 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWTEFNet: Real-Time Low-Light Object Detection for Advanced Driver-Assistance Systems
May 29, 2025Object detection is a cornerstone of environmental perception in advanced driver assistance systems(ADAS). However, most existing methods rely on RGB cameras, which suffer from significant performance degradation under low-light conditions due to poor image quality. To address this challenge, we proposes WTEFNet, a real-time object detection framework specifically designed for low-light scenarios, with strong adaptability to mainstream detectors. WTEFNet comprises three core modules: a Low-Light Enhancement (LLE) module, a Wavelet-based Feature Extraction (WFE) module, and an Adaptive Fusion Detection (AFFD) module. The LLE enhances dark regions while suppressing overexposed areas; the WFE applies multi-level discrete wavelet transforms to isolate high- and low-frequency components, enabling effective denoising and structural feature retention; the AFFD fuses semantic and illumination features for robust detection. To support training and evaluation, we introduce GSN, a manually annotated dataset covering both clear and rainy night-time scenes. Extensive experiments on BDD100K, SHIFT, nuScenes, and GSN demonstrate that WTEFNet achieves state-of-the-art accuracy under low-light conditions. Furthermore, deployment on a embedded platform (NVIDIA Jetson AGX Orin) confirms the framework's suitability for real-time ADAS applications.
Context-Aware Prompt Tuning for Vision-Language Model with Dual-Alignment
Sep 08, 2023
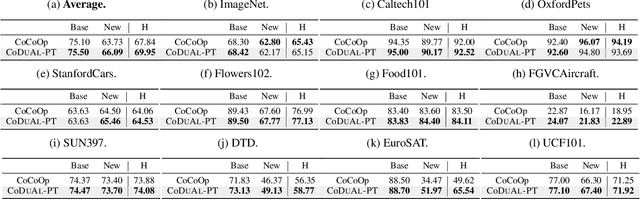
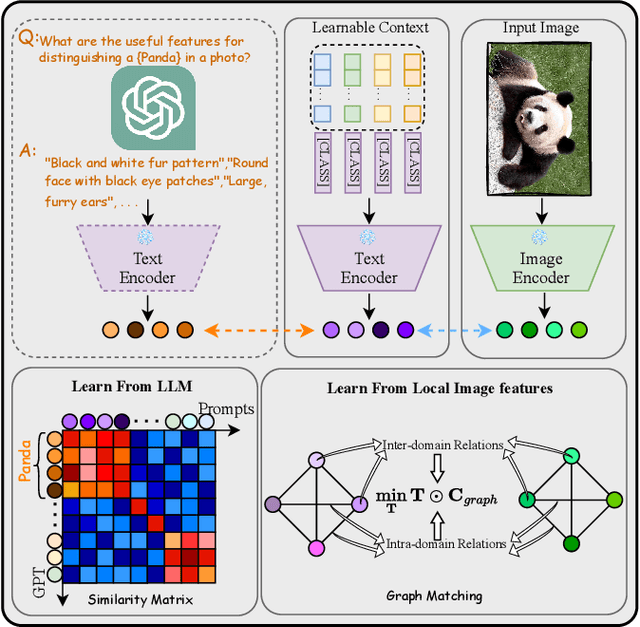
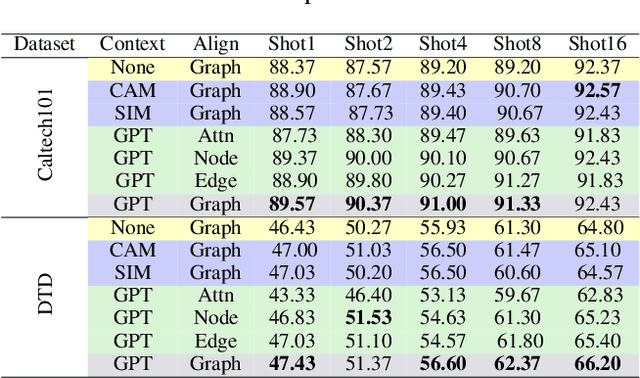
Large-scale vision-language models (VLMs), e.g., CLIP, learn broad visual concepts from tedious training data, showing superb generalization ability. Amount of prompt learning methods have been proposed to efficiently adapt the VLMs to downstream tasks with only a few training samples. We introduce a novel method to improve the prompt learning of vision-language models by incorporating pre-trained large language models (LLMs), called Dual-Aligned Prompt Tuning (DuAl-PT). Learnable prompts, like CoOp, implicitly model the context through end-to-end training, which are difficult to control and interpret. While explicit context descriptions generated by LLMs, like GPT-3, can be directly used for zero-shot classification, such prompts are overly relying on LLMs and still underexplored in few-shot domains. With DuAl-PT, we propose to learn more context-aware prompts, benefiting from both explicit and implicit context modeling. To achieve this, we introduce a pre-trained LLM to generate context descriptions, and we encourage the prompts to learn from the LLM's knowledge by alignment, as well as the alignment between prompts and local image features. Empirically, DuAl-PT achieves superior performance on 11 downstream datasets on few-shot recognition and base-to-new generalization. Hopefully, DuAl-PT can serve as a strong baseline. Code will be available.
CIEM: Contrastive Instruction Evaluation Method for Better Instruction Tuning
Sep 05, 2023



Nowadays, the research on Large Vision-Language Models (LVLMs) has been significantly promoted thanks to the success of Large Language Models (LLM). Nevertheless, these Vision-Language Models (VLMs) are suffering from the drawback of hallucination -- due to insufficient understanding of vision and language modalities, VLMs may generate incorrect perception information when doing downstream applications, for example, captioning a non-existent entity. To address the hallucination phenomenon, on the one hand, we introduce a Contrastive Instruction Evaluation Method (CIEM), which is an automatic pipeline that leverages an annotated image-text dataset coupled with an LLM to generate factual/contrastive question-answer pairs for the evaluation of the hallucination of VLMs. On the other hand, based on CIEM, we further propose a new instruction tuning method called CIT (the abbreviation of Contrastive Instruction Tuning) to alleviate the hallucination of VLMs by automatically producing high-quality factual/contrastive question-answer pairs and corresponding justifications for model tuning. Through extensive experiments on CIEM and CIT, we pinpoint the hallucination issues commonly present in existing VLMs, the disability of the current instruction-tuning dataset to handle the hallucination phenomenon and the superiority of CIT-tuned VLMs over both CIEM and public datasets.
Breast Lesion Diagnosis Using Static Images and Dynamic Video
Aug 19, 2023


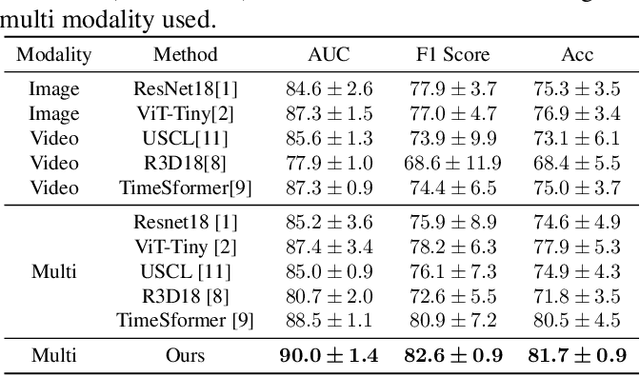
Deep learning based Computer Aided Diagnosis (CAD) systems have been developed to treat breast ultrasound. Most of them focus on a single ultrasound imaging modality, either using representative static images or the dynamic video of a real-time scan. In fact, these two image modalities are complementary for lesion diagnosis. Dynamic videos provide detailed three-dimensional information about the lesion, while static images capture the typical sections of the lesion. In this work, we propose a multi-modality breast tumor diagnosis model to imitate the diagnosing process of radiologists, which learns the features of both static images and dynamic video and explores the potential relationship between the two modalities. Considering that static images are carefully selected by professional radiologists, we propose to aggregate dynamic video features under the guidance of domain knowledge from static images before fusing multi-modality features. Our work is validated on a breast ultrasound dataset composed of 897 sets of ultrasound images and videos. Experimental results show that our model boosts the performance of Benign/Malignant classification, achieving 90.0% in AUC and 81.7% in accuracy.
Interventional Bag Multi-Instance Learning On Whole-Slide Pathological Images
Mar 13, 2023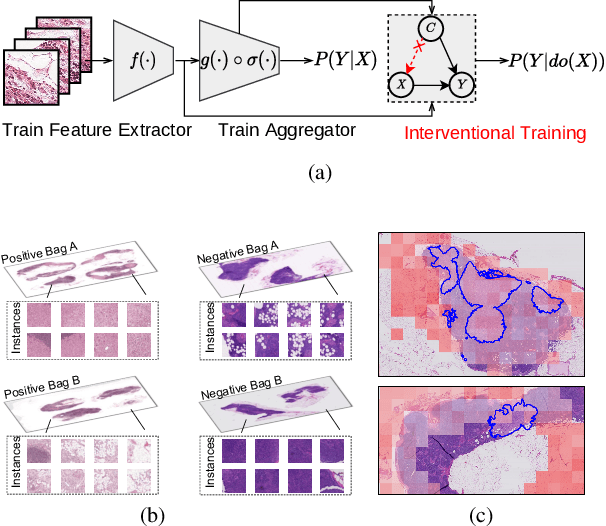
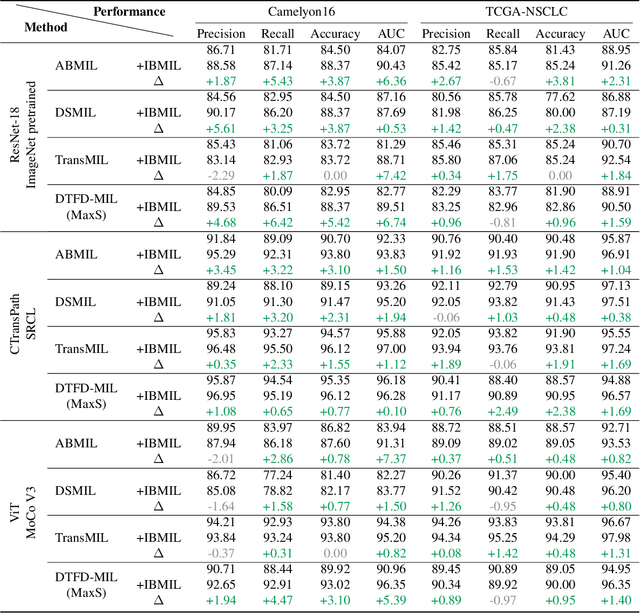
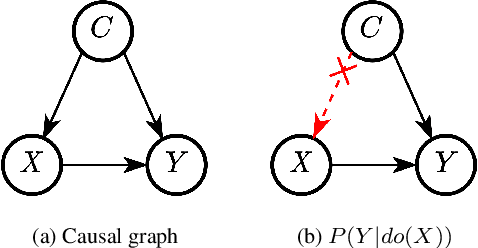
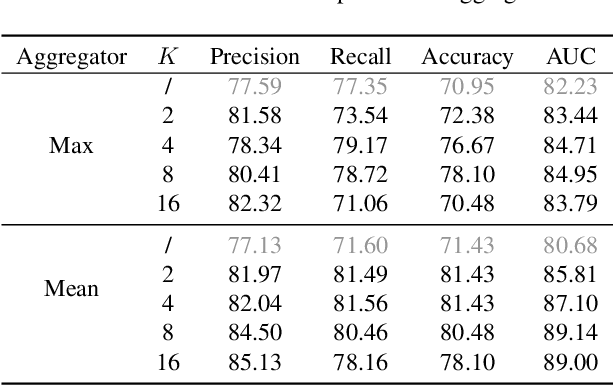
Multi-instance learning (MIL) is an effective paradigm for whole-slide pathological images (WSIs) classification to handle the gigapixel resolution and slide-level label. Prevailing MIL methods primarily focus on improving the feature extractor and aggregator. However, one deficiency of these methods is that the bag contextual prior may trick the model into capturing spurious correlations between bags and labels. This deficiency is a confounder that limits the performance of existing MIL methods. In this paper, we propose a novel scheme, Interventional Bag Multi-Instance Learning (IBMIL), to achieve deconfounded bag-level prediction. Unlike traditional likelihood-based strategies, the proposed scheme is based on the backdoor adjustment to achieve the interventional training, thus is capable of suppressing the bias caused by the bag contextual prior. Note that the principle of IBMIL is orthogonal to existing bag MIL methods. Therefore, IBMIL is able to bring consistent performance boosting to existing schemes, achieving new state-of-the-art performance. Code is available at https://github.com/HHHedo/IBMIL.
Holistic Transformer: A Joint Neural Network for Trajectory Prediction and Decision-Making of Autonomous Vehicles
Jun 17, 2022
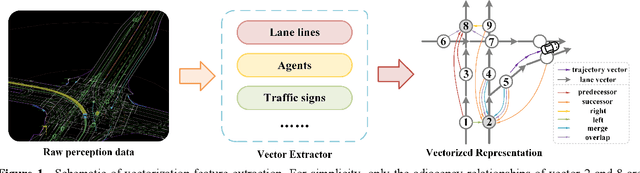

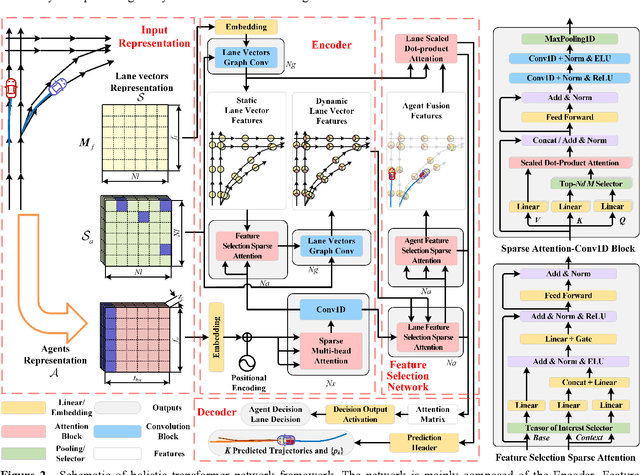
Trajectory prediction and behavioral decision-making are two important tasks for autonomous vehicles that require good understanding of the environmental context; behavioral decisions are better made by referring to the outputs of trajectory predictions. However, most current solutions perform these two tasks separately. Therefore, a joint neural network that combines multiple cues is proposed and named as the holistic transformer to predict trajectories and make behavioral decisions simultaneously. To better explore the intrinsic relationships between cues, the network uses existing knowledge and adopts three kinds of attention mechanisms: the sparse multi-head type for reducing noise impact, feature selection sparse type for optimally using partial prior knowledge, and multi-head with sigmoid activation type for optimally using posteriori knowledge. Compared with other trajectory prediction models, the proposed model has better comprehensive performance and good interpretability. Perceptual noise robustness experiments demonstrate that the proposed model has good noise robustness. Thus, simultaneous trajectory prediction and behavioral decision-making combining multiple cues can reduce computational costs and enhance semantic relationships between scenes and agents.
A translational pathway of deep learning methods in GastroIntestinal Endoscopy
Oct 12, 2020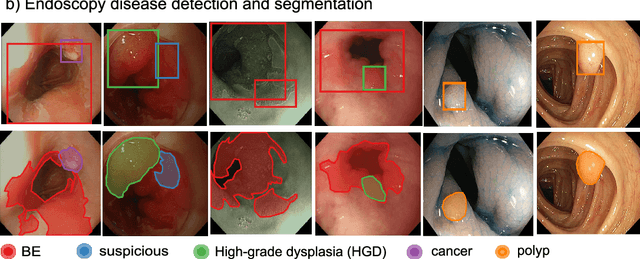
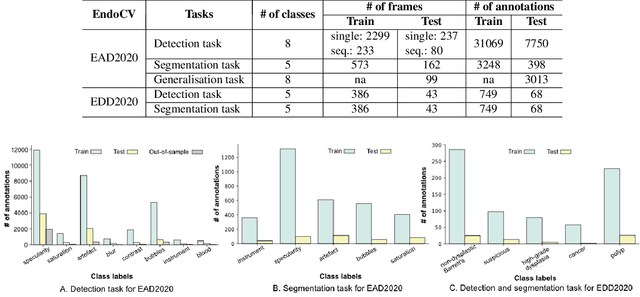
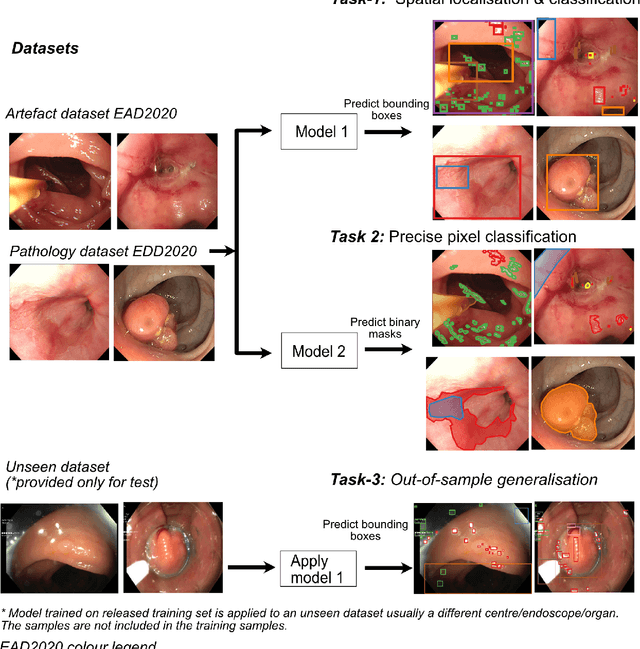
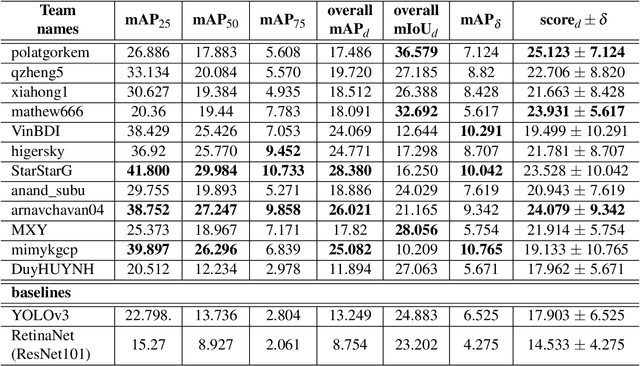
The Endoscopy Computer Vision Challenge (EndoCV) is a crowd-sourcing initiative to address eminent problems in developing reliable computer aided detection and diagnosis endoscopy systems and suggest a pathway for clinical translation of technologies. Whilst endoscopy is a widely used diagnostic and treatment tool for hollow-organs, there are several core challenges often faced by endoscopists, mainly: 1) presence of multi-class artefacts that hinder their visual interpretation, and 2) difficulty in identifying subtle precancerous precursors and cancer abnormalities. Artefacts often affect the robustness of deep learning methods applied to the gastrointestinal tract organs as they can be confused with tissue of interest. EndoCV2020 challenges are designed to address research questions in these remits. In this paper, we present a summary of methods developed by the top 17 teams and provide an objective comparison of state-of-the-art methods and methods designed by the participants for two sub-challenges: i) artefact detection and segmentation (EAD2020), and ii) disease detection and segmentation (EDD2020). Multi-center, multi-organ, multi-class, and multi-modal clinical endoscopy datasets were compiled for both EAD2020 and EDD2020 sub-challenges. An out-of-sample generalisation ability of detection algorithms was also evaluated. Whilst most teams focused on accuracy improvements, only a few methods hold credibility for clinical usability. The best performing teams provided solutions to tackle class imbalance, and variabilities in size, origin, modality and occurrences by exploring data augmentation, data fusion, and optimal class thresholding techniques.