 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint-stochastic-approximation Random Fields with Application to Semi-supervised Learning
May 24, 2025



Our examination of deep generative models (DGMs) developed for semi-supervised learning (SSL), mainly GANs and VAEs, reveals two problems. First, mode missing and mode covering phenomenons are observed in genertion with GANs and VAEs. Second, there exists an awkward conflict between good classification and good generation in SSL by employing directed generative models. To address these problems, we formally present joint-stochastic-approximation random fields (JRFs) -- a new family of algorithms for building deep undirected generative models, with application to SSL. It is found through synthetic experiments that JRFs work well in balancing mode covering and mode missing, and match the empirical data distribution well. Empirically, JRFs achieve good classification results comparable to the state-of-art methods on widely adopted datasets -- MNIST, SVHN, and CIFAR-10 in SSL, and simultaneously perform good generation.
An empirical study of domain-agnostic semi-supervised learning via energy-based models: joint-training and pre-training
Oct 25, 2020
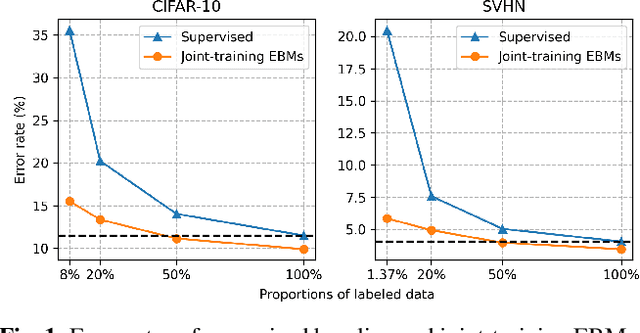

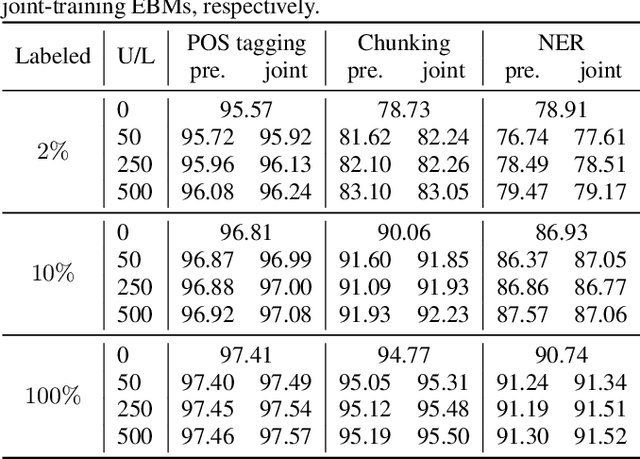
A class of recent semi-supervised learning (SSL) methods heavily rely on domain-specific data augmentations. In contrast, generative SSL methods involve unsupervised learning based on generative models by either joint-training or pre-training, and are more appealing from the perspective of being domain-agnostic, since they do not inherently require data augmentations. Joint-training estimates the joint distribution of observations and labels, while pre-training is taken over observations only. Recently, energy-based models (EBMs) have achieved promising results for generative modeling. Joint-training via EBMs for SSL has been explored with encouraging results across different data modalities. In this paper, we make two contributions. First, we explore pre-training via EBMs for SSL and compare it to joint-training. Second, a suite of experiments are conducted over domains of image classification and natural language labeling to give a realistic whole picture of the performances of EBM based SSL methods. It is found that joint-training EBMs outperform pre-training EBMs marginally but nearly consistently.
Joint Stochastic Approximation and Its Application to Learning Discrete Latent Variable Models
May 28, 2020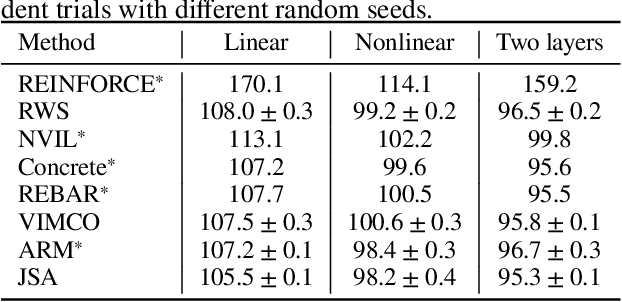
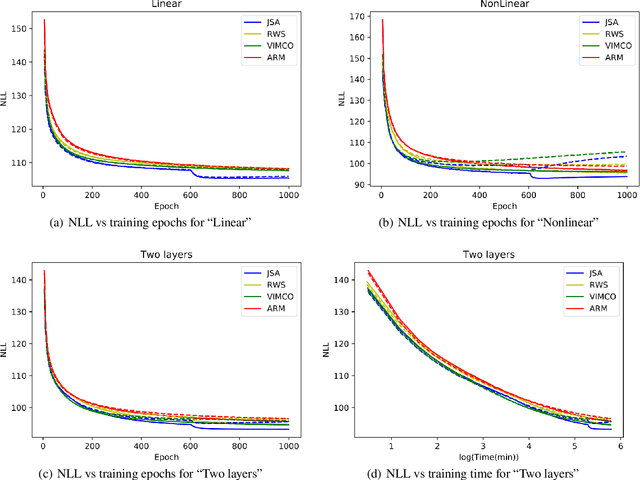
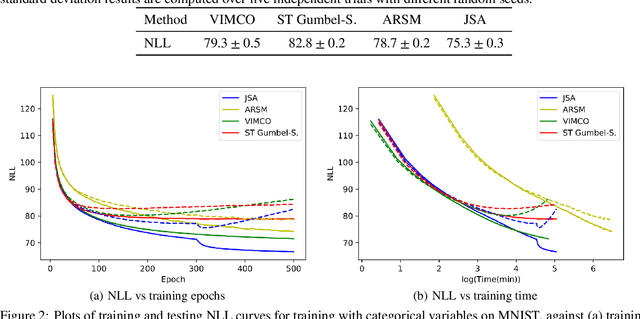
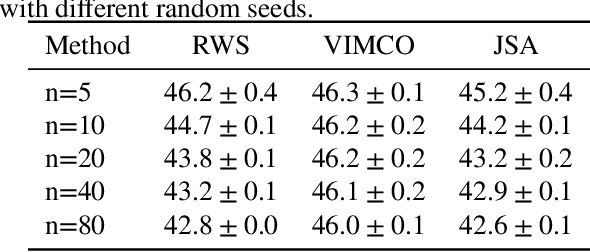
Although with progress in introducing auxiliary amortized inference models, learning discrete latent variable models is still challenging. In this paper, we show that the annoying difficulty of obtaining reliable stochastic gradients for the inference model and the drawback of indirectly optimizing the target log-likelihood can be gracefully addressed in a new method based on stochastic approximation (SA) theory of the Robbins-Monro type. Specifically, we propose to directly maximize the target log-likelihood and simultaneously minimize the inclusive divergence between the posterior and the inference model. The resulting learning algorithm is called joint SA (JSA). To the best of our knowledge, JSA represents the first method that couples an SA version of the EM (expectation-maximization) algorithm (SAEM) with an adaptive MCMC procedure. Experiments on several benchmark generative modeling and structured prediction tasks show that JSA consistently outperforms recent competitive algorithms, with faster convergence, better final likelihoods, and lower variance of gradient estimates.
Learning Neural Random Fields with Inclusive Auxiliary Generators
Sep 28, 2018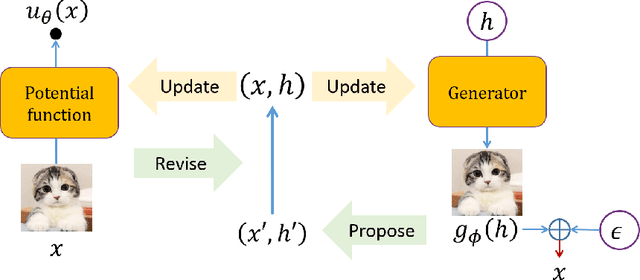
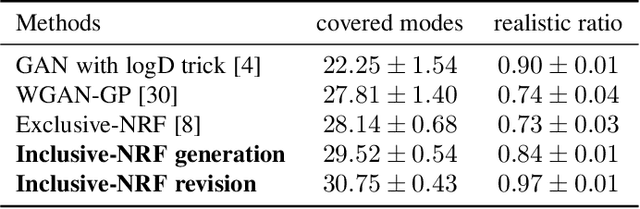
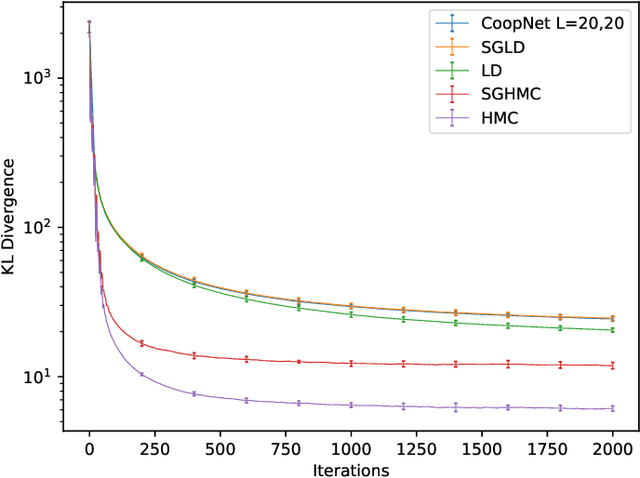
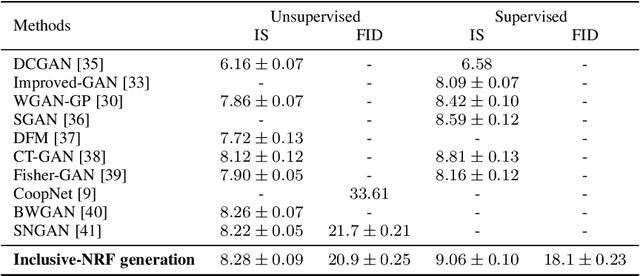
Neural random fields (NRFs), which are defined by using neural networks to implement potential functions in undirected models, provide an interesting family of model spaces for machine learning. In this paper we develop a new approach to learning NRFs with inclusive-divergence minimized auxiliary generator - the inclusive-NRF approach. The new approach enables us to flexibly use NRFs in unsupervised, supervised and semi-supervised settings and successfully train them in a black-box manner. Empirically, inclusive-NRFs achieve state-of-the-art sample generation quality on CIFAR-10 in both unsupervised and supervised settings. Semi-supervised inclusive-NRFs show strong classification results on par with state-of-the-art generative model based semi-supervised learning methods, and simultaneously achieve superior generation, on the widely benchmarked datasets - MNIST, SVHN and CIFAR-10.