 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
MSR-86K: An Evolving, Multilingual Corpus with 86,300 Hours of Transcribed Audio for Speech Recognition Research
Jun 26, 2024
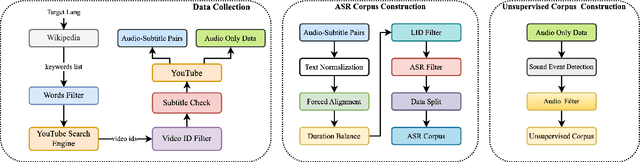


Recently, multilingual artificial intelligence assistants, exemplified by ChatGPT, have gained immense popularity. As a crucial gateway to human-computer interaction, multilingual automatic speech recognition (ASR) has also garnered significant attention, as evidenced by systems like Whisper. However, the proprietary nature of the training data has impeded researchers' efforts to study multilingual ASR. This paper introduces MSR-86K, an evolving, large-scale multilingual corpus for speech recognition research. The corpus is derived from publicly accessible videos on YouTube, comprising 15 languages and a total of 86,300 hours of transcribed ASR data. We also introduce how to use the MSR-86K corpus and other open-source corpora to train a robust multilingual ASR model that is competitive with Whisper. MSR-86K will be publicly released on HuggingFace, and we believe that such a large corpus will pave new avenues for research in multilingual ASR.
Enhancing Multilingual Speech Recognition through Language Prompt Tuning and Frame-Level Language Adapter
Sep 19, 2023
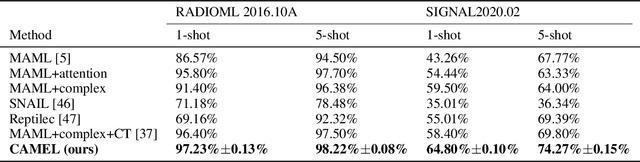

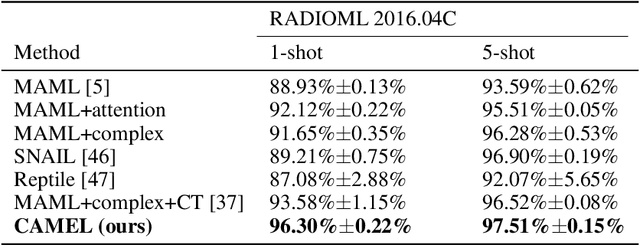
Multilingual intelligent assistants, such as ChatGPT, have recently gained popularity. To further expand the applications of multilingual artificial intelligence assistants and facilitate international communication, it is essential to enhance the performance of multilingual speech recognition, which is a crucial component of speech interaction. In this paper, we propose two simple and parameter-efficient methods: language prompt tuning and frame-level language adapter, to respectively enhance language-configurable and language-agnostic multilingual speech recognition. Additionally, we explore the feasibility of integrating these two approaches using parameter-efficient fine-tuning methods. Our experiments demonstrate significant performance improvements across seven languages using our proposed methods.