 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimingLLM: A Two-Stage Retrieval-Augmented Framework for Pre-Synthesis Timing Prediction from Verilog
Apr 26, 2026Early, tool-free prediction of post-synthesis timing remains a key obstacle to rapid RTL iteration. We introduce TimingLLM, a two-stage retrieval-augmented LLM pipeline that estimates worst negative slack (WNS) and total negative slack (TNS) directly from Verilog. Stage 1 is a fine-tuned LLM that acts as a compact post-synthesis timing oracle, producing path-level arrivals/required times that are summarized into lightweight structural-timing cues (e.g., bag-of-gates counts, critical-path depth, gate-type patterns). Stage 2 is an LLM-based regressor that predicts WNS/TNS and applies a learned diagonal steering vector at the last transformer block, computed from the k nearest timing-labeled modules in a disjoint retrieval bank. On VerilogEval, TimingLLM attains R_WNS = 0.91 (MAPE 12%) and R_TNS=0.97 (MAPE 16%) while running 1.3-1.6 times faster than prior methods. Training uses a new 60k-module Verilog corpus with synthesis reports, which we will release. After training once, TimingLLM can be adapted to new technology libraries and PVT corners by refitting only a small regression head on 1000 labeled modules per setting, consistently outperforming state-of-the-art baselines.
RocketPPA: Ultra-Fast LLM-Based PPA Estimator at Code-Level Abstraction
Mar 27, 2025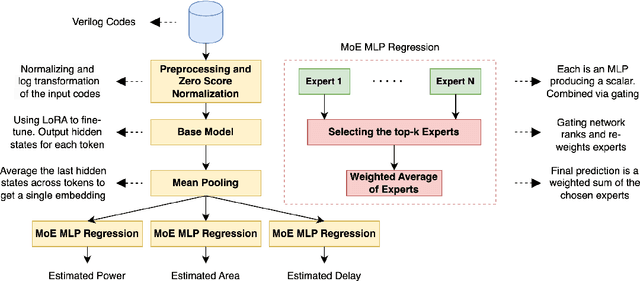
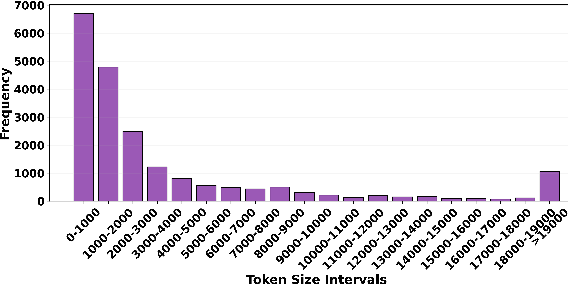
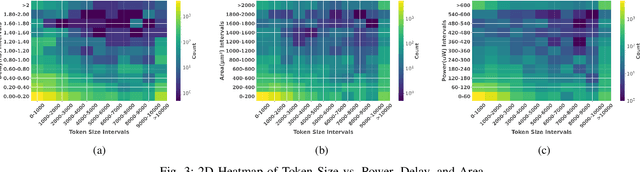
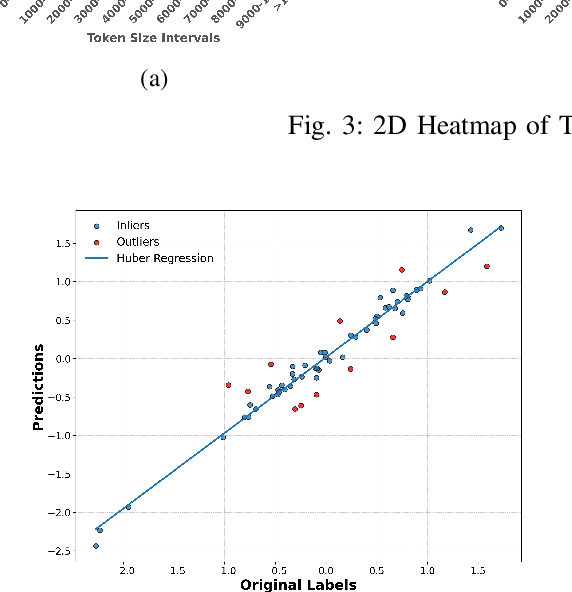
Large language models have recently transformed hardware design, yet bridging the gap between code synthesis and PPA (power, performance, and area) estimation remains a challenge. In this work, we introduce a novel framework that leverages a 21k dataset of thoroughly cleaned and synthesizable Verilog modules, each annotated with detailed power, delay, and area metrics. By employing chain-of-thought techniques, we automatically debug and curate this dataset to ensure high fidelity in downstream applications. We then fine-tune CodeLlama using LoRA-based parameter-efficient methods, framing the task as a regression problem to accurately predict PPA metrics from Verilog code. Furthermore, we augment our approach with a mixture-of-experts architecture-integrating both LoRA and an additional MLP expert layer-to further refine predictions. Experimental results demonstrate significant improvements: power estimation accuracy is enhanced by 5.9% at a 20% error threshold and by 7.2% at a 10% threshold, delay estimation improves by 5.1% and 3.9%, and area estimation sees gains of 4% and 7.9% for the 20% and 10% thresholds, respectively. Notably, the incorporation of the mixture-of-experts module contributes an additional 3--4% improvement across these tasks. Our results establish a new benchmark for PPA-aware Verilog generation, highlighting the effectiveness of our integrated dataset and modeling strategies for next-generation EDA workflows.
Enhancing Multi-Modal Video Sentiment Classification Through Semi-Supervised Clustering
Jan 11, 2025



Understanding emotions in videos is a challenging task. However, videos contain several modalities which make them a rich source of data for machine learning and deep learning tasks. In this work, we aim to improve video sentiment classification by focusing on two key aspects: the video itself, the accompanying text, and the acoustic features. To address the limitations of relying on large labeled datasets, we are developing a method that utilizes clustering-based semi-supervised pre-training to extract meaningful representations from the data. This pre-training step identifies patterns in the video and text data, allowing the model to learn underlying structures and relationships without requiring extensive labeled information at the outset. Once these patterns are established, we fine-tune the system in a supervised manner to classify the sentiment expressed in videos. We believe that this multi-modal approach, combining clustering with supervised fine-tuning, will lead to more accurate and insightful sentiment classification, especially in cases where labeled data is limited.
Machine Learning-Based Prediction of ICU Readmissions in Intracerebral Hemorrhage Patients: Insights from the MIMIC Databases
Jan 02, 2025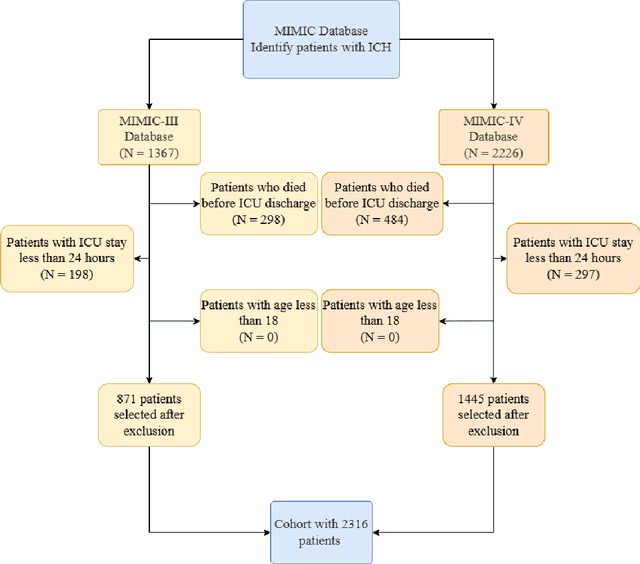
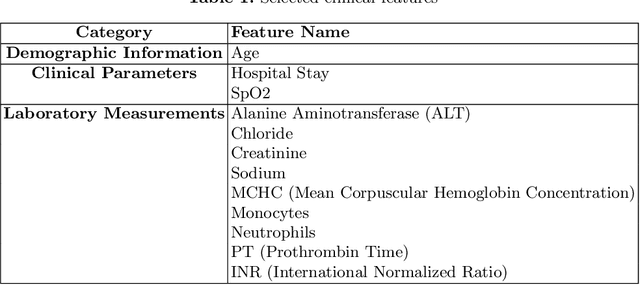
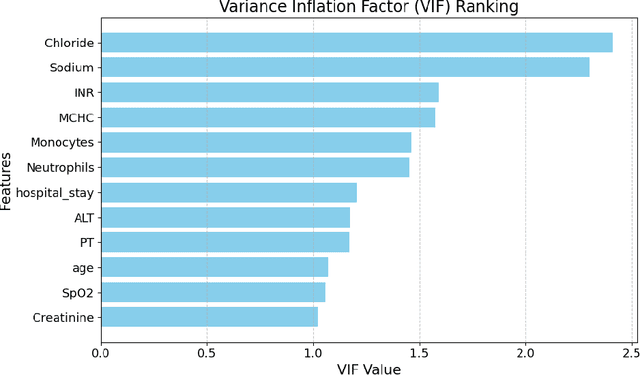
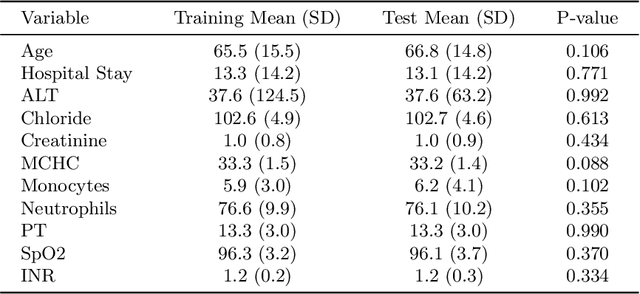
Intracerebral hemorrhage (ICH) is a life-risking condition characterized by bleeding within the brain parenchyma. ICU readmission in ICH patients is a critical outcome, reflecting both clinical severity and resource utilization. Accurate prediction of ICU readmission risk is crucial for guiding clinical decision-making and optimizing healthcare resources. This study utilized the Medical Information Mart for Intensive Care (MIMIC-III and MIMIC-IV) databases, which contain comprehensive clinical and demographic data on ICU patients. Patients with ICH were identified from both databases. Various clinical, laboratory, and demographic features were extracted for analysis based on both overview literature and experts' opinions. Preprocessing methods like imputing and sampling were applied to improve the performance of our models. Machine learning techniques, such as Artificial Neural Network (ANN), XGBoost, and Random Forest, were employed to develop predictive models for ICU readmission risk. Model performance was evaluated using metrics such as AUROC, accuracy, sensitivity, and specificity. The developed models demonstrated robust predictive accuracy for ICU readmission in ICH patients, with key predictors including demographic information, clinical parameters, and laboratory measurements. Our study provides a predictive framework for ICU readmission risk in ICH patients, which can aid in clinical decision-making and improve resource allocation in intensive care settings.
Optimizing Mortality Prediction for ICU Heart Failure Patients: Leveraging XGBoost and Advanced Machine Learning with the MIMIC-III Database
Sep 03, 2024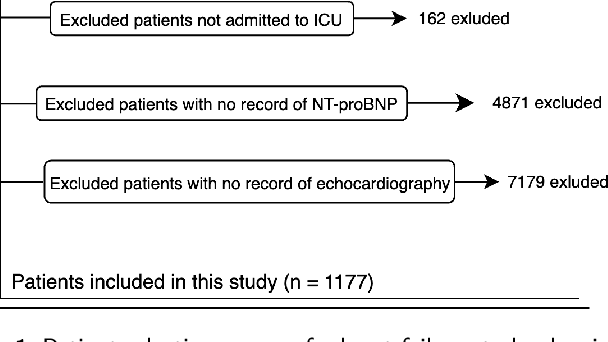
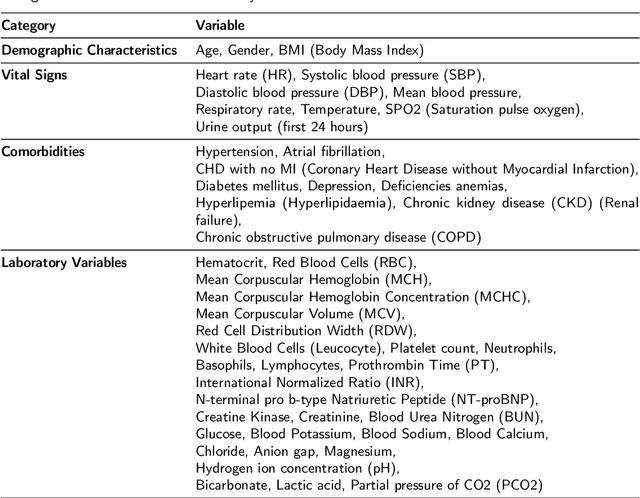
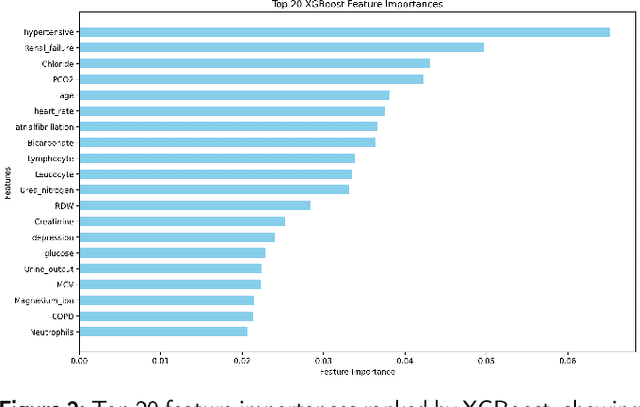
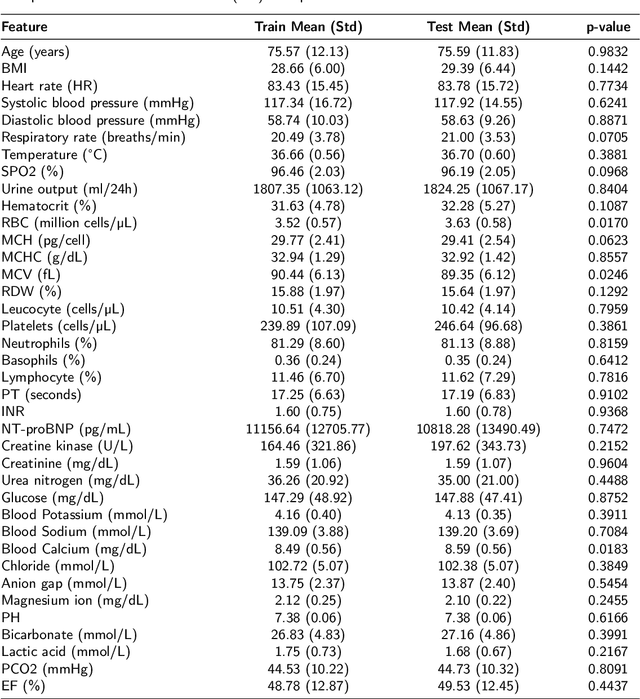
Heart failure affects millions of people worldwide, significantly reducing quality of life and leading to high mortality rates. Despite extensive research, the relationship between heart failure and mortality rates among ICU patients is not fully understood, indicating the need for more accurate prediction models. This study analyzed data from 1,177 patients over 18 years old from the MIMIC-III database, identified using ICD-9 codes. Preprocessing steps included handling missing data, removing duplicates, treating skewness, and using oversampling techniques to address data imbalances. Through rigorous feature selection using Variance Inflation Factor (VIF), expert clinical input, and ablation studies, 46 key features were identified to enhance model performance. Our analysis compared several machine learning models, including Logistic Regression, Support Vector Machine (SVM), Random Forest, LightGBM, and XGBoost. XGBoost emerged as the superior model, achieving a test AUC-ROC of 0.9228 (95\% CI 0.8748 - 0.9613), significantly outperforming our previous work (AUC-ROC of 0.8766) and the best results reported in existing literature (AUC-ROC of 0.824). The improved model's success is attributed to advanced feature selection methods, robust preprocessing techniques, and comprehensive hyperparameter optimization through Grid-Search. SHAP analysis and feature importance evaluations based on XGBoost highlighted key variables like leucocyte count and RDW, providing valuable insights into the clinical factors influencing mortality risk. This framework offers significant support for clinicians, enabling them to identify high-risk ICU heart failure patients and improve patient outcomes through timely and informed interventions.
Enhanced Prediction of Ventilator-Associated Pneumonia in Patients with Traumatic Brain Injury Using Advanced Machine Learning Techniques
Aug 02, 2024Background: Ventilator-associated pneumonia (VAP) in traumatic brain injury (TBI) patients poses a significant mortality risk and imposes a considerable financial burden on patients and healthcare systems. Timely detection and prognostication of VAP in TBI patients are crucial to improve patient outcomes and alleviate the strain on healthcare resources. Methods: We implemented six machine learning models using the MIMIC-III database. Our methodology included preprocessing steps, such as feature selection with CatBoost and expert opinion, addressing class imbalance with the Synthetic Minority Oversampling Technique (SMOTE), and rigorous model tuning through 5-fold cross-validation to optimize hyperparameters. Key models evaluated included SVM, Logistic Regression, Random Forest, XGBoost, ANN, and AdaBoost. Additionally, we conducted SHAP analysis to determine feature importance and performed an ablation study to assess feature impacts on model performance. Results: XGBoost outperformed the baseline models and the best existing literature. We used metrics, including AUC, Accuracy, Specificity, Sensitivity, F1 Score, PPV, and NPV. XGBoost demonstrated the highest performance with an AUC of 0.940 and an Accuracy of 0.875, which are 23.4% and 23.5% higher than the best results in the existing literature, with an AUC of 0.706 and an Accuracy of 0.640, respectively. This enhanced performance underscores the models' effectiveness in clinical settings. Conclusions: This study enhances the predictive modeling of VAP in TBI patients, improving early detection and intervention potential. Refined feature selection and advanced ensemble techniques significantly boosted model accuracy and reliability, offering promising directions for future clinical applications and medical diagnostics research.
Enhanced Mortality Prediction in ICU Stroke Patients via Deep Learning
Jul 19, 2024



Background: Stroke is second-leading cause of disability and death among adults. Approximately 17 million people suffer from a stroke annually, with about 85% being ischemic strokes. Predicting mortality of ischemic stroke patients in intensive care unit (ICU) is crucial for optimizing treatment strategies, allocating resources, and improving survival rates. Methods: We acquired data on ICU ischemic stroke patients from MIMIC-IV database, including diagnoses, vital signs, laboratory tests, medications, procedures, treatments, and clinical notes. Stroke patients were randomly divided into training (70%, n=2441), test (15%, n=523), and validation (15%, n=523) sets. To address data imbalances, we applied Synthetic Minority Over-sampling Technique (SMOTE). We selected 30 features for model development, significantly reducing feature number from 1095 used in the best study. We developed a deep learning model to assess mortality risk and implemented several baseline machine learning models for comparison. Results: XGB-DL model, combining XGBoost for feature selection and deep learning, effectively minimized false positives. Model AUROC improved from 0.865 (95% CI: 0.821 - 0.905) on first day to 0.903 (95% CI: 0.868 - 0.936) by fourth day using data from 3,646 ICU mortality patients in the MIMIC-IV database with 0.945 AUROC (95% CI: 0.944 - 0.947) during training. Although other ML models also performed well in terms of AUROC, we chose Deep Learning for its higher specificity. Conclusions: Through enhanced feature selection and data cleaning, proposed model demonstrates a 13% AUROC improvement compared to existing models while reducing feature number from 1095 in previous studies to 30.
Effect of a Process Mining based Pre-processing Step in Prediction of the Critical Health Outcomes
Jul 03, 2024



Predicting critical health outcomes such as patient mortality and hospital readmission is essential for improving survivability. However, healthcare datasets have many concurrences that create complexities, leading to poor predictions. Consequently, pre-processing the data is crucial to improve its quality. In this study, we use an existing pre-processing algorithm, concatenation, to improve data quality by decreasing the complexity of datasets. Sixteen healthcare datasets were extracted from two databases - MIMIC III and University of Illinois Hospital - converted to the event logs, they were then fed into the concatenation algorithm. The pre-processed event logs were then fed to the Split Miner (SM) algorithm to produce a process model. Process model quality was evaluated before and after concatenation using the following metrics: fitness, precision, F-Measure, and complexity. The pre-processed event logs were also used as inputs to the Decay Replay Mining (DREAM) algorithm to predict critical outcomes. We compared predicted results before and after applying the concatenation algorithm using Area Under the Curve (AUC) and Confidence Intervals (CI). Results indicated that the concatenation algorithm improved the quality of the process models and predictions of the critical health outcomes.