 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeal: Advancing Speech Language Models to be Few-Shot Learners
Jul 20, 2024


Existing auto-regressive language models have demonstrated a remarkable capability to perform a new task with just a few examples in prompt, without requiring any additional training. In order to extend this capability to a multi-modal setting (i.e. speech and language), this paper introduces the Seal model, an abbreviation for speech language model. It incorporates a novel alignment method, in which Kullback-Leibler divergence loss is performed to train a projector that bridges a frozen speech encoder with a frozen language model decoder. The resulting Seal model exhibits robust performance as a few-shot learner on two speech understanding tasks. Additionally, consistency experiments are conducted to validate its robustness on different pre-trained language models.
GRASS: Unified Generation Model for Speech-to-Semantic Tasks
Sep 11, 2023


This paper explores the instruction fine-tuning technique for speech-to-semantic tasks by introducing a unified end-to-end (E2E) framework that generates target text conditioned on a task-related prompt for audio data. We pre-train the model using large and diverse data, where instruction-speech pairs are constructed via a text-to-speech (TTS) system. Extensive experiments demonstrate that our proposed model achieves state-of-the-art (SOTA) results on many benchmarks covering speech named entity recognition, speech sentiment analysis, speech question answering, and more, after fine-tuning. Furthermore, the proposed model achieves competitive performance in zero-shot and few-shot scenarios. To facilitate future work on instruction fine-tuning for speech-to-semantic tasks, we release our instruction dataset and code.
Converse, Focus and Guess -- Towards Multi-Document Driven Dialogue
Feb 04, 2021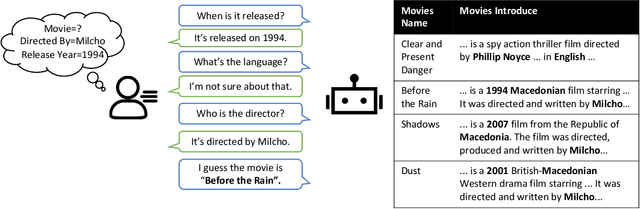


We propose a novel task, Multi-Document Driven Dialogue (MD3), in which an agent can guess the target document that the user is interested in by leading a dialogue. To benchmark progress, we introduce a new dataset of GuessMovie, which contains 16,881 documents, each describing a movie, and associated 13,434 dialogues. Further, we propose the MD3 model. Keeping guessing the target document in mind, it converses with the user conditioned on both document engagement and user feedback. In order to incorporate large-scale external documents into the dialogue, it pretrains a document representation which is sensitive to attributes it talks about an object. Then it tracks dialogue state by detecting evolvement of document belief and attribute belief, and finally optimizes dialogue policy in principle of entropy decreasing and reward increasing, which is expected to successfully guess the user's target in a minimum number of turns. Experiments show that our method significantly outperforms several strong baseline methods and is very close to human's performance.
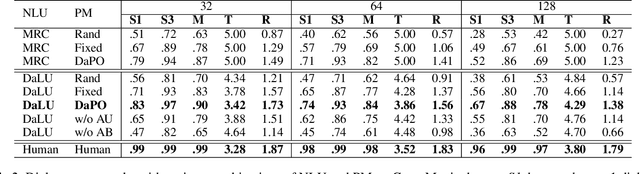
Answer-Driven Visual State Estimator for Goal-Oriented Visual Dialogue
Oct 01, 2020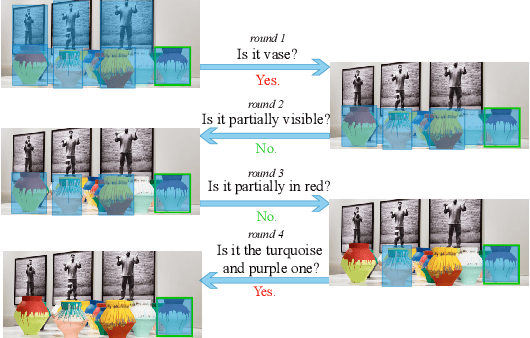
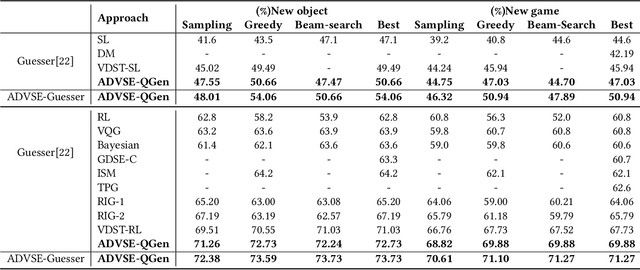
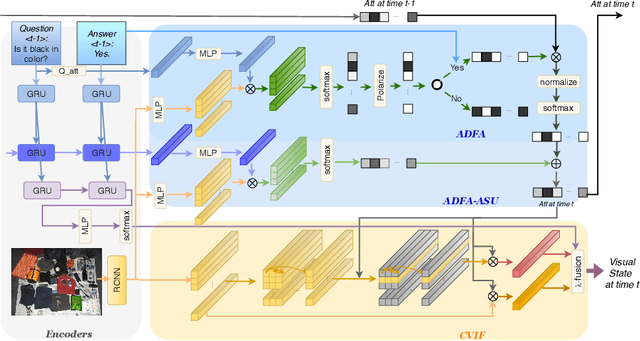
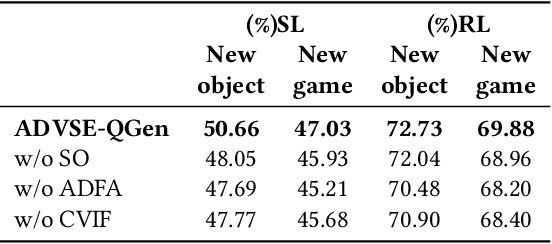
A goal-oriented visual dialogue involves multi-turn interactions between two agents, Questioner and Oracle. During which, the answer given by Oracle is of great significance, as it provides golden response to what Questioner concerns. Based on the answer, Questioner updates its belief on target visual content and further raises another question. Notably, different answers drive into different visual beliefs and future questions. However, existing methods always indiscriminately encode answers after much longer questions, resulting in a weak utilization of answers. In this paper, we propose an Answer-Driven Visual State Estimator (ADVSE) to impose the effects of different answers on visual states. First, we propose an Answer-Driven Focusing Attention (ADFA) to capture the answer-driven effect on visual attention by sharpening question-related attention and adjusting it by answer-based logical operation at each turn. Then based on the focusing attention, we get the visual state estimation by Conditional Visual Information Fusion (CVIF), where overall information and difference information are fused conditioning on the question-answer state. We evaluate the proposed ADVSE to both question generator and guesser tasks on the large-scale GuessWhat?! dataset and achieve the state-of-the-art performances on both tasks. The qualitative results indicate that the ADVSE boosts the agent to generate highly efficient questions and obtains reliable visual attentions during the reasonable question generation and guess processes.