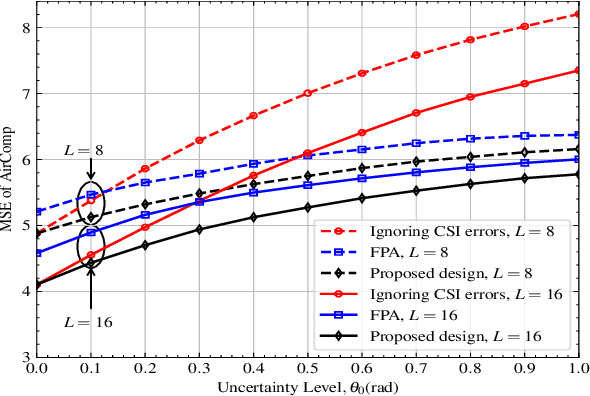
Fluid antenna (FA) array is envisioned as a promising technology for next-generation communication systems, owing to its ability to dynamically control the antenna locations. In this paper, we apply FA array to boost the performance of over-the-air computation networks. Given that channel uncertainty will impact negatively not only the beamforming design but also the antenna location optimization, robust resource allocation is performed to minimize the mean squared error of transmitted messages. Block coordinate descent is adopted to decompose the formulated non-convex problem into three subproblems, which are iteratively solved until convergence. Numerical results show the benefits of FA array and the necessity of robust resource allocation under channel uncertainty.
Enhancement of Over-the-Air Federated Learning by Using AI-based Fluid Antenna System
Jul 03, 2024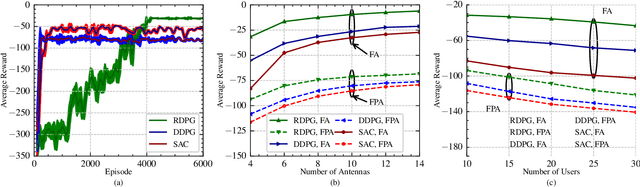
This letter investigates an over-the-air federated learning (OTA-FL) system that employs fluid antennas (FAs) at the access point (AP) to enhance learning performance by leveraging the additional degrees of freedom provided by antenna mobility. First, we analyze the convergence of the OTA-FL system and derive the optimality gap to illustrate the influence of FAs on learning performance. Then, we formulate a nonconvex optimization problem to minimize the optimality gap by jointly optimizing the positions of the FAs and the beamforming vector. To address the dynamic environment, we cast this optimization problem as a Markov decision process (MDP) and propose the recurrent deep deterministic policy gradient (RDPG) algorithm. Finally, extensive simulations show that the FA-assisted OTA-FL system outperforms systems with fixed-position antennas and that the RDPG algorithm surpasses the existing methods.
A2P-MANN: Adaptive Attention Inference Hops Pruned Memory-Augmented Neural Networks
Jan 24, 2021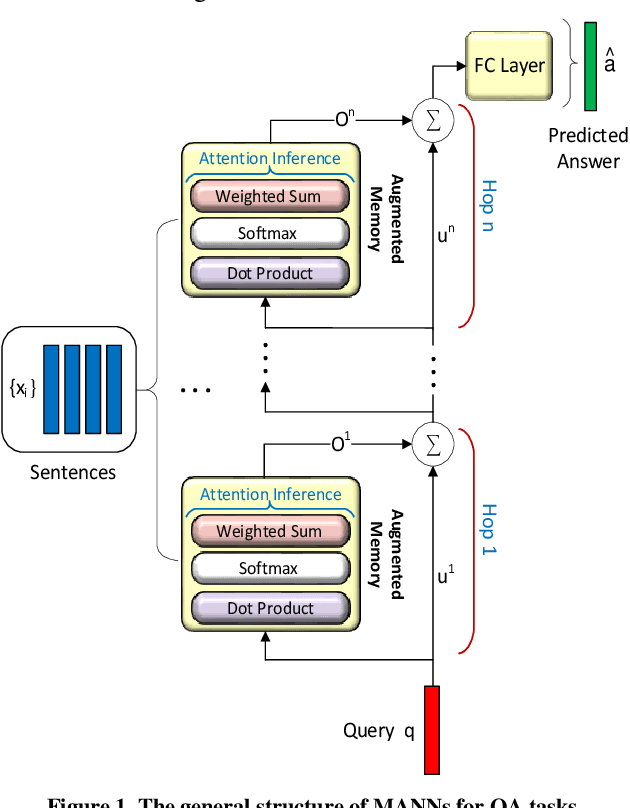
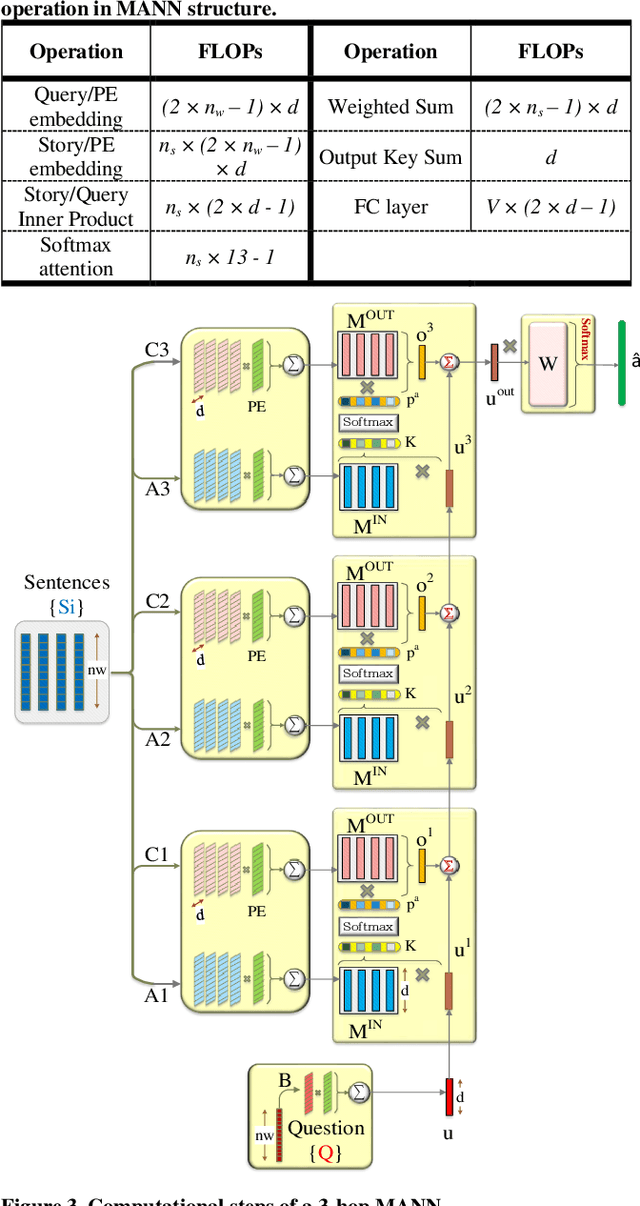
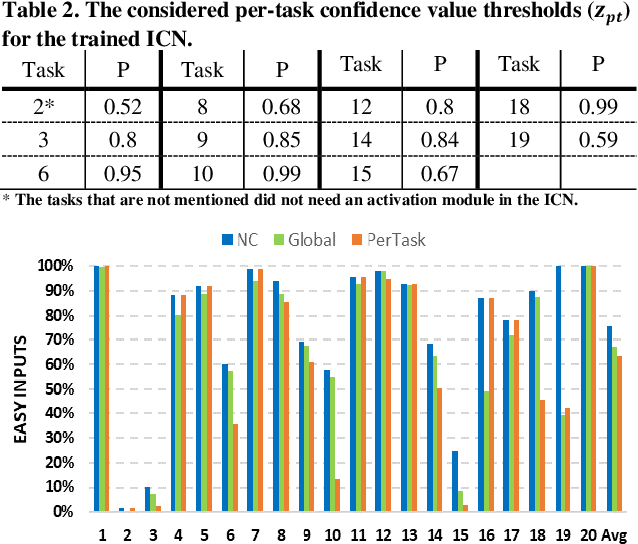

In this work, to limit the number of required attention inference hops in memory-augmented neural networks, we propose an online adaptive approach called A2P-MANN. By exploiting a small neural network classifier, an adequate number of attention inference hops for the input query is determined. The technique results in elimination of a large number of unnecessary computations in extracting the correct answer. In addition, to further lower computations in A2P-MANN, we suggest pruning weights of the final FC (fully-connected) layers. To this end, two pruning approaches, one with negligible accuracy loss and the other with controllable loss on the final accuracy, are developed. The efficacy of the technique is assessed by using the twenty question-answering (QA) tasks of bAbI dataset. The analytical assessment reveals, on average, more than 42% fewer computations compared to the baseline MANN at the cost of less than 1% accuracy loss. In addition, when used along with the previously published zero-skipping technique, a computation count reduction of up to 68% is achieved. Finally, when the proposed approach (without zero-skipping) is implemented on the CPU and GPU platforms, up to 43% runtime reduction is achieved.