 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancement of Over-the-Air Federated Learning by Using AI-based Fluid Antenna System
Paper and Code
Jul 03, 2024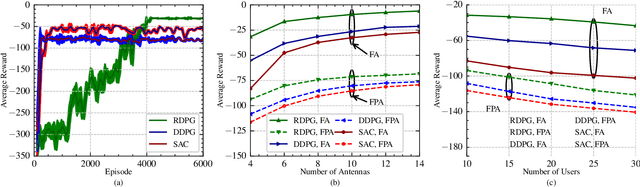
This letter investigates an over-the-air federated learning (OTA-FL) system that employs fluid antennas (FAs) at the access point (AP) to enhance learning performance by leveraging the additional degrees of freedom provided by antenna mobility. First, we analyze the convergence of the OTA-FL system and derive the optimality gap to illustrate the influence of FAs on learning performance. Then, we formulate a nonconvex optimization problem to minimize the optimality gap by jointly optimizing the positions of the FAs and the beamforming vector. To address the dynamic environment, we cast this optimization problem as a Markov decision process (MDP) and propose the recurrent deep deterministic policy gradient (RDPG) algorithm. Finally, extensive simulations show that the FA-assisted OTA-FL system outperforms systems with fixed-position antennas and that the RDPG algorithm surpasses the existing methods.