 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL2Calib: $SE(3)$-Manifold Reinforcement Learning for Robust Extrinsic Calibration with Degenerate Motion Resilience
Aug 08, 2025Extrinsic calibration is essential for multi-sensor fusion, existing methods rely on structured targets or fully-excited data, limiting real-world applicability. Online calibration further suffers from weak excitation, leading to unreliable estimates. To address these limitations, we propose a reinforcement learning (RL)-based extrinsic calibration framework that formulates extrinsic calibration as a decision-making problem, directly optimizes $SE(3)$ extrinsics to enhance odometry accuracy. Our approach leverages a probabilistic Bingham distribution to model 3D rotations, ensuring stable optimization while inherently retaining quaternion symmetry. A trajectory alignment reward mechanism enables robust calibration without structured targets by quantitatively evaluating estimated tightly-coupled trajectory against a reference trajectory. Additionally, an automated data selection module filters uninformative samples, significantly improving efficiency and scalability for large-scale datasets. Extensive experiments on UAVs, UGVs, and handheld platforms demonstrate that our method outperforms traditional optimization-based approaches, achieving high-precision calibration even under weak excitation conditions. Our framework simplifies deployment on diverse robotic platforms by eliminating the need for high-quality initial extrinsics and enabling calibration from routine operating data. The code is available at https://github.com/APRIL-ZJU/learn-to-calibrate.
NeAS: 3D Reconstruction from X-ray Images using Neural Attenuation Surface
Mar 10, 2025Reconstructing three-dimensional (3D) structures from two-dimensional (2D) X-ray images is a valuable and efficient technique in medical applications that requires less radiation exposure than computed tomography scans. Recent approaches that use implicit neural representations have enabled the synthesis of novel views from sparse X-ray images. However, although image synthesis has improved the accuracy, the accuracy of surface shape estimation remains insufficient. Therefore, we propose a novel approach for reconstructing 3D scenes using a Neural Attenuation Surface (NeAS) that simultaneously captures the surface geometry and attenuation coefficient fields. NeAS incorporates a signed distance function (SDF), which defines the attenuation field and aids in extracting the 3D surface within the scene. We conducted experiments using simulated and authentic X-ray images, and the results demonstrated that NeAS could accurately extract 3D surfaces within a scene using only 2D X-ray images.
AutoDFP: Automatic Data-Free Pruning via Channel Similarity Reconstruction
Mar 13, 2024



Structured pruning methods are developed to bridge the gap between the massive scale of neural networks and the limited hardware resources. Most current structured pruning methods rely on training datasets to fine-tune the compressed model, resulting in high computational burdens and being inapplicable for scenarios with stringent requirements on privacy and security. As an alternative, some data-free methods have been proposed, however, these methods often require handcraft parameter tuning and can only achieve inflexible reconstruction. In this paper, we propose the Automatic Data-Free Pruning (AutoDFP) method that achieves automatic pruning and reconstruction without fine-tuning. Our approach is based on the assumption that the loss of information can be partially compensated by retaining focused information from similar channels. Specifically, We formulate data-free pruning as an optimization problem, which can be effectively addressed through reinforcement learning. AutoDFP assesses the similarity of channels for each layer and provides this information to the reinforcement learning agent, guiding the pruning and reconstruction process of the network. We evaluate AutoDFP with multiple networks on multiple datasets, achieving impressive compression results. For instance, on the CIFAR-10 dataset, AutoDFP demonstrates a 2.87\% reduction in accuracy loss compared to the recently proposed data-free pruning method DFPC with fewer FLOPs on VGG-16. Furthermore, on the ImageNet dataset, AutoDFP achieves 43.17\% higher accuracy than the SOTA method with the same 80\% preserved ratio on MobileNet-V1.
Multilingual and crosslingual speech recognition using phonological-vector based phone embeddings
Jul 11, 2021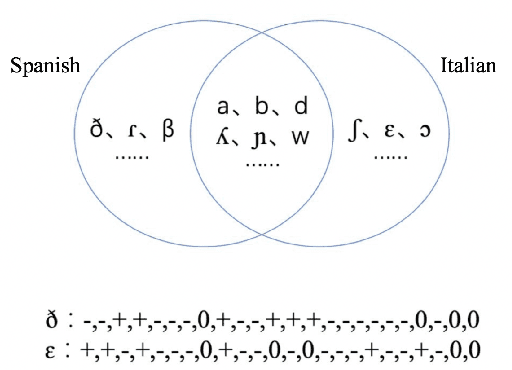
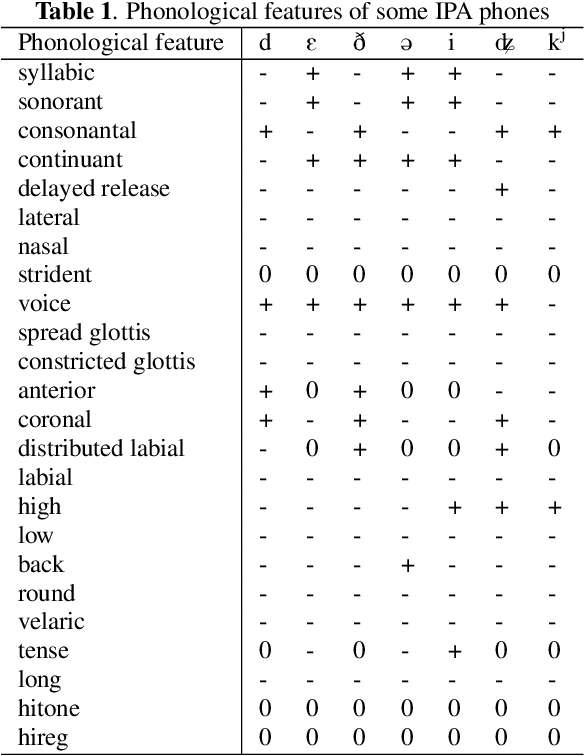
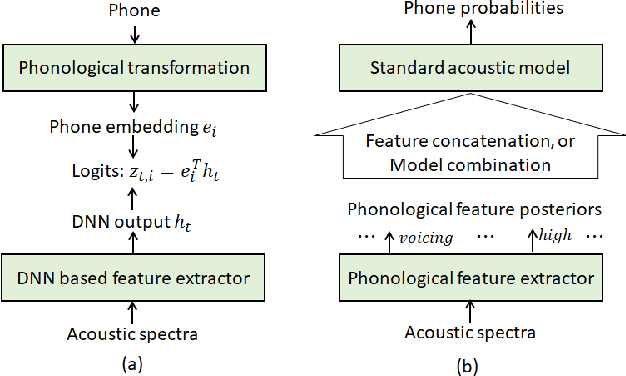
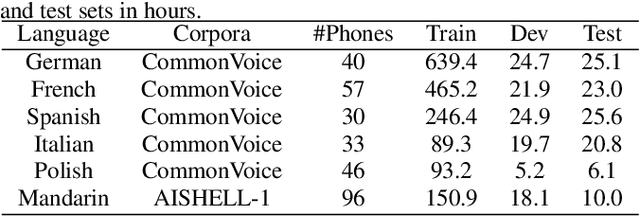
The use of phonological features (PFs) potentially allows language-specific phones to remain linked in training, which is highly desirable for information sharing for multilingual and crosslingual speech recognition methods for low-resourced languages. A drawback suffered by previous methods in using phonological features is that the acoustic-to-PF extraction in a bottom-up way is itself difficult. In this paper, we propose to join phonology driven phone embedding (top-down) and deep neural network (DNN) based acoustic feature extraction (bottom-up) to calculate phone probabilities. The new method is called JoinAP (Joining of Acoustics and Phonology). Remarkably, no inversion from acoustics to phonological features is required for speech recognition. For each phone in the IPA (International Phonetic Alphabet) table, we encode its phonological features to a phonological-vector, and then apply linear or nonlinear transformation of the phonological-vector to obtain the phone embedding. A series of multilingual and crosslingual (both zero-shot and few-shot) speech recognition experiments are conducted on the CommonVoice dataset (German, French, Spanish and Italian) and the AISHLL-1 dataset (Mandarin), and demonstrate the superiority of JoinAP with nonlinear phone embeddings over both JoinAP with linear phone embeddings and the traditional method with flat phone embeddings.