 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAS-Speech: Adaptive Style For Speech Synthesis
Sep 09, 2024



In recent years, there has been significant progress in Text-to-Speech (TTS) synthesis technology, enabling the high-quality synthesis of voices in common scenarios. In unseen situations, adaptive TTS requires a strong generalization capability to speaker style characteristics. However, the existing adaptive methods can only extract and integrate coarse-grained timbre or mixed rhythm attributes separately. In this paper, we propose AS-Speech, an adaptive style methodology that integrates the speaker timbre characteristics and rhythmic attributes into a unified framework for text-to-speech synthesis. Specifically, AS-Speech can accurately simulate style characteristics through fine-grained text-based timbre features and global rhythm information, and achieve high-fidelity speech synthesis through the diffusion model. Experiments show that the proposed model produces voices with higher naturalness and similarity in terms of timbre and rhythm compared to a series of adaptive TTS models.
Multi-speaker Multi-style Text-to-speech Synthesis With Single-speaker Single-style Training Data Scenarios
Dec 23, 2021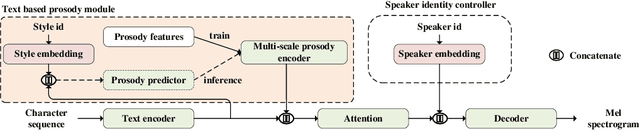

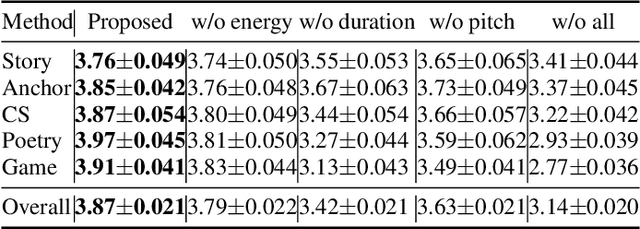
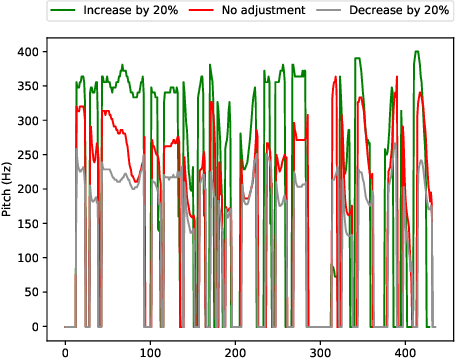
In the existing cross-speaker style transfer task, a source speaker with multi-style recordings is necessary to provide the style for a target speaker. However, it is hard for one speaker to express all expected styles. In this paper, a more general task, which is to produce expressive speech by combining any styles and timbres from a multi-speaker corpus in which each speaker has a unique style, is proposed. To realize this task, a novel method is proposed. This method is a Tacotron2-based framework but with a fine-grained text-based prosody predicting module and a speaker identity controller. Experiments demonstrate that the proposed method can successfully express a style of one speaker with the timber of another speaker bypassing the dependency on a single speaker's multi-style corpus. Moreover, the explicit prosody features used in the prosody predicting module can increase the diversity of synthetic speech by adjusting the value of prosody features.