 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Primitive-Sharing Ambiguity in Long-Tailed Industrial Point Cloud Segmentation via Spatial Context Constraints
Jan 27, 2026Industrial point cloud segmentation for Digital Twin construction faces a persistent challenge: safety-critical components such as reducers and valves are systematically misclassified. These failures stem from two compounding factors: such components are rare in training data, yet they share identical local geometry with dominant structures like pipes. This work identifies a dual crisis unique to industrial 3D data extreme class imbalance 215:1 ratio compounded by geometric ambiguity where most tail classes share cylindrical primitives with head classes. Existing frequency-based re-weighting methods address statistical imbalance but cannot resolve geometric ambiguity. We propose spatial context constraints that leverage neighborhood prediction consistency to disambiguate locally similar structures. Our approach extends the Class-Balanced (CB) Loss framework with two architecture-agnostic mechanisms: (1) Boundary-CB, an entropy-based constraint that emphasizes ambiguous boundaries, and (2) Density-CB, a density-based constraint that compensates for scan-dependent variations. Both integrate as plug-and-play modules without network modifications, requiring only loss function replacement. On the Industrial3D dataset (610M points from water treatment facilities), our method achieves 55.74% mIoU with 21.7% relative improvement on tail-class performance (29.59% vs. 24.32% baseline) while preserving head-class accuracy (88.14%). Components with primitive-sharing ambiguity show dramatic gains: reducer improves from 0% to 21.12% IoU; valve improves by 24.3% relative. This resolves geometric ambiguity without the typical head-tail trade-off, enabling reliable identification of safety-critical components for automated knowledge extraction in Digital Twin applications.
A Simple yet Powerful Instance-Aware Prompting Framework for Training-free Camouflaged Object Segmentation
Aug 13, 2025Camouflaged Object Segmentation (COS) remains highly challenging due to the intrinsic visual similarity between target objects and their surroundings. While training-based COS methods achieve good performance, their performance degrades rapidly with increased annotation sparsity. To circumvent this limitation, recent studies have explored training-free COS methods, leveraging the Segment Anything Model (SAM) by automatically generating visual prompts from a single task-generic prompt (\textit{e.g.}, "\textit{camouflaged animal}") uniformly applied across all test images. However, these methods typically produce only semantic-level visual prompts, causing SAM to output coarse semantic masks and thus failing to handle scenarios with multiple discrete camouflaged instances effectively. To address this critical limitation, we propose a simple yet powerful \textbf{I}nstance-\textbf{A}ware \textbf{P}rompting \textbf{F}ramework (IAPF), the first training-free COS pipeline that explicitly converts a task-generic prompt into fine-grained instance masks. Specifically, the IAPF comprises three steps: (1) Text Prompt Generator, utilizing task-generic queries to prompt a Multimodal Large Language Model (MLLM) for generating image-specific foreground and background tags; (2) \textbf{Instance Mask Generator}, leveraging Grounding DINO to produce precise instance-level bounding box prompts, alongside the proposed Single-Foreground Multi-Background Prompting strategy to sample region-constrained point prompts within each box, enabling SAM to yield a candidate instance mask; (3) Self-consistency Instance Mask Voting, which selects the final COS prediction by identifying the candidate mask most consistent across multiple candidate instance masks. Extensive evaluations on standard COS benchmarks demonstrate that the proposed IAPF significantly surpasses existing state-of-the-art training-free COS methods.
Stepwise Decomposition and Dual-stream Focus: A Novel Approach for Training-free Camouflaged Object Segmentation
Jun 07, 2025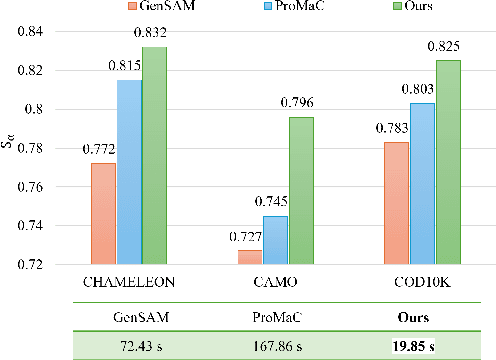
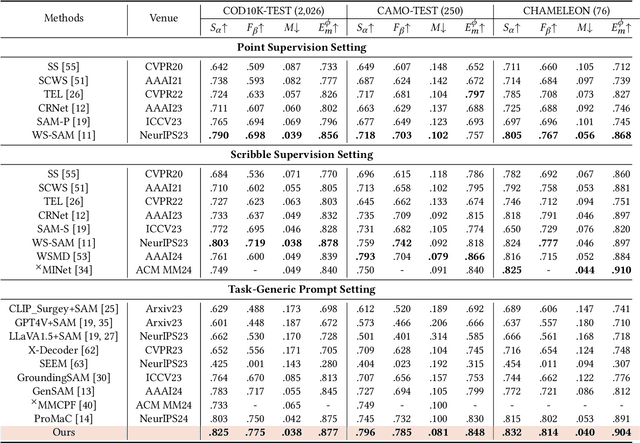
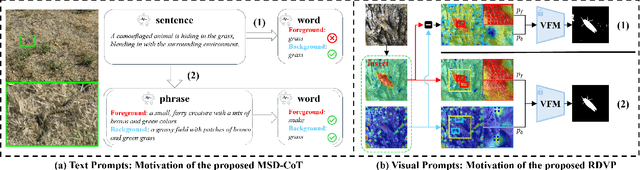
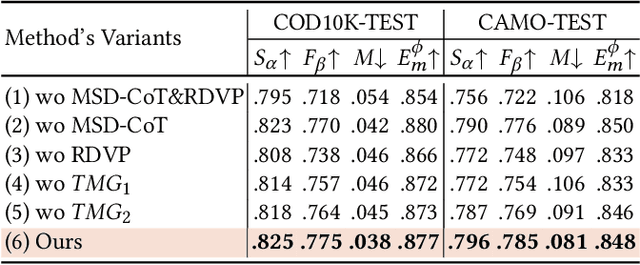
While promptable segmentation (\textit{e.g.}, SAM) has shown promise for various segmentation tasks, it still requires manual visual prompts for each object to be segmented. In contrast, task-generic promptable segmentation aims to reduce the need for such detailed prompts by employing only a task-generic prompt to guide segmentation across all test samples. However, when applied to Camouflaged Object Segmentation (COS), current methods still face two critical issues: 1) \textit{\textbf{semantic ambiguity in getting instance-specific text prompts}}, which arises from insufficient discriminative cues in holistic captions, leading to foreground-background confusion; 2) \textit{\textbf{semantic discrepancy combined with spatial separation in getting instance-specific visual prompts}}, which results from global background sampling far from object boundaries with low feature correlation, causing SAM to segment irrelevant regions. To address the issues above, we propose \textbf{RDVP-MSD}, a novel training-free test-time adaptation framework that synergizes \textbf{R}egion-constrained \textbf{D}ual-stream \textbf{V}isual \textbf{P}rompting (RDVP) via \textbf{M}ultimodal \textbf{S}tepwise \textbf{D}ecomposition Chain of Thought (MSD-CoT). MSD-CoT progressively disentangles image captions to eliminate semantic ambiguity, while RDVP injects spatial constraints into visual prompting and independently samples visual prompts for foreground and background points, effectively mitigating semantic discrepancy and spatial separation. Without requiring any training or supervision, RDVP-MSD achieves a state-of-the-art segmentation result on multiple COS benchmarks and delivers a faster inference speed than previous methods, demonstrating significantly improved accuracy and efficiency. The codes will be available at \href{https://github.com/ycyinchao/RDVP-MSD}{https://github.com/ycyinchao/RDVP-MSD}
A Single-Loop Algorithm for Decentralized Bilevel Optimization
Nov 15, 2023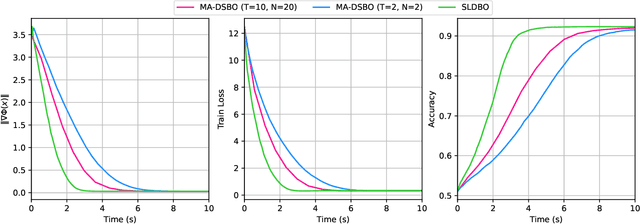
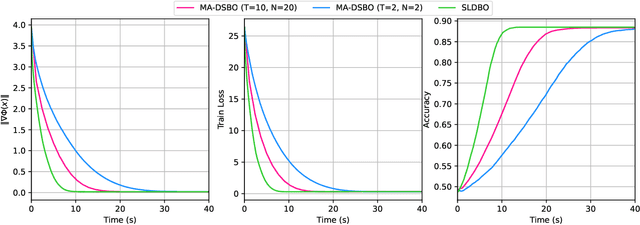
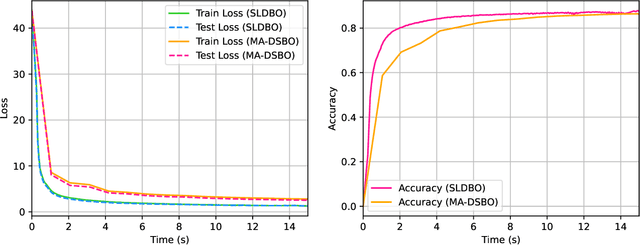
Bilevel optimization has received more and more attention recently due to its wide applications in machine learning. In this paper, we consider bilevel optimization in decentralized networks. In particular, we propose a novel single-loop algorithm for solving decentralized bilevel optimization with strongly convex lower level problem. Our algorithm is fully single-loop and does not require heavy matrix-vector multiplications when approximating the hypergradient. Moreover, unlike existing methods for decentralized bilevel optimization and federated bilevel optimization, our algorithm does not require any gradient heterogeneity assumption. Our analysis shows that the proposed algorithm achieves the best known convergence rate for bilevel optimization algorithms.
Baichuan 2: Open Large-scale Language Models
Sep 20, 2023Large language models (LLMs) have demonstrated remarkable performance on a variety of natural language tasks based on just a few examples of natural language instructions, reducing the need for extensive feature engineering. However, most powerful LLMs are closed-source or limited in their capability for languages other than English. In this technical report, we present Baichuan 2, a series of large-scale multilingual language models containing 7 billion and 13 billion parameters, trained from scratch, on 2.6 trillion tokens. Baichuan 2 matches or outperforms other open-source models of similar size on public benchmarks like MMLU, CMMLU, GSM8K, and HumanEval. Furthermore, Baichuan 2 excels in vertical domains such as medicine and law. We will release all pre-training model checkpoints to benefit the research community in better understanding the training dynamics of Baichuan 2.